
.png)

_logo%201.svg)


AI Summary
The ability to swiftly and accurately extract information from documents is critical for many businesses. This is especially true in industries where processing vast documents, such as IDs, claims forms, police reports, and medical records, is a daily task. Extracting relevant data, such as personal details, incident information, and policy numbers, holds significant business value. It promises greater operational efficiency, substantial cost savings by minimizing manual data entry and verification efforts, faster resolution of claims, and improved decision-making.
However, even with the advancements in artificial intelligence, the path to harnessing this potential is fraught with challenges. In this article, we will tackle the challenges of information extraction and the solutions that a data labeling platform like Kili Technology can provide.
What is key information extraction?
Key Information Extraction (KIE) plays a pivotal role in automatically pinpointing and harvesting crucial data from unstructured or semi-structured documents. This advanced process is indispensable across various sectors, including legal, healthcare, insurance, and finance, facilitating the swift and precise extraction of vital details such as personal information, dates, financial amounts, and specific legal clauses. KIE is instrumental in converting raw, unstructured text into organized, structured information, enhancing operational efficiency and decision-making.
By transforming extracted text into structured data, KIE enables more efficient data management, searchability, and analysis, improving insights and automating tasks traditionally performed manually.
The first step: Optical character recognition

Optical Character Recognition (OCR) is a cornerstone technology in KIE, especially when dealing with printed, handwritten, or scanned documents. OCR technology transforms images of text into machine-encoded text, converting image-based documents into an editable format that can be quickly processed and analyzed by computers.
In the context of KIE, OCR is the initial step toward digitizing documents, rendering the textual content accessible for subsequent analysis and extracting specific, structured information. Without OCR, the automation of data extraction from physical documents or image-based PDFs would be challenging, as the software designed for information extraction would not directly read the text contained within these documents.
Named Entity Recognition

