
.png)


_logo%201.svg)


AI Summary
What is Text Annotation in Machine Learning?
Simply put, text annotation in machine learning (ML) is the process of assigning labels to a digital file or document and its content. Labeling a text can consist in assigning tags to text attributes such as keywords, sentences, and paragraphs or simply classifying the text based on its content (i.e. text classification).
These include various NLP technologies like neural machine translation (NMT) programs, auto Q&A (question and answer) platforms, smart chatbots, sentiment analysis, text-to-speech synthesizers, and auto speech recognition (ASR) tools, among other related projects. These technologies can streamline the activities and transactions of many organizations across different industries.
If you want to learn more about the history of NLP in computer science, you can read our article here.
What are the different types of text annotations?
Text / Document classification
Text and document classification consists in attributing one or multiple attributes to a single text or full document.
Examples:
- 1. Classifying emails as spam or regular emails
- 2. Doing sentiment analysis on tweets
- 3. Labeling legal documents based on their content (legal notices, agreements, bonds, …)

Example of sentiment analysis on an amazon review
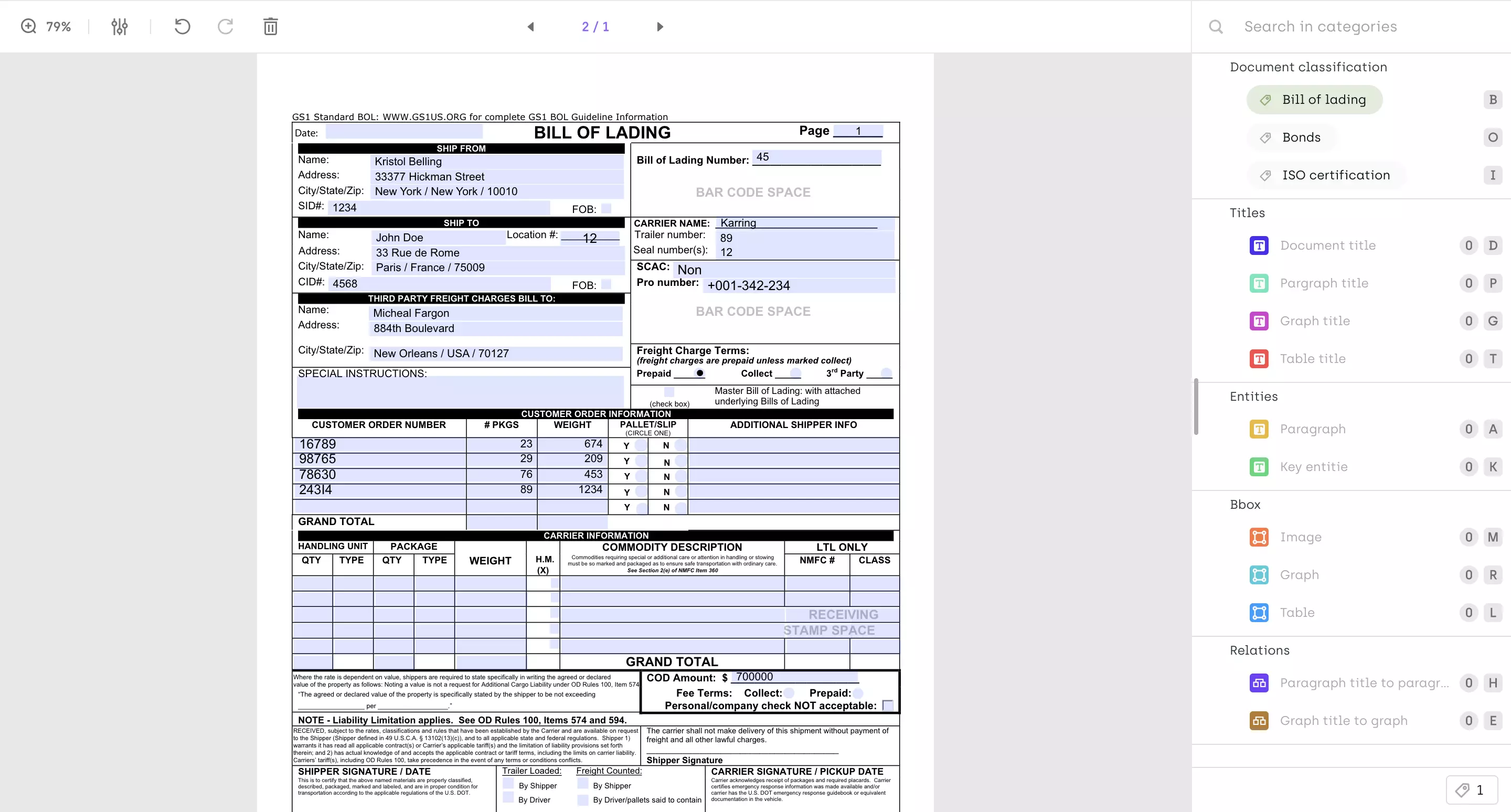
Bill of lading being classified
Named entity recognition
At a high level, named entity recognition is the action of identifying named entities within a text and assigning it a predefined category. Common categories that are used for this type of text annotation include names of organizations, locations, persons, numerical values, month or time and day of the week, etc. But depending on the type of NER performed, categories such as paragraph, title, and content can also be used.
