
.png)

_logo%201.svg)


AI Summary
Welcome, everyone! Joining me for this webinar's digest is Jean Latapy, our Solutions Engineer. We are absolutely thrilled to have you join us on this journey as we continue our exploration of large language models (LLMs). Over the past few weeks, we've covered a great deal of ground, and we are eager to delve into our topic for today: how to correct errors made by LLMs, specifically in complex, domain-specific business tasks.
But before we dive into the main topic, allow us to share a few exciting updates about our product.
Product Update: New Annotation Flow, Interactive Segmentation and Visualizing Relations
First, we have released a new flow for different tasks, which allows labelers to select their tool from the toolbar and complete all related jobs directly from the floating menu. This is particularly useful when dealing with a large number of categories.
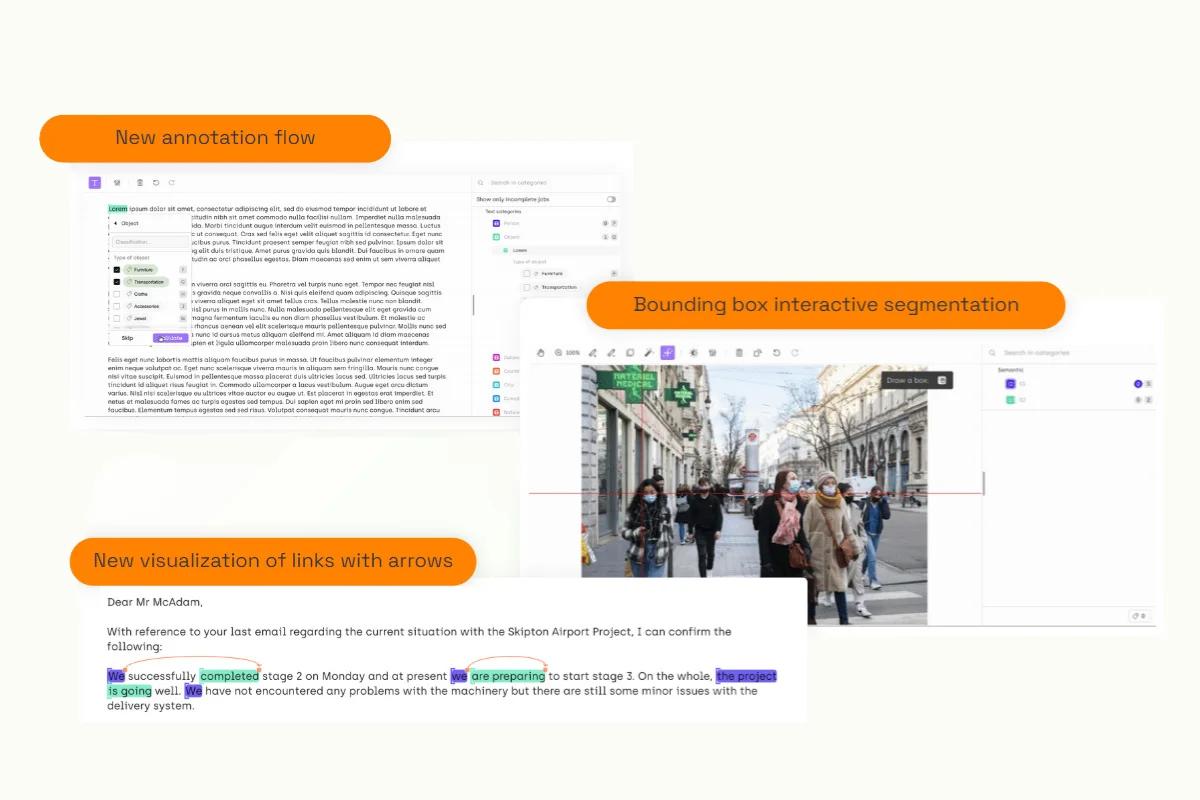
We also introduced the bounding box into the interactive segmentation tool. This allows labelers to use the bounding box to accurately target the objects that they want to update.
Finally, in the text and image labeling interface, you can now visualize the links between the objects which can give you more visibility on their relations.
Industry Update: New paper from Meta shows the power of quality data
Before we proceed, let's briefly touch upon an exciting development in the world of AI. Meta recently released a paper demonstrating how they fine-tuned their large language model, Less is More for Alignment (LIMA), transforming it into a conversational model akin to a chatbot. Remarkably, they achieved this with only 1,000 carefully selected training examples, a significant reduction from the 50,000 used by OpenAI.

Of the 1,000 examples Meta used, only 250 were manually created. This dramatic reduction was achieved by meticulously sampling the examples for quality and diversity. Despite the lower quantity, the fine-tuned LIMA's performance is said to be almost on par with GPT-3.5. This suggests that if you fine-tune one of these models with a limited number of high-quality examples, you can compete with the state-of-the-art models, thereby demonstrating the immense value of high-quality training data.
A Recap: The Power of GPT and SAM for data labeling
In our previous sessions, we learned to harness the power of GPT-4 for automated pre-annotation on the NLP side, while for computer vision tasks, we utilized Meta’s SAM. With SAM, we were able to label semantic masks up to three times faster, prioritize review work based on model confidence, and drastically improve the quality of labeling.
While these models are highly effective for simpler tasks, like broader category classification or common entity extraction, they can stumble when we enter specific domains, dealing with long, complex documents, or images with intricate structures. For instance, asking ChatGPT to provide scientific references in a domain may result in the model creating unreliable information, a phenomenon known as "hallucination".