Named Entity Recognition (NER) is a critical sub-task within text classification, focusing on identifying and categorizing key components in text into predefined groups such as names of individuals, organizations, locations, time expressions, quantities, monetary values, and percentages.
In the context of KIE, NER is essential for pinpointing data pertinent to specific tasks. For example, in legal documents, NER facilitates the identification and categorization of named entities, such as party names, locations, and dates, enhancing the extraction of relevant information and the organization of this extracted text. This process assists in extracting vital information and structuring and organizing the extracted data, preparing it for further analysis or integration into databases and applications.
OCR, NER, and the comprehensive process of KIE are fundamental to document analysis, transforming unstructured or semi-structured document content into structured, actionable data. For more insights, explore our comprehensive guide on document layout analysis, featuring advanced techniques in sentiment analysis, feature extraction, and identifying named entities within structured information.
Challenges of KIE
Extracting key information from text and documents is complex and challenging, not just due to the scale and variety of documents that need to be labeled but also due to the inherent nature of language, where nuance and meaning may vary depending on context.
The high data variability and complexity in terms of format (native PDF, scanned files) and type (legal documents, IDs, reports, and other documents), the sheer volume of files to label, and the imperative to comply with regulatory standards make information extraction daunting. Furthermore, integrating the extracted data with existing databases or management systems adds another layer of complexity. These challenges often result in bottlenecks that impede building effective training data, developing high-performing machine learning algorithms, and inflating processing times and costs.
Let's go through each of them and discover how each challenge can be solved:
High Variability and Complexity of Documents
Documents can vary greatly in format, structure, and content. For instance, claims forms, medical records, and police reports might differ not only from one organization to another but also within the same institution over time. The complexity can also stem from the mix of text, images, and handwritten notes, as well as the use of specialized jargon or abbreviations that are domain-specific. This variability and complexity make it difficult to design a one-size-fits-all solution for information extraction.
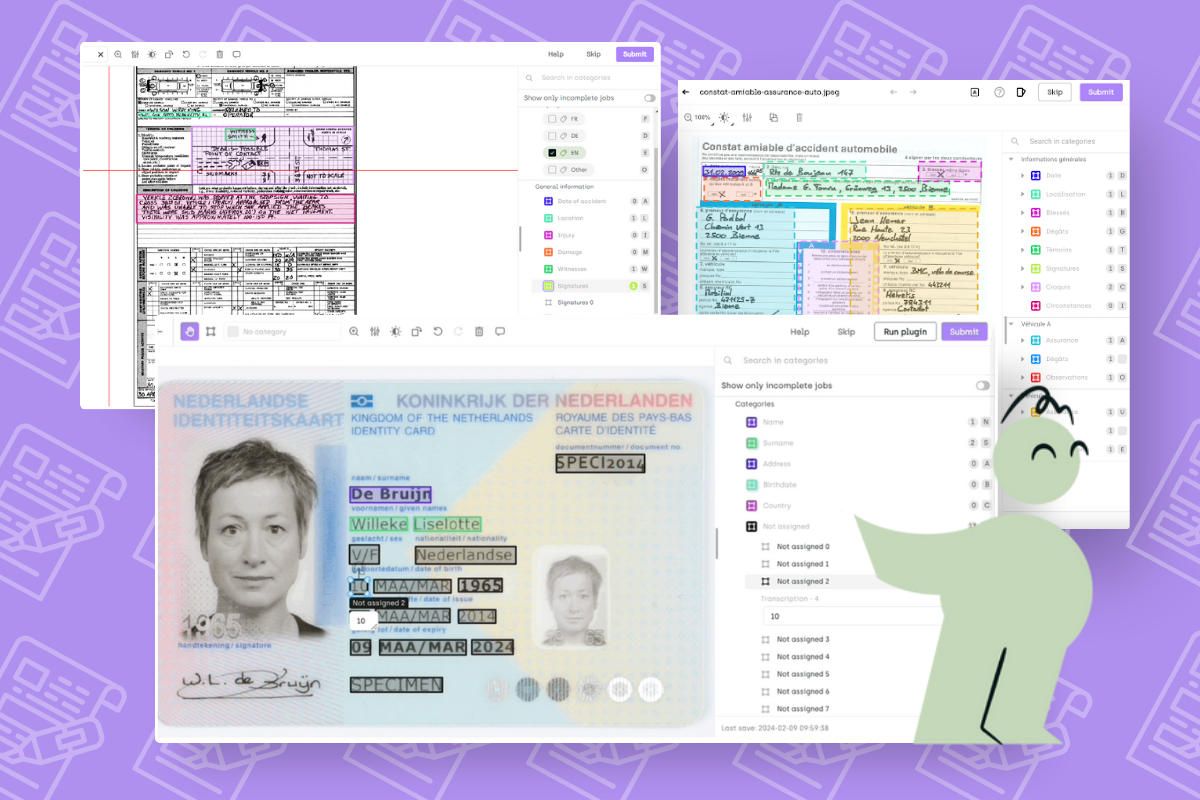
However, Kili can handle various document types with varying degrees of complexity. Additionally, it's designed to be user-friendly for human annotators with highly flexible annotation tools. This ensures that documents with complex structures, nested information, or implicit relationships can be tagged quickly and easily.
Volume of documents to label
Many organizations face the task of processing a large volume of documents regularly. This is especially true for insurance, healthcare, and finance industries, where thousands to millions of claims and reports must be handled efficiently. The sheer volume of documents exacerbates the issues of variability and complexity. Processing a high volume of documents manually is time-consuming, costly, and prone to errors.
To tackle this, Kili's platform is built to scale, enabling it to efficiently process large volumes of documents. Through the use of Optical Character Recognition (OCR) and Kili’s Information Extraction interface, the solution ensures high accuracy in data extraction. The process involves loading OCR outputs as pre-annotations, efficiently assigning correct classes to each bounding box, and adapting transcription text as necessary.

