.png)


_logo%201.svg)


AI Summary
Labeling geospatial data is undoubtedly more challenging than plain textual data because of the complexities involved. Typically, annotators face challenges when scrutinizing layers of geodata, such as coordinate, time, depth, and other attributes with limited resources.
To further complicate the task, organizations ingest more geospatial imagery that they can confidently annotate to produce consistent, high-quality training data. Issues like geometric distortion, overlapping bounding boxes, or failure to discern the detail in each pixelated frame will cause the machine learning model to perform below expectations.
In this article, we'll explore ways to improve the accuracy and efficiency of geospatial data annotation. More importantly, we'll discuss tools and annotation services that help your machine learning team to label geospatial images at scale.
Common Geospatial Data Annotation Techniques and Examples
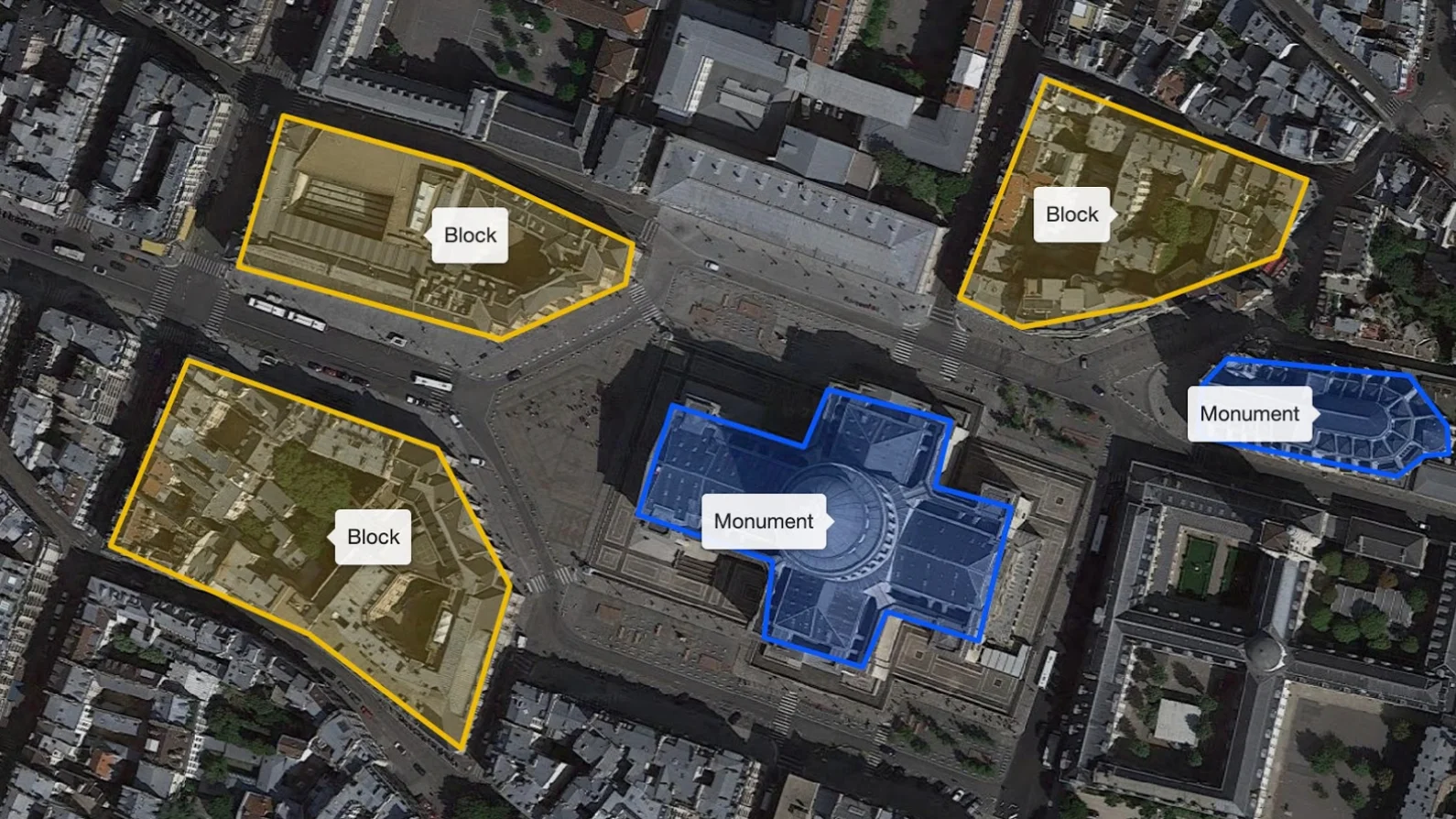
Geospatial data typically consists of remote sensing datasets taken from satellites, cameras, or sensors from a higher altitude. Labelers must annotate them to categorize and describe specific information or objects before training the foundational model. Usually, they use some of these annotation techniques.