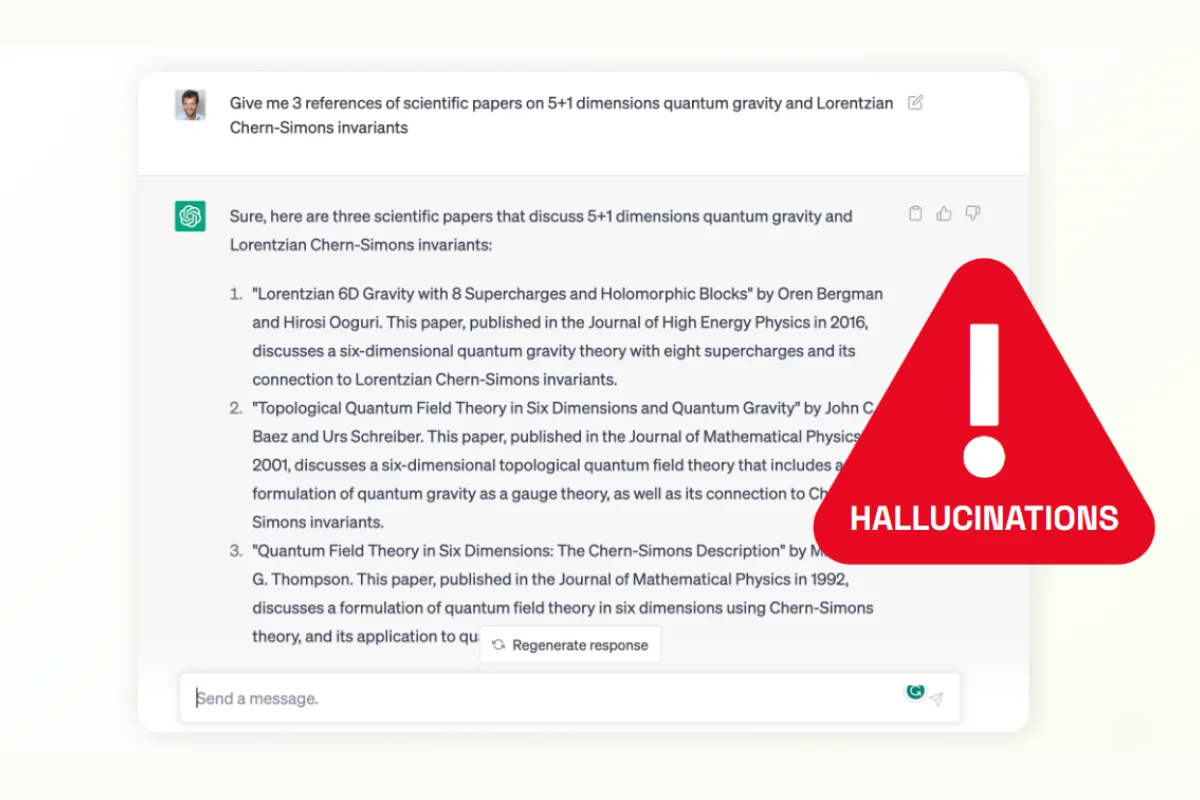
But fear not. In this guide, we'll explore how to fine-tune these models to rectify such errors.
And now, let's dive in!
Mistakes and Challenges in Foundational Models
Foundational models such as SAM can demonstrate remarkable efficiency in certain applications but struggle in more complex scenarios. SAM, for instance, faces difficulties with intricate scenarios such as background image segmentation involving shadows. SAM also stumbles in low-contrast applications. For example, when asked to segment objects that blend in with their surroundings, such as a bird on a beach. Further, SAM grapples with labeling structures that necessitate domain-specific knowledge. SAM can also struggle with smaller and irregular objects.
Language models, despite their impressive capabilities, exhibit their own set of errors. Comparisons with state-of-the-art supervised models show a significant gap. For example in a paper titled “Jack of all trades, master of none”, GPT, one of the leading language models, scores 56 compared to the 73 scored by state-of-the-art supervised models. The categories of errors include hallucinations, lack of logical consistency, irrelevance, incompleteness, and biases ingrained during the pre-training phase.
