.png)

_logo%201.svg)


AI Summary
What is Data Labeling?
Artificial intelligence has made its way into almost every aspect of our lives, offering faster and smarter solutions in industries such as healthcare, marketing, security, and transportation.
In fact, between 2022 and 2023, enterprise AI adoption rates are predicted to rise at a growth rate of 38.1%. To drive machine learning and AI success, organizations require large quantities of high-quality data.
Raw data needs to be enriched with information before it can add any real business value, and this is where data labeling comes into play.
Data labeling refers to the process of tagging data with meaningful labels to provide it with context so that machine learning algorithms can learn from it and generate accurate predictions on unseen data in the future.
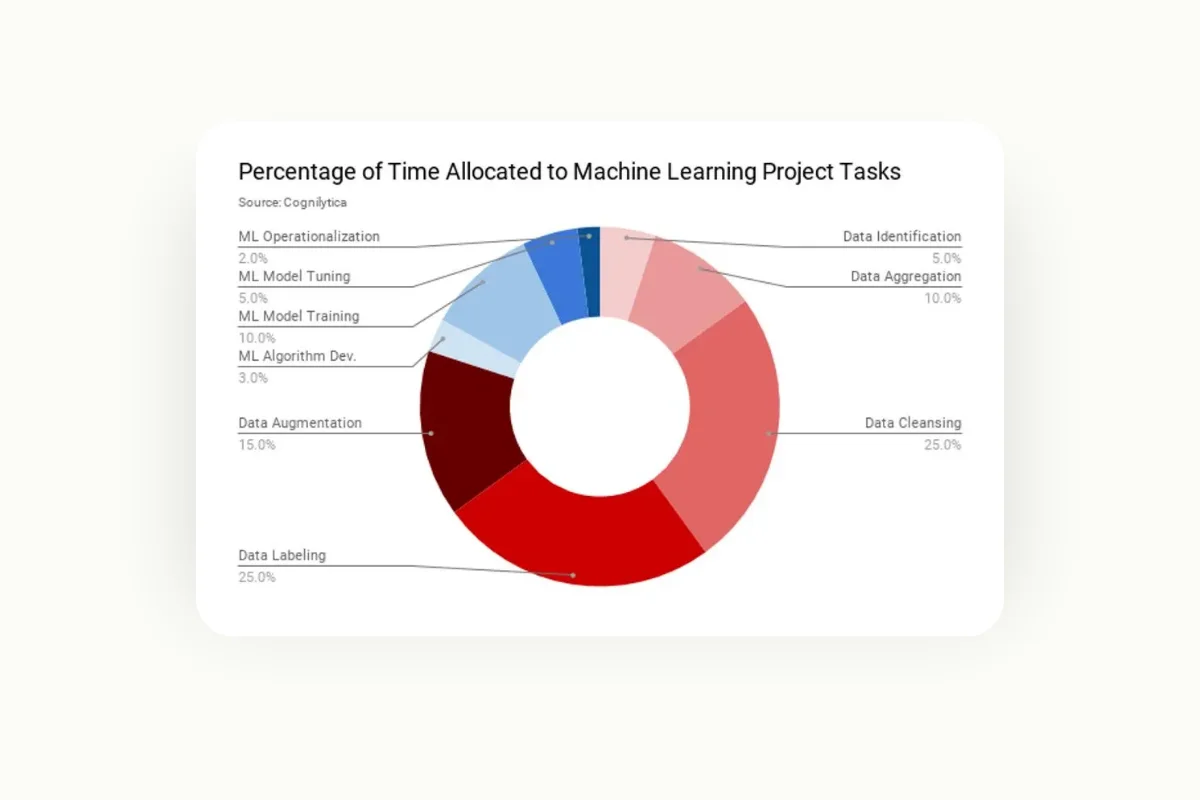
According to Cognilytica, organizations spend more time labeling data than on any other stage of machine learning projects. This is because data labeling is a non-trivial task that requires careful planning and attention to detail.
If done incorrectly, mistakes at the labeling stage will lead to a “garbage-in-garbage-out” situation, resulting in AI failure. The labeling process varies according to the domain, use case, and the type of data you are dealing with.
In this article, we will provide an in-depth overview of the data labeling process for geospatial images.
An Introduction to Geospatial Data
Geospatial data refers to any information that is related to a location on the surface of the Earth. This includes a variety of data sources, such as satellite imagery, photographs taken from drones, and data collected from traffic monitoring devices.
The utility of geospatial data has become prominent in industries such as agriculture, urban planning, disaster response, and even healthcare. These datasets are increasingly being integrated with technologies such as AI and IoT, contributing to the decision-making process in these industries.
The past decade has seen tremendous growth in the availability of geospatial data, thanks to advancements in satellite technology and remote sensing. Companies like SpaceX are launching an increasing number of Earth observation satellites, increasing the volume of geospatial datasets available to us.
Applications of Geospatial Data
Geospatial data has a wide variety of applications in domains such as:
- Urban Planning