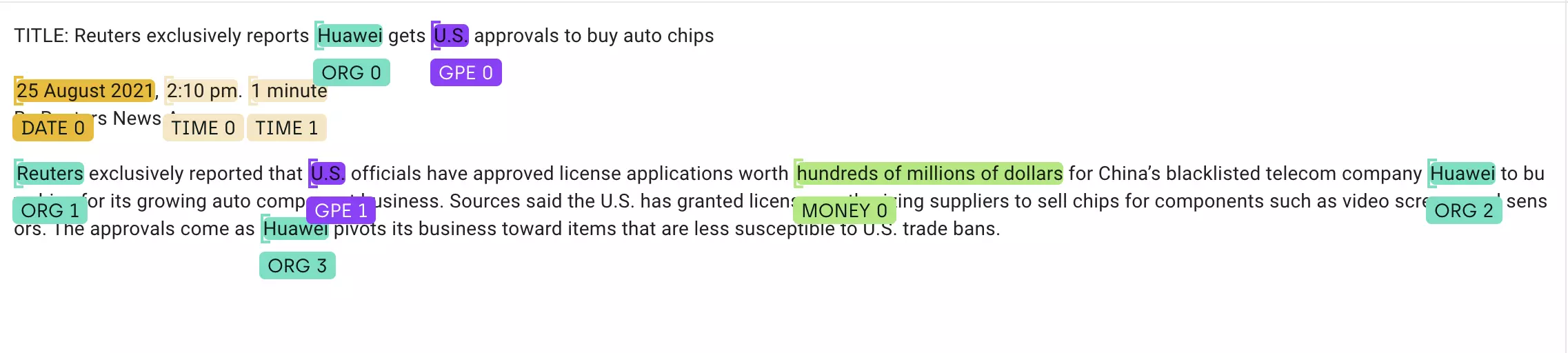
NER performed on a short article from Reuters
Entity linking
This is the process for linking entities to better understand the structure of the text and the relationships between entities. Here you can see a table being extracted from a scanned invoice and item lines being linked together to preserve its structure.
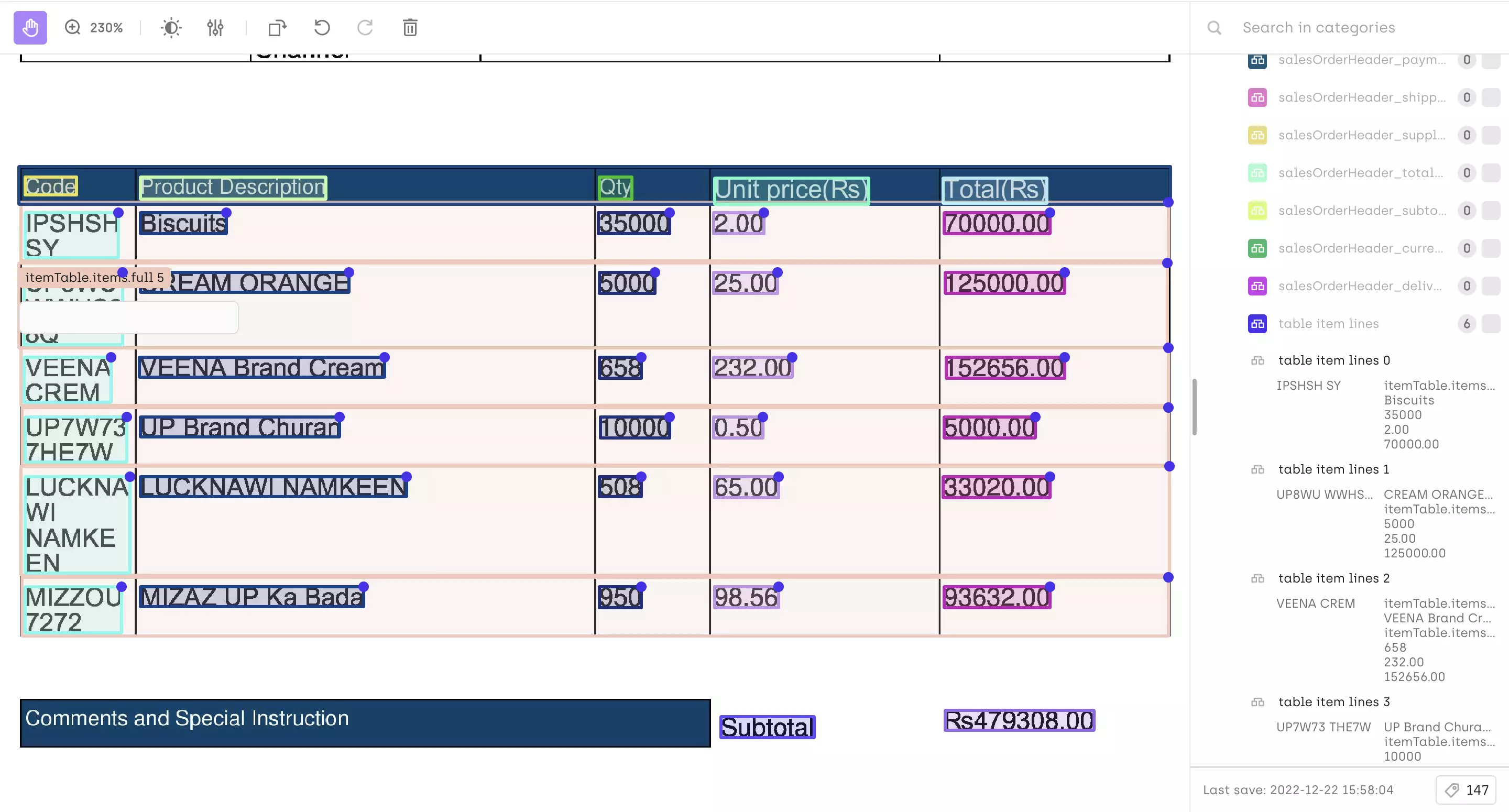
A table being extracted from scanned document

A table being extracted from scanned document
Layout analysis
Layout analysis consists of labeling document structures to transform them into another format (ex: JSON).

Layout analysis consists of labeling document structures to transform them into another format (ex: JSON).
How to label texts, PDFs, and Images?
In real life, textual data exists under a wide range of different formats txt, pdf or even text in images or scanned documents. In this part are going to dive deep into the specificities of those data formats and what features are mandatory to label efficiently.
Labeling text data
When labeling text data in simple txt format, the following features are important:
Multilingual Support
When labeling textual data, language and tokenization are key to consider. The labeling tool used must allow the labeling of all languages. Using Kili, you can natively label any language using our interfaces.