Sources of Errors in Foundational Models
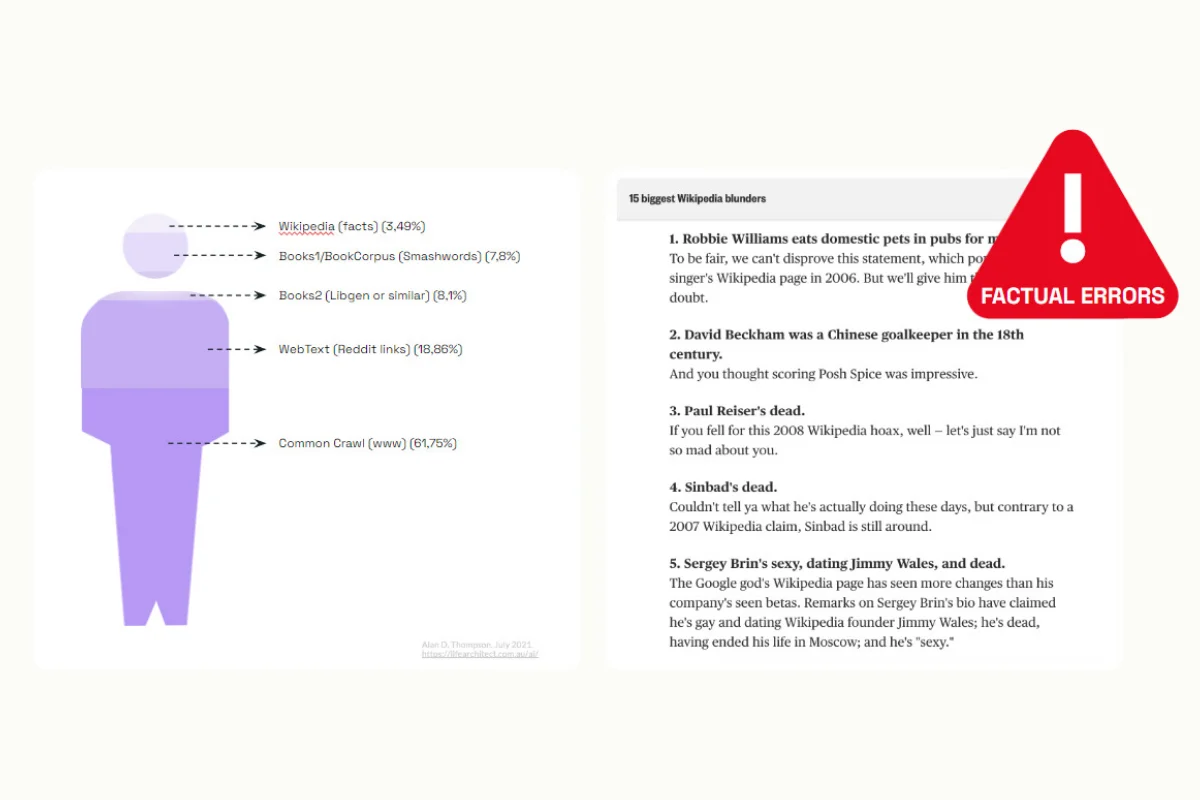
- The primary source of errors lies in the training data.
- Large language models rely heavily on the data they are trained on, which could contain biases, inaccuracies, and irrelevant or incomplete information. These misleading data points can propagate errors and leak incorrect information into the model. For instance, even widely used training sources like Wikipedia can contain inaccuracies.
- The second error is the objective function used when you train a foundation model.
- Large language models are trained to generate plausible responses that resemble the training data. However, their objective function may not align with the user's objective function, which may focus on text classification. This disparity results in a lack of direct control during the pre-training process.
- The third source of errors is the lack of reasoning capabilities.
- Since these models are trained to favor generic responses, they do not have the capability to reason. As a result, they might overlook more suitable but less probable responses.
- Lastly, prompt engineering plays a crucial role in the model's effectiveness.
- The way a user prompts the model directly impacts the output quality. It can be both an art and a science to prompt a model correctly, and slight variations in prompts can lead to significantly different answers, adding to the model's unreliability.
After this discussion about the limitations and the major sources of errors in foundational models, the focus will now shift toward strategies to overcome these shortcomings.
How to overcome the limitations of foundation models
Let's divide this process into three main sections:
- The measurement of the model's performance
- Model adaptation to your own context
- Handling the long-tail
Measuring the performance of model outputs
Let's start with measuring the performance of the model outputs. The traditional way to do this is to compare what the model is producing to a ground truth, created manually by experts. This allows us to compute overall metrics—standard machine learning metrics that enable you to assess your model's performance. An example of this can be seen from our earlier webinar on classifying IMDB reviews, where our GPT model had an overall performance of 94%.
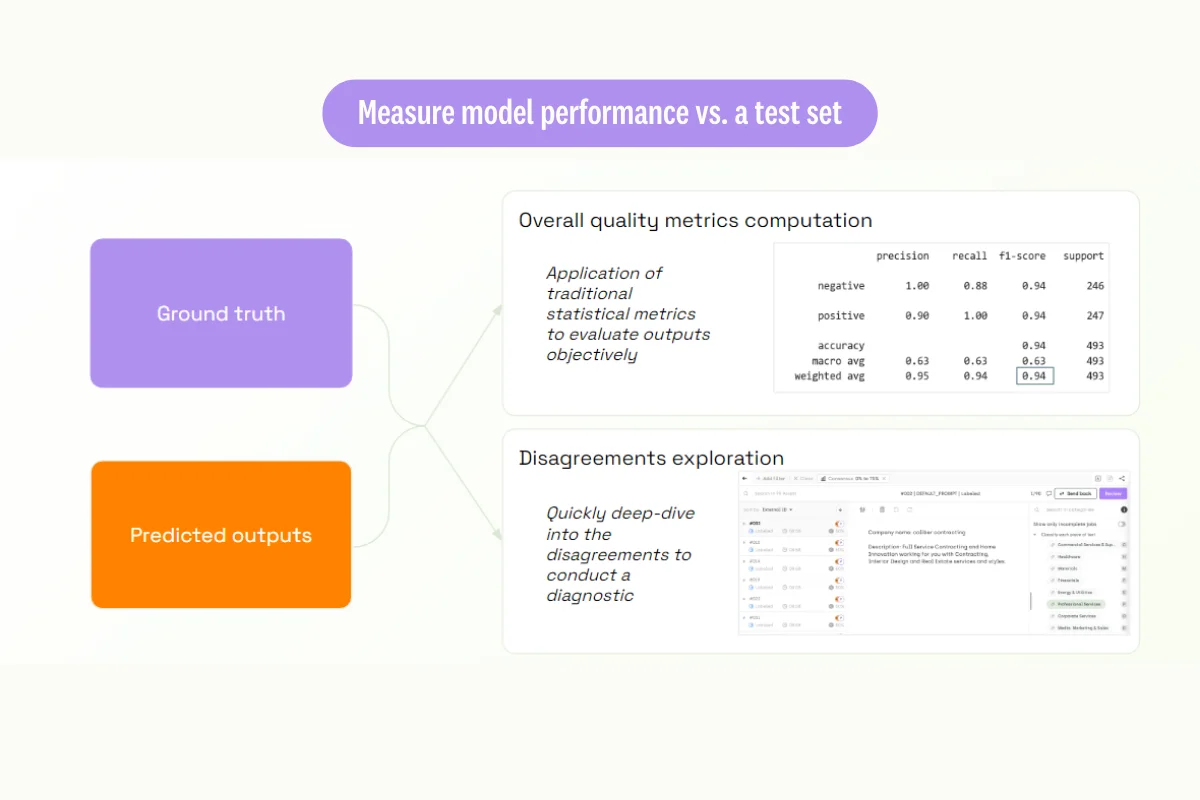
Another advantage of this approach is the capability to deep dive into potential disagreements between the model and the ground truth. This understanding can help us solve potential discrepancies and enhance the model. We illustrate this process with a GPT labeling use case where we're performing brand classification.