Step 1: Load OCR outputs as pre-annotations
Step 2: Easy transcription of information where annotators need only to validate
Ambiguity of natural language
Natural language is highly variable and context-dependent. The same word or phrase can have different meanings in different contexts, and people use many ways to express the same idea. Texts often contain ambiguities that humans can resolve using their world knowledge or the broader context, which machines struggle to understand.
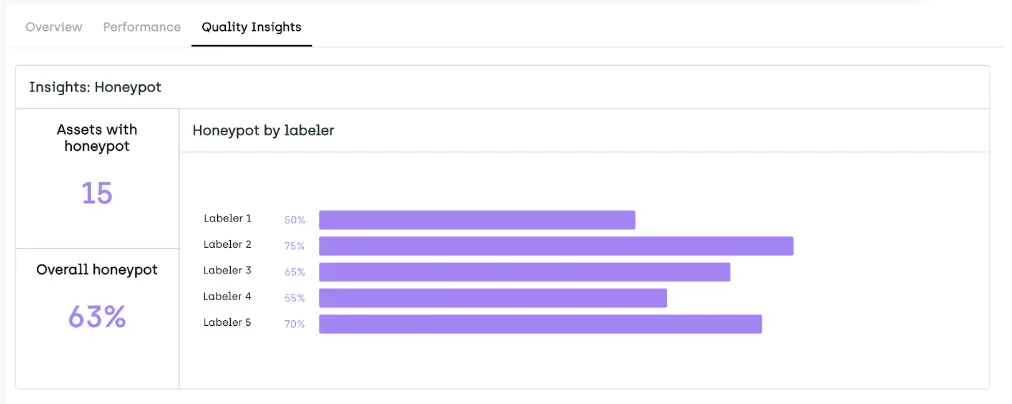
When dealing with ambiguity in key information extraction (KIE), consensus and establishing a gold standard are efficient and often necessary solutions to ensure high-quality data labeling and model training.
Use Consensus and Honeypot to deal with ambiguous language that can be found in complex texts and documents.
.webp)
Compliance with regulatory standards
Compliance involves adhering to laws, regulations, and standards that govern how data, especially personal and sensitive information, is handled, stored, and processed. This includes regulations like GDPR in Europe, HIPAA in the United States for healthcare data, and other global data protection laws. Ensuring compliance requires systems to accurately identify, extract, and handle sensitive information in a way that meets legal standards.
Kili’s platform is built with compliance at its core, offering robust data handling and privacy features. It ensures that the entire data extraction process, from document upload to data annotation, adheres to the highest data security and privacy standards.
Businesses can rest assured that their operations fully comply with regulatory requirements, safeguarding against legal risks and enhancing customer trust through secure data practices.
Integrating extracted data with existing systems
Once data is extracted, it must often be integrated into existing databases or management systems. This integration is crucial for the data to be valuable in decision-making processes, analytics, and operational workflows.
Integration challenges stem from the need to match the extracted data with the schemas and formats of existing systems. This often requires custom integration efforts, especially if the systems were not designed with interoperability in mind. Additionally, ensuring the integrity and quality of the integrated data is paramount, as inaccuracies or inconsistencies can lead to errors downstream in decision-making processes or analytics.
Kili Technology excels in creating a highly adaptable platform that integrates effortlessly with existing systems. Its solution is designed to ensure that data, once extracted, can be easily fed into various databases and management systems without disrupting existing workflows.
KIE in practice
KIE models have been adapted across sectors thanks to their transformative effects - enhancing operational efficiencies and playing a crucial role in strategic decision-making and regulatory compliance:
- Banking: Automates customer data extraction from identification documents, streamlining Know Your Customer (KYC) processes and ensuring adherence to global compliance standards. Check out how one bank does it here.
- Insurance: Transforms claim processing by utilizing KIE for rapid classification and extraction of information from claim documents, reducing processing times from weeks to minutes and enhancing customer satisfaction. Here’s how a global insurance company does it.
- Healthcare: Improves patient care and administrative efficiency by extracting vital patient information from medical records, aiding in accurate diagnosis and treatment planning, and reducing manual data entry errors.
- Customer Service: Enhances service quality by analyzing customer feedback and inquiries through KIE, enabling businesses to identify trends, anticipate customer needs, and tailor their products and services accordingly.
- Legal: Streamlines legal research and case preparation by extracting relevant information from legal documents, reducing the time spent on manual document review, and allowing legal professionals to focus on case strategy and client needs.
By automating the extraction and analysis of critical information from various document types, KIE technologies empower industries to achieve greater efficiency, accuracy, and customer insight, driving innovation and competitive advantage in the digital age.
Ship information extraction models faster
From banking and insurance to healthcare and legal, the ability to accurately and swiftly extract key data from documents is revolutionizing operational efficiencies, compliance adherence, and decision-making processes. If your organization seeks to harness the power of KIE to navigate the complexities of document processing and unlock significant business value, exploring a tailored solution is the next step.
We invite you to book a demo and discover how a sophisticated data labeling platform can empower your business to overcome the challenges of information extraction and leverage the full potential of your data.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