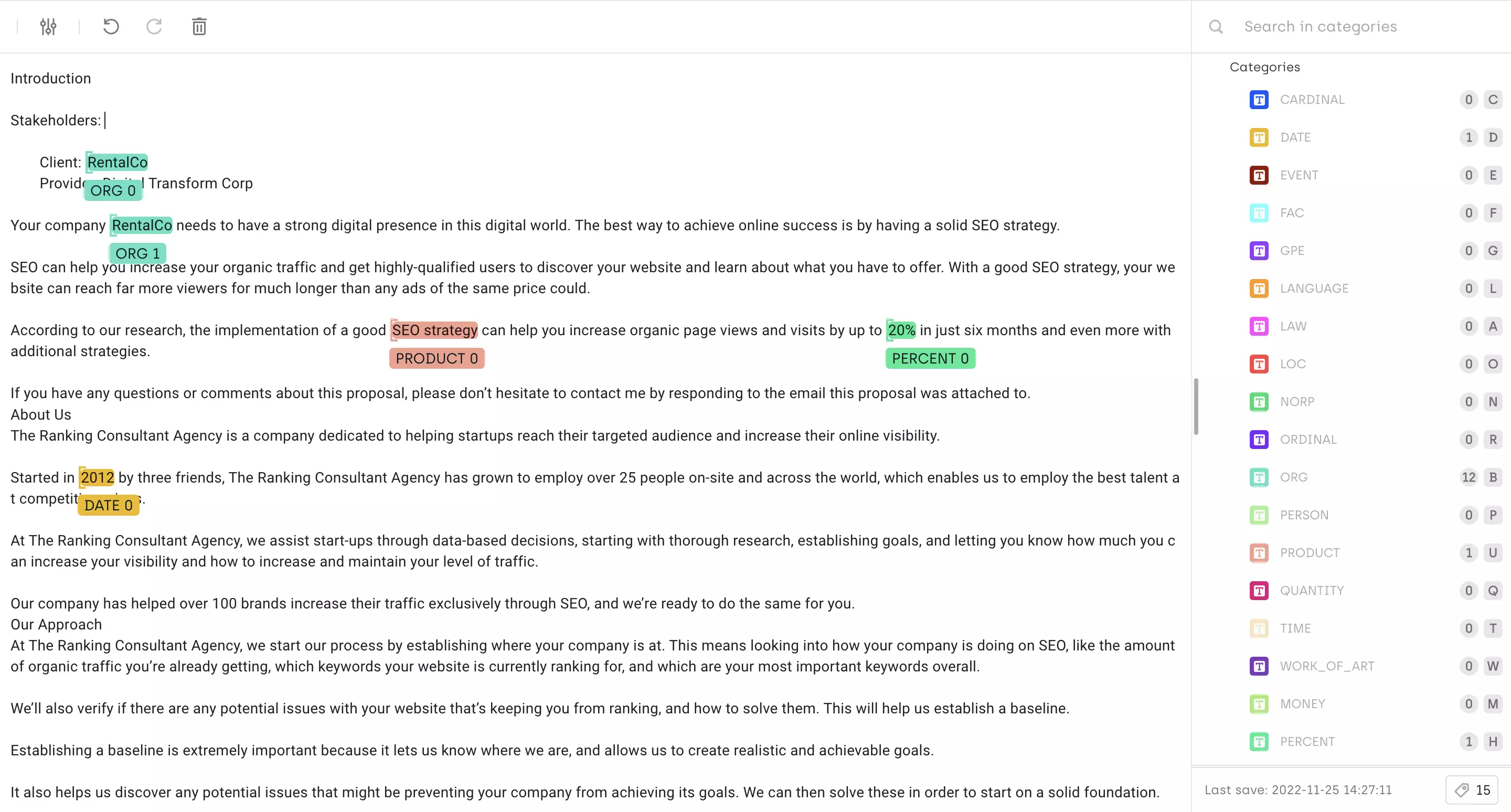
Annotated English Document

Annotated Arabic Document
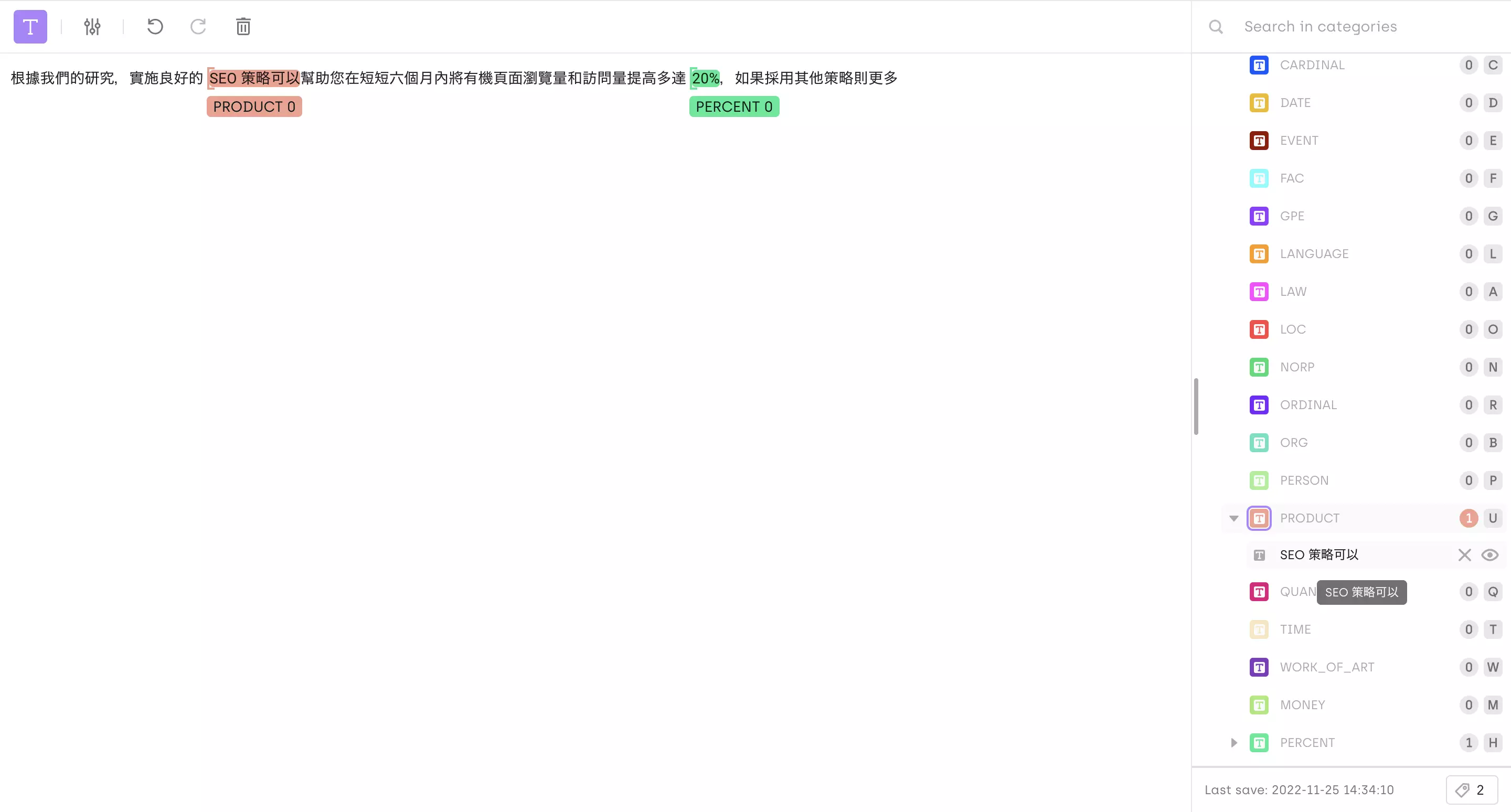
Annotated Chinese-speaking Document
Learn more!
Discover how training data can make or break your AI projects, and how to implement the Data Centric AI philosophy in your ML projects.
Propagate regex from UI
When labeling long documents, a time saver is to tag all equal tokens in one click automatically. We call this feature regex propagation. In the example below, you will see that the name of the company RentalCo is identified once and propagated by the labeler. A good way of accelerating the NER process is to generate pre-annotations.
Watch video
Formatting text for ease of labeling