Brand Classification Use Case as an Example

Source: Company classification dataset from Kaggle
To carry out this task, we take company information and associate it with one of 13 classes. We follow the traditional GPT labeling process that involves taking input data, generating a basic prompt for classification, and performing automated labeling. Then we move to the second step: analyzing the quality of the results compared to a test data set.
For instance, we have a brand categories project where data has been labeled first by an expert (our ground truth), and then by our classification prompt using GPT. By comparing these results, we can see when the model and the ground truth agree, as well as any disagreements.
Watch video
We also leverage filters to focus on potential disagreements and analyze why they perform well or not. We also utilize further analytics to have a macro overview of where the model is correctly performing and where it's not.
Watch video
But the model's performance may not always be satisfactory. Here, we have tools to diagnose and potentially correct these issues, and iterate on our modeling strategy to improve it.
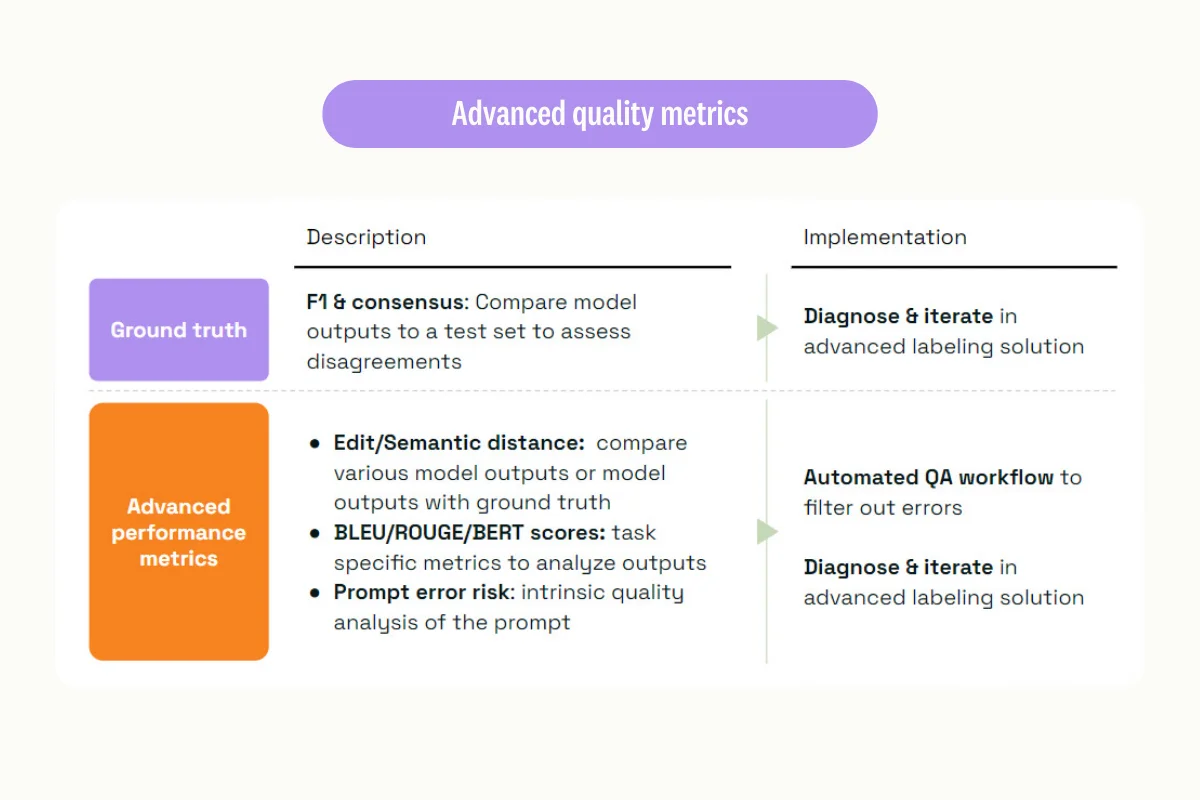
After comparing the model's output to a ground truth using F1 or consensus metrics, and performing diagnostics and iteration, we can leverage advanced metrics relevant in specific cases. These can include computing distances or semantic distances to compare various model outputs to ground truths, computing specific NLP metrics like BLEU or ROUGE, or even using the prompt error risk score.
While we won't delve deeper into these metrics today, knowing them allows us to automate part of the quality assurance workflow by implementing custom rules based on the metrics we're leveraging. For example, implementing thresholds to filter out potential errors and then push them to manual review for iteration.
Once we've measured the performance and have tangible elements for a diagnostic, we can adapt the model to our own context by changing the model we're using.
Adapting the model to suit our needs
We can achieve this by tackling three methods:
- Downstream filtering of the model responses
- Fine-tuning a large general model with highly curated and task-specific data
- Relying on embedding or using the representations that the model generates to build our own applications.