Semantic segmentation
Semantic segmentation involves identifying and classifying one or a group of pixels that belong to a specific object. As the name implies, the technique trains the model to associate different segments with the given labels. This is helpful when developing machine learning systems for analyzing geospatial maps. For example, labelers designate segments of forests, water bodies, mountains, open spaces or land use in satellite imagery.
Polygon annotation
Polygon annotation creates significantly more accurate training data for the model to train on. Here, the annotator draws a polygon along the edge of the object of interest, which they then classify with the appropriate label. For example, you can apply polygon annotation to a building's architectural design taken from drone imagery.
LiDAR annotation
LiDAR data consists of three-dimensional information consolidated from multiple sensors. Unlike typical imagery, LiDAR allows computer vision systems to analyze the depth and distance of surrounding objects. Hence, LiDAR annotation involves complex labeling techniques, including 3D point cloud annotation, to provide a more granular insight and accuracy.
Keypoint annotation
Keypoint annotation allows labelers to pinpoint specific points or coordinates in images. It helps computer vision systems identify specific landmarks or objects with great accuracy. For example, you can mark a commercial building with a 'dot', or use the same technique on a moving vehicle in aerial imagery.
How to Label Geospatial Data at Scale
Machine learning teams will likely be familiar with the abovementioned geospatial annotation techniques. The problem lies in applying them at scale. When done manually, geospatial data annotation creates a bottleneck that impedes AI development in organizations. While human labelers and subject matter experts continue to play pivotal roles, automating the labeling workflow is crucial to improve efficiency and reduce unforced errors.
We share several helpful labeling automation features below.
Active learning
Active learning enrolls machine learning models to assist human labelers. Rather than labeling all the datasets, human labelers create several annotated samples from which the model 'learns'. This way, the model can predict and annotate the remaining data in ways human labelers would. Kili uses this process to improve labeling accuracy from 77% to 85% while requiring lesser raw geospatial data.
Custom object detection models
When annotating geospatial data, labelers are tasked to identify objects with definite forms that custom object detection models are trained explicitly on. Object detection models, such as YOLO, can be refined with supervised learning, which enables them to identify and classify other objects of similar classes. Then, labelers can use the pre-trained model to pre-annotate or identify labeling mistakes. Here's how to start using YOLO for geodata labeling on Kili.
Segment Anything Model (SAM)
SAM is a foundational model trained with large image datasets to enable image segmentation with minimum human intervention. However, SAM is far from perfect and requires further fine-tuning to perform complex segmentation tasks. As such, we've adapted and trained SAM to aid annotators in geospatial annotations. With Kili, SAM allows labelers to create a mask overlaying the specific object just by clicking on or drawing a bounding box over the object.
Label large geospatial datasets 10x faster
Watch video
How to Ensure Geospatial Annotations Accuracy
Accuracy is as critical as efficiency in geospatial use cases. To ensure that, you must streamline collaboration amongst teams of labelers, reviewers, and project managers with the appropriate checks and balance that support continuous improvement.
For example, Kili Technology allows project managers to distribute labeling tasks to multiple human annotators automatically. While doing so, project managers append labeling instructions to ensure all labelers clearly understand the tasks. Our software also enables labelers to raise issues and seek clarity from project leaders.