Formatting text for ease of labeling
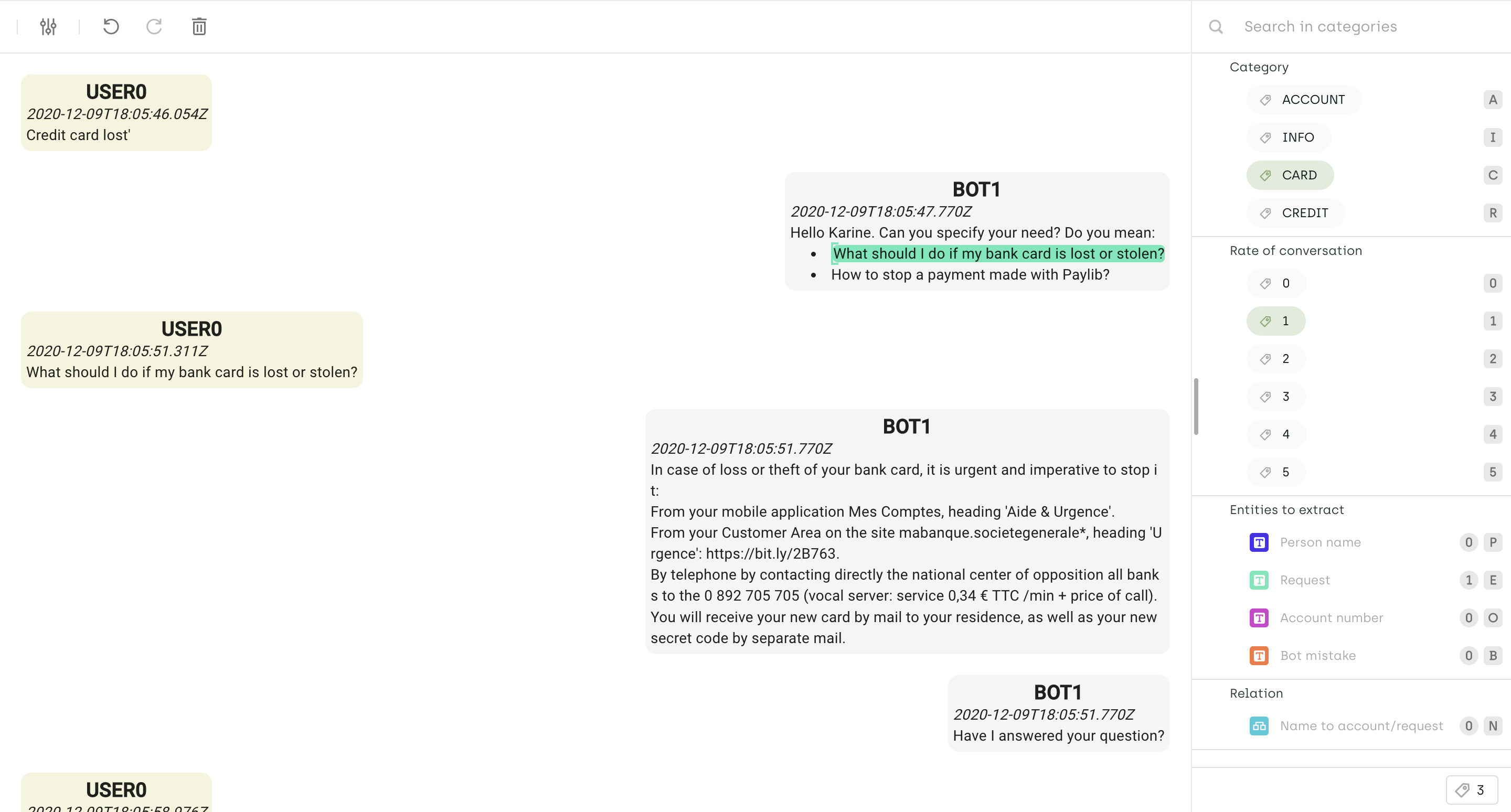
Formatting text for ease of labeling
Some text documents can be hard to visualize and annotate if formatting is not applied. For example, a long blog article or a conversation between multiple agents can be tedious to label if not displayed correctly. We have introduced rich text formatting in Kili to help customize text documents to ease the annotation task.
Labeling PDFs
PDF documents can be a lot more complex than simple text documents. Often, PDFs are made from a couple to hundreds of pages and they contain other data types such as images, tables, and graphs. When choosing a tool to label PDFs you should have in mind the following features to ensure success:
Native PDFs vs. Scanned PDFs
A native PDF is a PDF of a document that was “born digital” because the PDF was created from an electronic version of a document, rather than from print. A scanned PDF, by contrast, is a PDF of a print document, such as when you scan in pages from a print journal and then save this file as a PDF.
When labeling a Native PDF, the content of the PDF can be directly extracted by using the underlining text layer (i.e text can be selected from the PDF). On a scanned PDF this layer might not be present. In Kili, you can add OCRs to the scanned PDF to label it just as a native one. Now, you just need one interface to label all of your PDF documents!