Downstream Filtering
Let’s start with downstream filtering, which involves fine-tuning the model to only provide the most relevant responses. This method was used in training ChatGPT and it can be replicated to ensure the model is highly specific in performing its tasks. The training process typically involves collecting demonstration data following a supervised policy, then prompting to generate different model outputs, then ranking these models by human raters, and optimizing the policy using reinforcement labeling.
.webp)
Source: OpenAI - 03/2022 - Training language models to follow instructions with human feedback
Clearly, the downstream filtering method can be a tedious and complex one that relies on a lot of energy and resources to develop.
Fine-tuning a general model to a specific use case
Alternatively the second option would be to fine-tuning a large general model to fit the specific objective for your use case. The workflow is as follows:

This can be applied on any foundation model whether like SAM, Dino, BERT, GPT, etc. The principle is to take those models and input a highly curated dataset to make the model more specific on its given task. This is to avoid the general model from falling into a “catastrophic forgetting problem” which happens when it forgets previous tasks after learning new tasks.
DinoV2 for classification use case
To illustrate this, we’ll be using DinoV2 for classification:
We'll be dealing with defect detection in casting products. On one side, we have images of products that are defect-free, and on the other side, we have images of defective products - some with little holes, some with scratches, and so on.
The goal is simple: classify the images into "good" or "defective" categories. For this, we'll use the Dino V2 model, a transformers model that was trained on a vast amount of data. This model can generate embeddings from images, providing a vectorial representation of an image in a lot of dimensions without any specific training.
We'll start with a very generic approach: using our Dino V2 features coupled with a nearest-neighbor algorithm. This traditional algorithm associates a given element to its nearest neighbors in the vector representation that we have. In this case, we don't need any fine-tunings. We are using the embeddings of our model directly to make a decision.
Next, we will make our model more specific by fine-tuning it. This means adapting the weights of the model to some labeled data that we provide. This doesn't need to be a large dataset - even 50 or 200 examples can be enough.
Let's see the results of our first approach. Using the embeddings directly, we reach a performance of 83%. This might seem good, but depending on the industry context, it could be considered low. For example, in a context where these metal pieces are to be used in airplanes, an accuracy rate of 83% might be unacceptable.

That's why we fine-tune. Using Dino V2 and our linear layer with 200 examples, we were able to increase the model's accuracy significantly, reaching over 95% accuracy with only 200 examples.

Now, this might sound theoretical. That's why we're making everything we've done in the backend available to you. We'll share the notebook we used. In this shared notebook, you'll find all the steps necessary to reproduce this Dino V2 fine-tuning, starting from the project creation in Kili to your own model training.
However, let's take a step back and draw some conclusions here. When our error tolerance is high, foundation models can be used with very limited examples to reach acceptable performance. But, when your tolerance to error reduces, like in industry-specific contexts, relying on very curated examples can significantly increase performance.

Relying on Embeddings
Lastly, a part of fine-tuning involves relying on embeddings to learn faster. To do this, we'll introduce the retrieval-augments-generation (RAG).
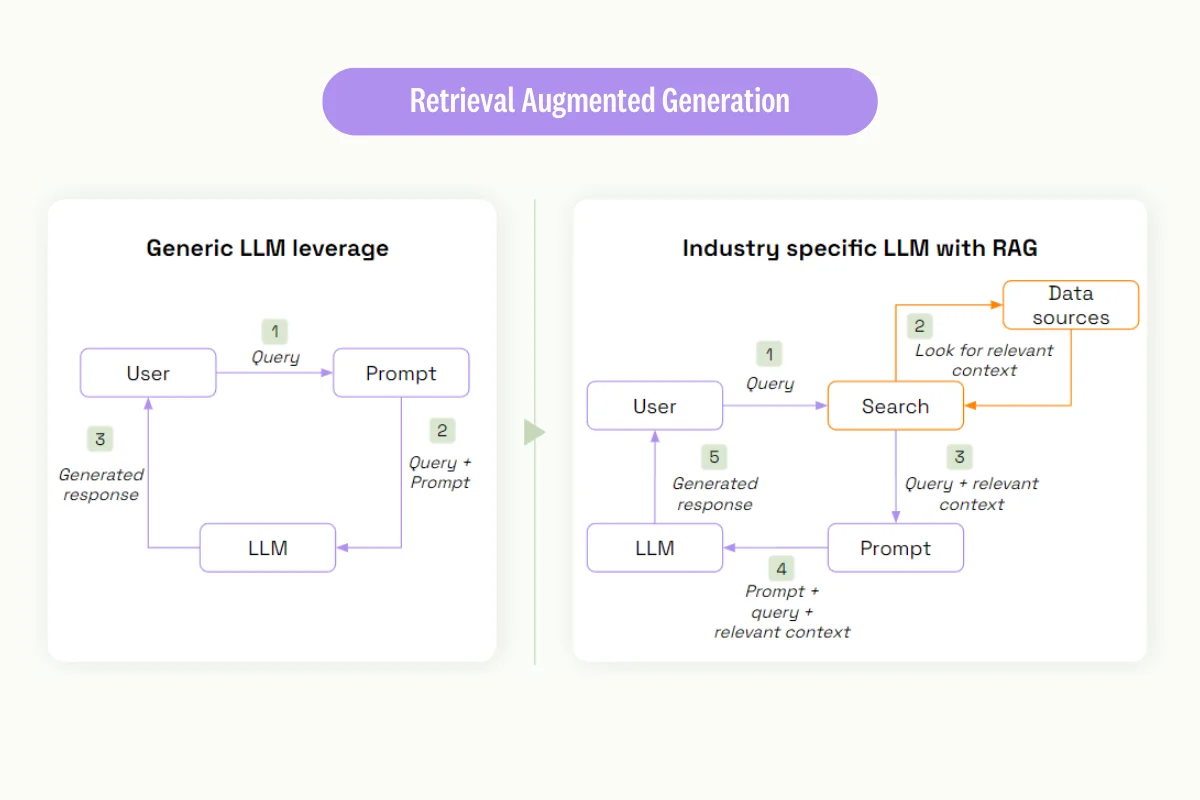
It's a generic way to leverage a large language model, adding your own context when using a large language model.