Let's dive deeper into various ways to improve accuracy in geospatial annotations.

Enable transparent review and feedback
Labelers, reviewers, and other parties in the labeling workflow cannot work in silos. They must maintain open and prompt communication to fix issues or escalate them to the correct party. Our labeling platform provides issue-tracking tools to prevent labeling mistakes from manifesting in the ML model.
For example, labelers can ask questions when unsure of a task, while reviewers may request a rework on incorrectly annotated samples. We also allow reviewers to narrow down on specific types of datasets or labelers they're working with.
Leverage quality metrics and analytics
Mistakes can easily happen when labeling geospatial files. For example, man-made objects might be overlooked as natural landscapes on low-resolution satellite images. And not all labelers are skilled enough to differentiate such subtleties in geospatial data.
To ensure consistency across annotated datasets, you use a data labeling solution that provides inter-annotator agreement metrics like the consensus mechanism. With Kili, enabling the consensus score allows you to evaluate how many labelers classify an object similarly.
While the consensus score tells you the general agreement or bias amongst a team of labelers, it doesn't measure accuracy in the absolute sense. For instance, you might have a 90% consensus that categorizes a bus as a truck, which doesn't reflect the truth. So, you'll need another metrics that we call honeypot to assess and improve labeling quality thoroughly.
The honeypot method compares the annotated datasets produced by labelers against a high-quality sample designated as ground truth. This allows you to evaluate the labeler's ability and if they need further training to achieve the desired accuracy.
Kili Technology lets you use consensus and honeypot to fairly asses the labeler's performance. You can also zoom into specific insights to filter the scores according to labeler, tasks, or projects.
Automate quality assurance (QA) workflow
It takes tremendous effort to ensure seamless collaboration and information flow between labelers, reviewers, and project managers. QA tasks might turn into a speed bump itself if ML teams manually implement them instead of automating them with advanced software algorithms.
Here's how Kili Technology enables a frictionless QA workflow and produces better dataset accuracy.
Automated QA based on the model likelihood
Automated QA uses a pre-trained machine learning model to review the annotated geospatial sample. ML teams can program auto QA with a Kili plugin or externally to compare human-annotated samples with the model's inference. If the model generates vastly different results from human reviewers, the annotated datasets are likely erroneous.
Programmatic QA
Programmatic QA is a Kili-supported feature to assist human reviewers. It involves writing specific business rules on a Python script that Kili uses to check each labeled dataset. For example, you need all landed residential units labeled with numbers that reflect their actual address. Once the script is written and activated, Kili will automatically reject labels that don't start with numbers. Kili sends datasets that failed the check back to the annotator to be relabeled. At the same time, our software tracks and updates the analytics to reflect the annotation accuracy.
Double Your Labeling Productivity with Programmatic QA
Kili's Programmatic QA provides you with complete control when defining conditions that assure quality geospatial datasets. When enabled, programmatic QA replaces human reviewers in a time consuming and resource-intensive task. More importantly, it helps your team eliminate repetitive and unnecessary data movement between reviewers and labelers.
Why burden your team with constant communication when you can set and automate all the rules in advance?
Instead, ML teams can focus on building and innovating AI-powered applications with this time-saving feature.
Programmatic QA is a fitting initiative for organizations to manage and scale machine learning and AI implementations to meet growing geoAI demands. The feature allows ML teams to train geospatial models with high-quality data at half the rate it was. It also provides a single point of control for a project manager to define and assert annotation requirements across distributed teams of human labelers.
Conclusion
Geospatial annotation is increasingly important in various industries. Aerospace, agriculture, defense, and autonomous vehicles are some areas that require precise geospatial datasets. Yet, large datasets, complex geodata, human errors, and scalability concerns remain stumbling blocks that ML teams must overcome.
Effective annotation techniques, combined with automated quality assurance workflow, allow organizations to overcome challenges in developing geoAI applications. They use image annotation tools like Kili Technology to reduce cost, produce accurate datasets and shorten time-to-market.