NER being performed on scanned documents
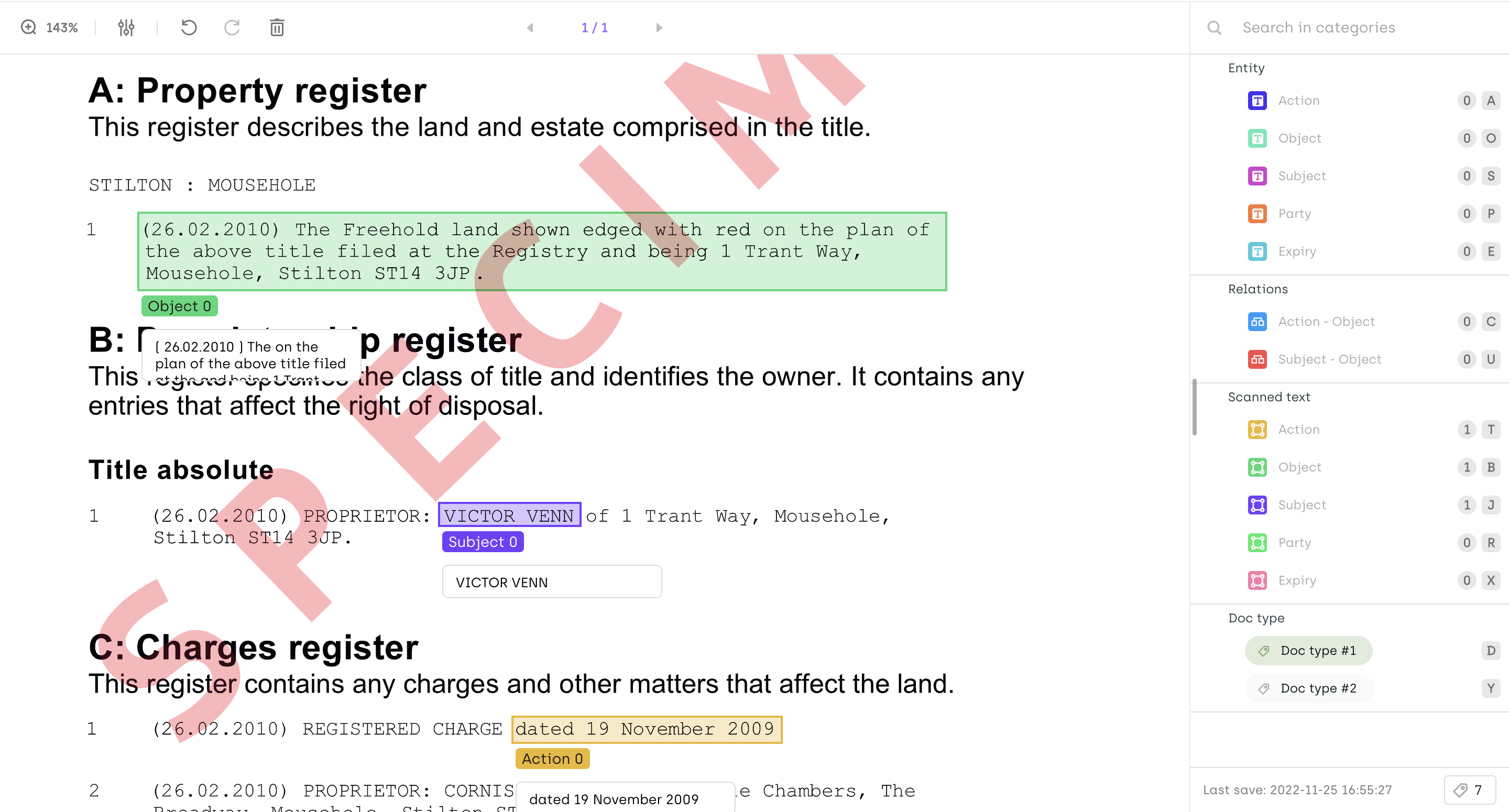
Another NER being performed on a scanned document
Page-level classification vs. Document-level classification
Because PDFs can contain multiple pages, it’s important you can make classifications at the page level and document level.
For example, let's say you want to label the type of document (claim, invoice, quote, …) and for each document, you also want to classify each page to differentiate the main document from the attachments. Tooling needs to be adapted for the metadata to be extracted.

Page-level classification vs Document-level classification
Extracting mixed content (images, tables, graphs, stamps, signatures, …)
PDF documents also contain elements other than texts, such as images, tables, or signatures. In various use cases, such as automatic document parsing and understanding, it is mandatory to be able to extract such elements during the annotation process.
Therefore, you need to have on your PDF interface the possibility to use both text annotation tools like classification NER and transcription and also image annotation tools like bounding boxes.