If this isn't enough and you're still getting poor results, you have options. You can work on the prompt, evaluate it with custom metrics, manage the templates, try different versions, or add a few shots to the prompt. You can also work on the model itself, evaluate it, compare different model outputs, adjust the parameters, and make it more specific with fine-tuning.
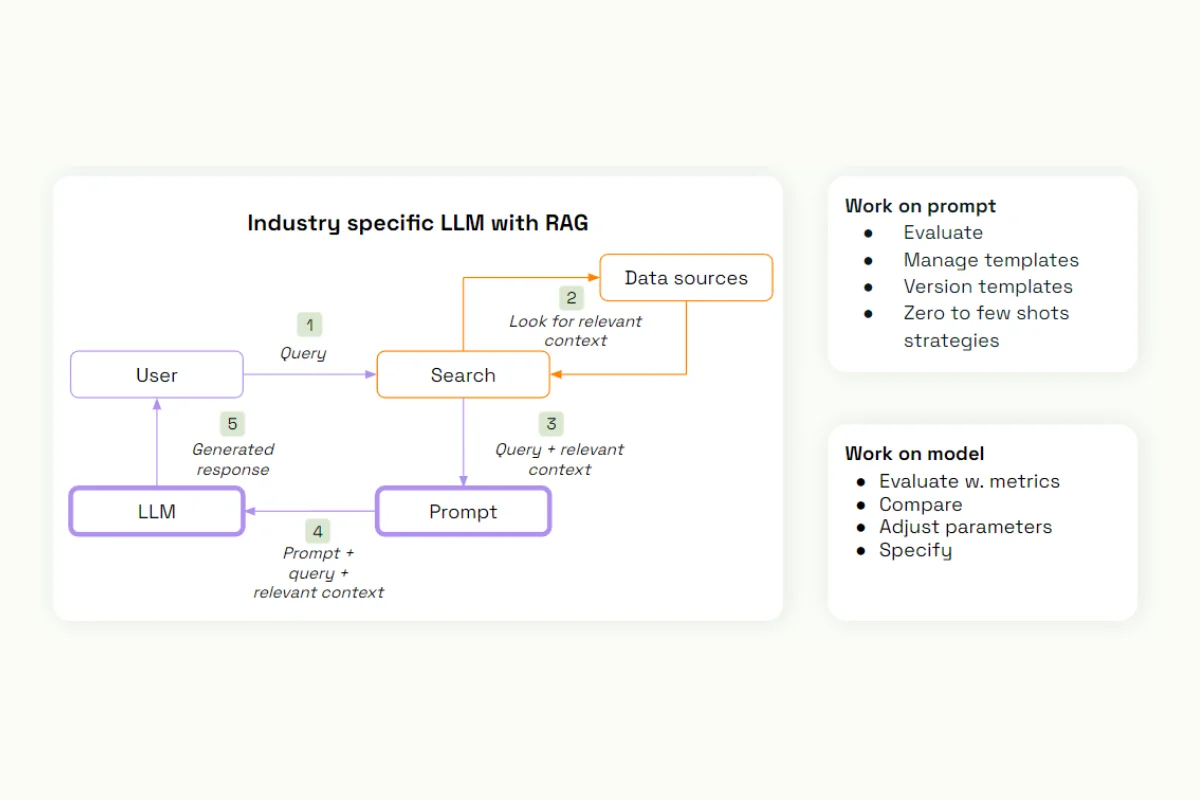
If these still don't work, you can work on the search part, using generic embeddings to look for relevant documents in your data sources with vectorial search in a vectorial database. For advanced strategies, you can customize this search approach with a supervised approach.
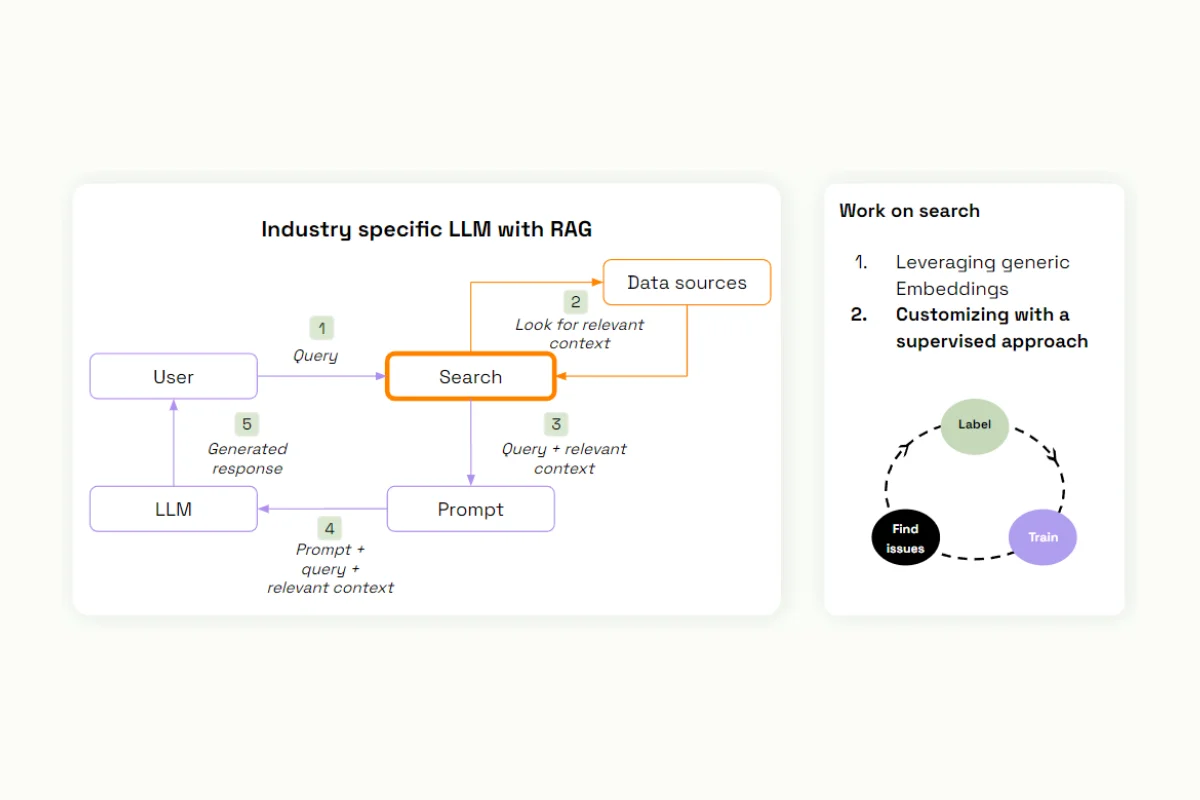
We provide examples, train a model, diagnose it, and iterate on this model to provide the most relevant approach to the additional elements that we are providing to our prompt.
Handling the ‘long-tail’
We’d like to wrap up our discussion on error limitation with a key concept: handling the 'long tail' of a project. In this context, the 'long tail' refers to errors that emerge once our model is live and operating in a production environment. It's essential to have a support system in place to manage and rectify these errors, ensuring our model's ongoing performance and accuracy.
To accomplish this, we need to implement an auxiliary system to guide and correct elements in production. One way to do this is by leveraging the confidence scores produced by our model. In the case of GPT, these confidence scores are outputted as log probabilities (log probs) of the next token to be generated.
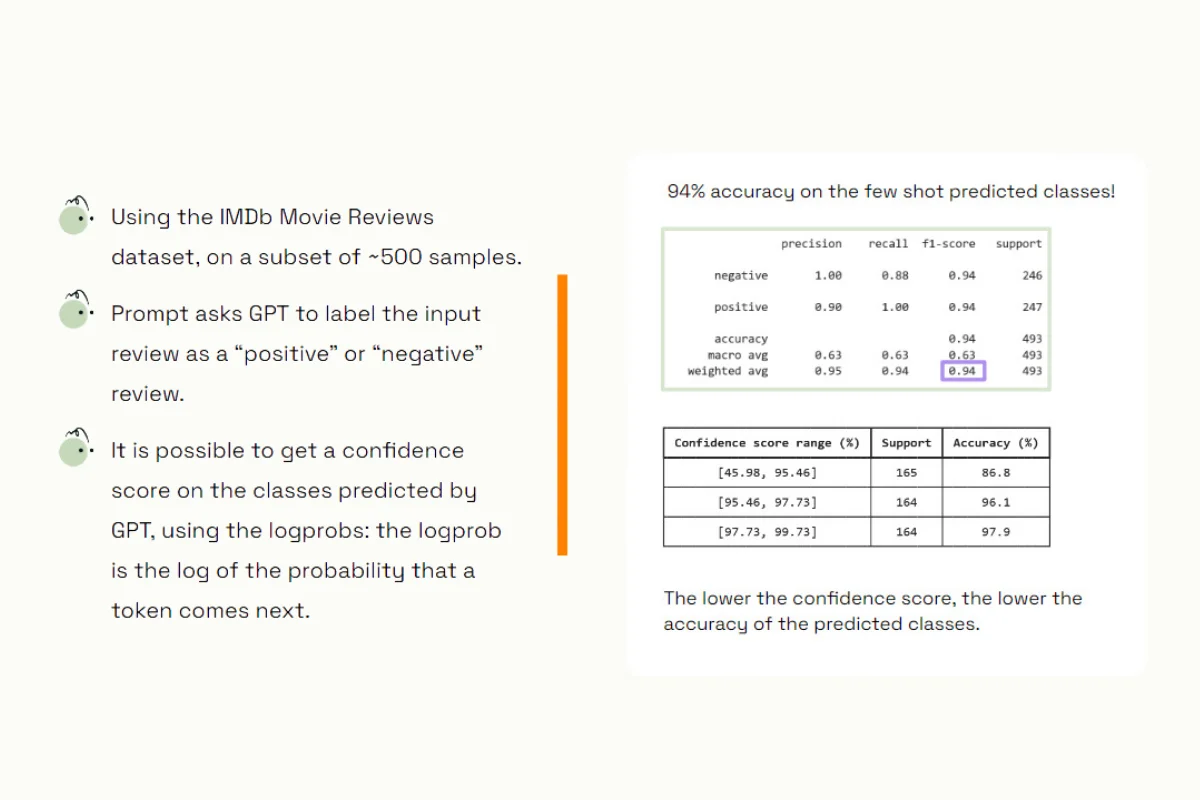
A lower confidence score on a given output typically indicates a lower accuracy of the predicted class, making this metric a strong indicator of your model's performance. Simply put, the lower the score, the higher the likelihood of an error.