Name of contact and signature being extracted from a PDF document
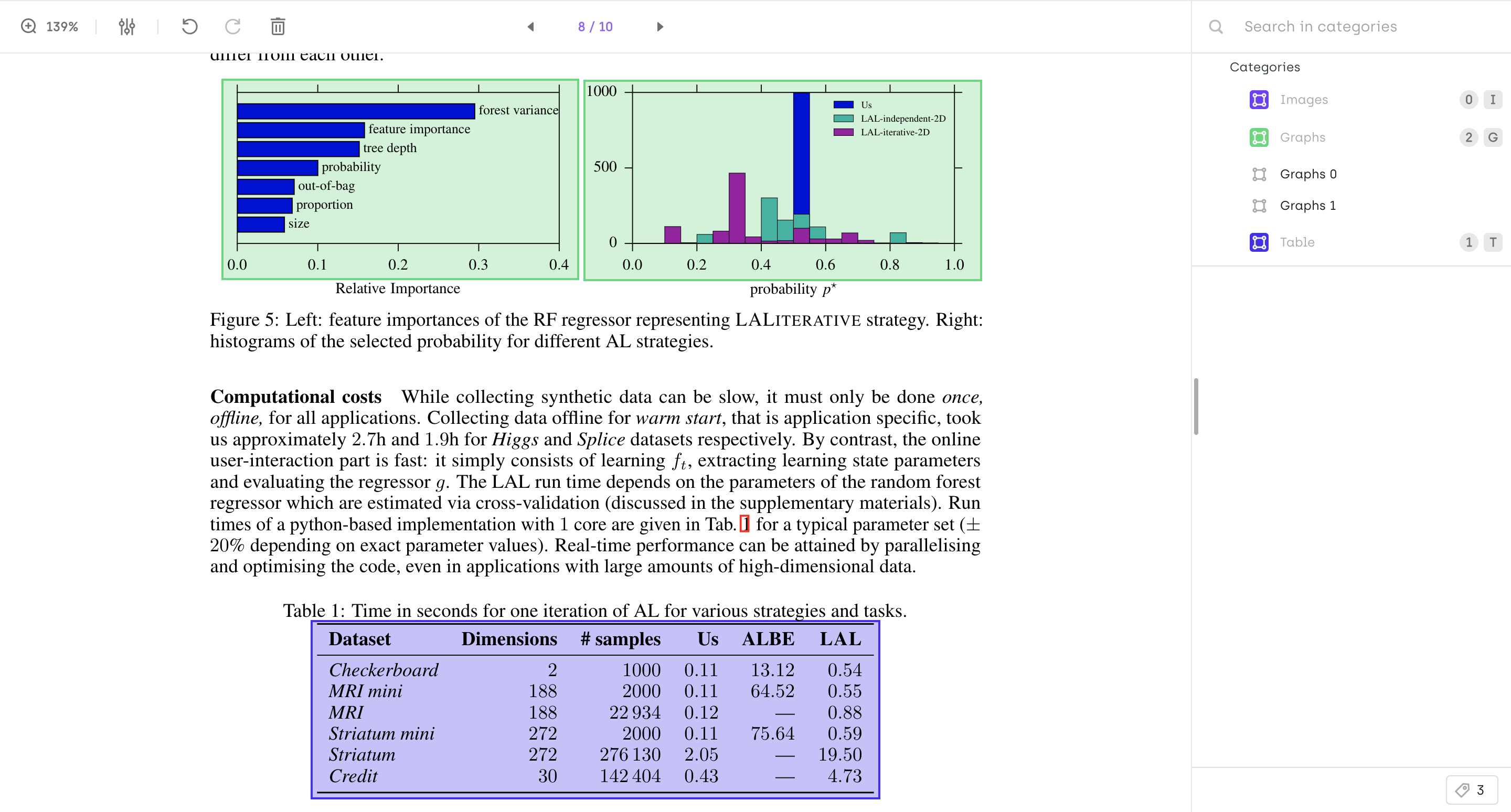
Tables and graphs being extracted from a PDF document
Labeling images with OCR
Lastly, you might also need to perform text annotation to extract texts from images, like extracting license plates video streams, or reading traffic signs.
If this is the case being able to use an OCR model with the labeling interface will be mandatory to speed up drastically labeling times. With Kili, you can use any OCR model that you want like Google Vision API, Tesseract OCR, Azure OCR, Amazon Textract, or your own custom model!

ADR sign being labeled leveraging OCR
Going further
Text annotation is the backbone of AI applications handling text under all its aspects. To scale annotation and produce reliable AI models in production data needs to be of the highest quality and relevance. Our mission at Kili is to help organizations tackle the bottleneck of training data quality. To do so, we are building a state-of-the-art data labeling platform with high labeling interfaces supported by data quality monitoring and automation.
If you want to learn more about data quality and labeling automation, go check out our documentation:

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