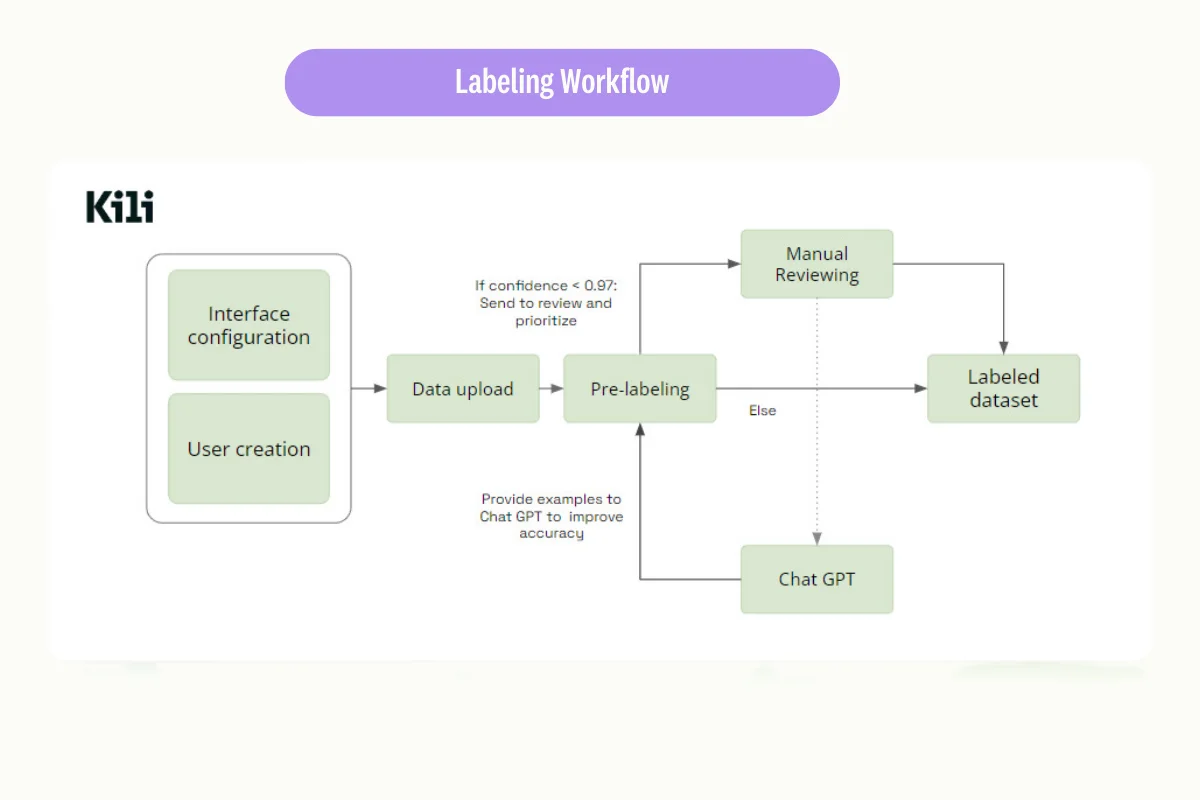
This leads us to a key strategy: implementing a confidence-based workflow. You can use your model, for example, ChatGPT, to perform a given task, and then automatically prioritize elements for review based on their confidence scores.
To better understand this concept, let's consider an example project we've worked on. We decided to integrate our log probs as metadata into the project. This means we could access and filter our data based on confidence levels, allowing us to quickly identify items that need review.
Watch video
When confidence levels were high, we observed a lot of agreement in our data — many elements were 100% accurate. But when we examined items with lower confidence levels, the number of disagreements (or errors) increased significantly.
This illustrates the value of using confidence scores as a guide during the production process. It helps us pinpoint areas of our model that require fine-tuning, ultimately improving its accuracy and reliability. It's a valuable strategy for managing the 'long tail' of a project, and I strongly encourage you to incorporate this into your own workflows.
So, for those eager to dive deeper into this subject matter and learn how you can enhance your data labeling efforts, particularly when fine-tuning Large Language Models (LLMs), I strongly recommend checking out our webinar dedicated to this topic.
In fact, we've held two webinars in the past that might pique your interest. The first was an introductory session on large language models, and in the second, we delved into how these models can be harnessed to label data more efficiently and swiftly. The strategies discussed in these webinars can be effectively employed to fine-tune your own GPT or SAM models.
Conclusion
As we draw this discussion to a close, it's essential to note that despite their power and efficacy, models such as SAM, GPT, and marginal information models do have their limitations. They can make errors, especially with complex scenarios, low-contrast images, or highly specific business-related contexts. These mistakes can often be traced back to the way they're trained, biases in data, lack of compatibility, and limitations related to their reasoning capabilities.
But the silver lining here is that these models can be fine-tuned by labeling a bit of data. We’ve discussed the three strategies that you can employ to have better control over the quality and trust you can put into the output of these models
Applying any of these strategies can significantly impact and enhance the quality of your model, mitigating the inherent errors and biases.
Kili plays a crucial role in enabling such fine-tuning. If you haven't already done so, I invite you to sign up for the product and explore one of the Jupyter notebooks we've prepared and shared. It'll demonstrate how straightforward it is to fine-tune your first LLM, GPT, or SAM model.
And so, we’ll leave you with this: always remember, even the most advanced models have room for improvement, and it's in our hands to refine, reshape, and perfect them to the best of our abilities.
Watch video

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