Urban planning is the process of developing cities and towns to meet the requirements of a community. This includes establishing guidelines for land use and building structure, developing transport infrastructure, and designing visually appealing landscapes.
This process relies heavily on the availability of geospatial data since it helps urban planners understand the current layout of regions and population distribution.
For example, geospatial imagery allows urban planners to visualize existing land areas that lack public utilities. This data can then be used to aid in equitable urban development, as planners can then cater to underserved regions.
2.Remote Sensing
Remote sensing is the process of acquiring information from the Earth or other planetary bodies from a distance, using satellites or aerial sensors. This data is collected by organizations like NASA and SpaceX and is used to make informed decisions based on the current state of our planet.
For instance, phenomena such as deforestation or the shrinking of glaciers can be monitored when observing specific regions over time, and appropriate measures can be taken to address these issues, such as policy enforcement and infrastructure planning.
3.Healthcare

Geospatial data also has a variety of applications in the healthcare industry - it can be used to track the spread of diseases over time, analyze the relationship between environmental factors and health conditions, and inform the planning of healthcare services.
During the Covid-19 pandemic, for example, geospatial data played a crucial role in identifying disease hotspots and tracking their spread globally. This aided both local governments and international organizations in coming up with strategies for disease control, like where to distribute vaccines and initiate testing efforts.
Furthermore, non-profit organizations such as the Bill and Melinda Gates Foundation also heavily utilize geospatial data to implement polio eradication strategies.
The Role of Geospatial Data Labeling
Geospatial data must be annotated before it can be used for the tasks described above. For instance, disease outbreaks that are tracked must be enriched with demographic and epidemiological information before they can be used to formulate response strategies.
Another example can be seen in the urban planning industry. Land areas must be labeled to differentiate between various landscapes, available utilities, and infrastructure before city planners can use the geospatial data to make informed decisions.
Typically, a labeling project like this should involve a specialist who has some exposure to the field of geospatial imagery. This might include expertise in spatial concepts, computer vision, the ability to work with domain-specific datasets and familiarity with data annotation tools.
Different approaches can be taken when performing geospatial annotation, such as manual, automated, and semi-automated labeling. These approaches will be discussed in more detail in the next section.
Understanding Geospatial Images: A Deep Dive
Types of Geospatial Images
As you already know by now, geospatial imagery has applications in a wide variety of domains. Different types of geospatial images capture different data points, which have unique applications across multiple industries.
In this section, we will delve into four prominent types of geospatial imagery and understand their roles in different domains:
1.Satellite Imagery:

Satellite images are one of the most widely-used types of geospatial technologies. These are images of the Earth collected by satellites operated by governments and organizations such as NASA and SpaceX.
The image displayed above showcases the crumbling of sea ice in the waters of Northern Canada, as captured by NASA's Aqua satellite.
Satellite imagery is widely used in weather prediction, tracking climate change, landscape analysis, and regional planning. Deforestation, natural disasters, and any major changes that take place on the Earth’s surface can be monitored using satellite images.
Before they can be used to make informed decisions, however, satellite images must be labeled with additional features like landscape type, water bodies, and forests. Labeling satellite images can be time-consuming since in some cases, they require the presence of a domain expert who has expertise in specific fields such as geology.
However, this task is being made increasingly easier due to the presence of open-source datasets in this domain.
SpaceNet, for example, is a project that aims to accelerate the open-source development of AI applications in the geospatial industry. The company provides a wealth of publicly available datasets with labeled satellite images. Industry experts created these annotations and can be used by researchers and developers to train machine-learning models from scratch.
The datasets provided by SpaceNet, however, are generic, and broad categories such as buildings and roads have been labeled. Researchers who want to work on more specialized tasks, like identifying a specific road or building within a region, can take the SpaceNet dataset and customize the annotations to their use cases.
2.Aerial Imagery:

Aerial images are taken by drones and airplanes flying above the Earth’s surface and are typically of higher resolution than satellite images. These images are widely used in domains like urban planning and agriculture to provide details of infrastructure, land use, vegetation, and crop health.
The labeling process in aerial imagery usually involves identifying specific structures, such as buildings, residential areas, and roads. These detected objects are then annotated directly within the image.
Again, this labeling process is not solely an automated task and requires some degree of human oversight and domain expertise. For instance, an agricultural expert will be able to classify different crop species accurately in aerial imagery or identify signs of potential disease when these nuances might go undetected by an automated system.
3.LiDAR Imagery:

LiDAR (Light Detection and Ranging) is an application that is used to create detailed representations of the Earth’s surface. It is also known as “3D scanning” because it provides a three-dimensional environment representation. This allows for a more detailed analysis of a landscape’s elevation and depth, which are data points that cannot be gleaned from regular 2D representations like satellite and aerial imagery.
Due to this, LiDAR images are used extensively in the field of geology, as they provide detailed information about the shape, volume, and elevation of landforms. They can also be used to observe landscapes over time and track changes with a high level of precision.
For example, coastal erosion is a phenomenon that occurs when land is broken down and displaced along the coastline due to destructive waves. With the help of LiDAR data, geologists can get precise measurements as to the amount of soil that was lost and how much of the coastline has been displaced, which will aid in developing strategies to mitigate this erosion.
The LiDAR image annotation process can be more complex than labeling satellite imagery and aerial photographs due to the three-dimensional nature of this data. These datasets often contain millions of data points that need to be classified, and the annotation needs to consider the spatial relationship between individual points.
Furthermore, identifying individual features in LiDAR datasets can be challenging, as it isn’t as straightforward as detecting buildings and roads in 2D aerial images. In contrast, LiDAR imagery is three-dimensional and does not capture color and texture, making it difficult to distinguish between objects.
It can be complex and time-consuming to annotate LiDAR imagery, and the process relies on a high degree of technical expertise. A professional working with these datasets must have some experience with specialized 3D processing tools, along with knowledge of spatial data analysis.
Data Labeling Techniques for Geospatial Images
Accurate labels must be assigned to geospatial datasets, as inaccuracies introduced during the labeling stage can have a domino effect, causing inconsistencies in the subsequent stages of data analysis.
If this compromised dataset is used to build an AI algorithm - such as a predictive model meant to forecast polio outbreaks - the resultant model will be unusable.
The mislabeling of geospatial images can occur for several reasons, such as labeling bias, lack of specific knowledge about the objects being labeled, and failure to validate labeled data for inconsistencies.
Case Study 1
Here is a case study of how a lack of industry expertise led to the systemic mislabeling of geospatial data:

A study published in 2017 focused on the automated classification of earthquake damage using geospatial images.
The object detection model that was trained on these images, however, ended up making systemic prediction errors. These inaccuracies arose because the images used to train the model were annotated incorrectly.
The algorithm learned from these mistakes and incorporated them into its predictions.
The prediction inaccuracies were caused because the labelers had misclassified what to identify as rubble in the images, which may have happened because the labeling process was undertaken by non-experts who lacked the necessary understanding to identify earthquake damage accurately.
Systemic prediction mistakes like the above can have serious real-world implications. In the case of earthquake damage assessment, inaccurate object detection can lead to a misallocation of relief resources, thereby diverting attention from truly affected areas.
This example underlines the importance of accurately labeling geospatial data.
Organizations must establish a comprehensive plan for carrying out data annotation tasks, as inconsistencies at the labeling stage can have significant repercussions on the resultant machine learning model and data analysis.
A key component of this plan includes deciding on an appropriate data labeling technique, resource allocation, and assessing the complexity of the task at hand.
In this section, we will outline three of the most commonly-used data annotation techniques for geospatial image annotation:
Manual Labeling
This is a traditional data labeling approach that involves human annotators assigning annotations to features within an image.
Many organizations choose to perform manual labeling with an in-house team of annotators, as they prefer to assign the task to their employees.
One advantage of this approach is that the company’s sensitive data remains secure and never has to leave the company’s premises. Furthermore, a trained employee will have company-specific knowledge and domain expertise, which means that the labels generated will be of high quality.
However, manual labeling is an incredibly time-consuming task and can potentially exhaust the human resources available within the organization. An employee’s time is better spent on performing creative tasks that leverage their unique expertise, and tasks like data annotation can end up wasting the team’s time.
Another approach many companies take is outsourcing the manual labeling task to a third party, such as a freelancer or an external vendor. However, this will also be a time-consuming process and comes with the risk of compromising sensitive company data.
Case Study 2
HGH is a company that designs electro-optic systems for civil and defense applications. The company provides a compelling case study on the complexities of hiring external vendors to annotate geospatial data.
In the initial stages, the organization hired interns to label videos and images that were collected with the help of drones. However, this task quickly became more complex than anticipated and revealed a series of limitations.
Firstly, since the interns hired were students, they were only available on school holidays, which meant that the task did not progress as quickly as it should have. Furthermore, the images that had to be labeled were complex and required some domain expertise to process.
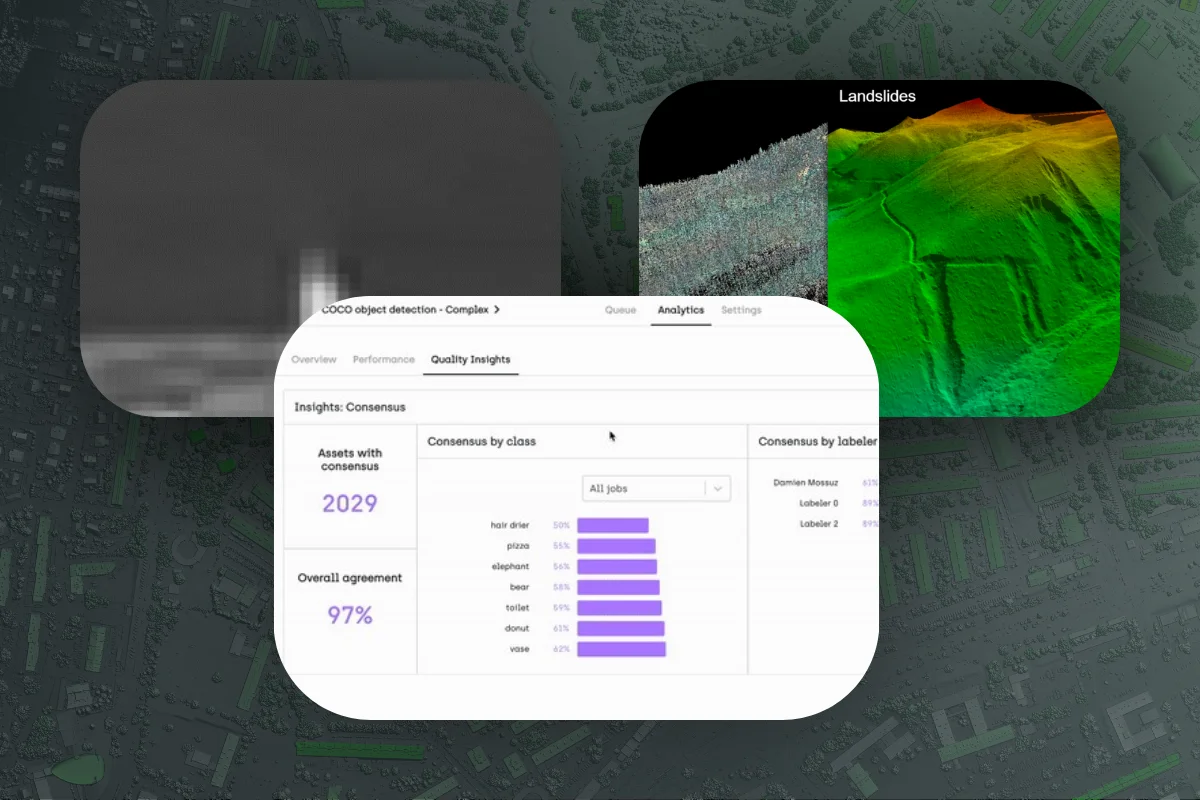
Here is an example of the type of visuals that the organization had to annotate:

Only a light bump is visible, making it difficult to identify the object in the image. It takes experience, and the labeler would have to look at multiple frames before figuring out that this is a moving object (a sailing ship), and not a wave or bird.
This complexity calls for a level of expertise that an intern or freelance vendor may not possess and underlines the crucial role that domain experience plays in the data annotation process.
Ultimately, HGH decided to use a data annotation tool to meet its annotation requirements, which allowed the company to find a balance between correctness and speed of labeling. This led to a rapid increase in the quality and volume of labels generated, and the organization saw a 30% increase in the amount of labeled data produced.
Automated Labeling
In this approach, a machine learning algorithm performs the entire labeling workflow with no human intervention whatsoever. This method can handle large amounts of data quickly and dramatically reduces the amount of human resources required for annotation.
However, AI models need to be trained with large volumes of labeled data before they can accurately label images on their own. The lack of human involvement also means that domain expertise will not be integrated into the labeling process, which can lead to error.
Furthermore, algorithms can only make predictions on scenarios they have been trained on, which means that they will not be able to handle edge cases and new imagery.
Semi-Automated Labeling
Semi-automated labeling is an approach that allows organizations to find a balance between speed and quality of annotation.
This technique typically involves training an AI algorithm to generate initial labels, but the final decision is made by human annotators who validate model output and correct the machine’s mistakes.
Since this technique capitalizes on the speed of machines and the decision-making ability of human annotators, it is the ideal approach for annotating geographical information.
Data annotation platforms enable organizations to perform seamless semi-automated annotation since they provide labelers with features that accommodate initial model-generated annotations along with human review capabilities.
For instance, these platforms provide pre-labeling functionalities that allow AI models to come up with initially proposed labels. Then, they also provide quality management features that allow reviewers to easily assess and correct model-generated labels, and compare the quality of annotations with the ground truth.
Challenges in Geospatial Data Labeling
Labeling geographical information presents a unique set of challenges that set this task apart from regular data annotation tasks. In this section, we will dive into potential hurdles you may face when labeling location-based data:
- Volume and Complexity of Geospatial Data
Geographical data often contain various elements, such as buildings, water bodies, and vegetation, in a single frame. This can be time-consuming to label since every element needs to be labeled differently, with a high level of detail.
For instance, when labeling urban images for urban planning, a single image can contain various types of buildings, roads, and water bodies that need to be labeled individually. Even within a single category like buildings, the labeler may need to include detailed characteristics like its height or the number of floors.
Furthermore, each pixel in aerial images corresponds to specific locations with their own coordinates. This means that individual objects within this image need to be mapped to their location in the real world, which adds another layer of complexity to the annotation process.
To ensure that the labeled data is accurate and can be used in real-world decision-making, there needs to be careful planning and attention to detail at every stage of the labeling workflow.
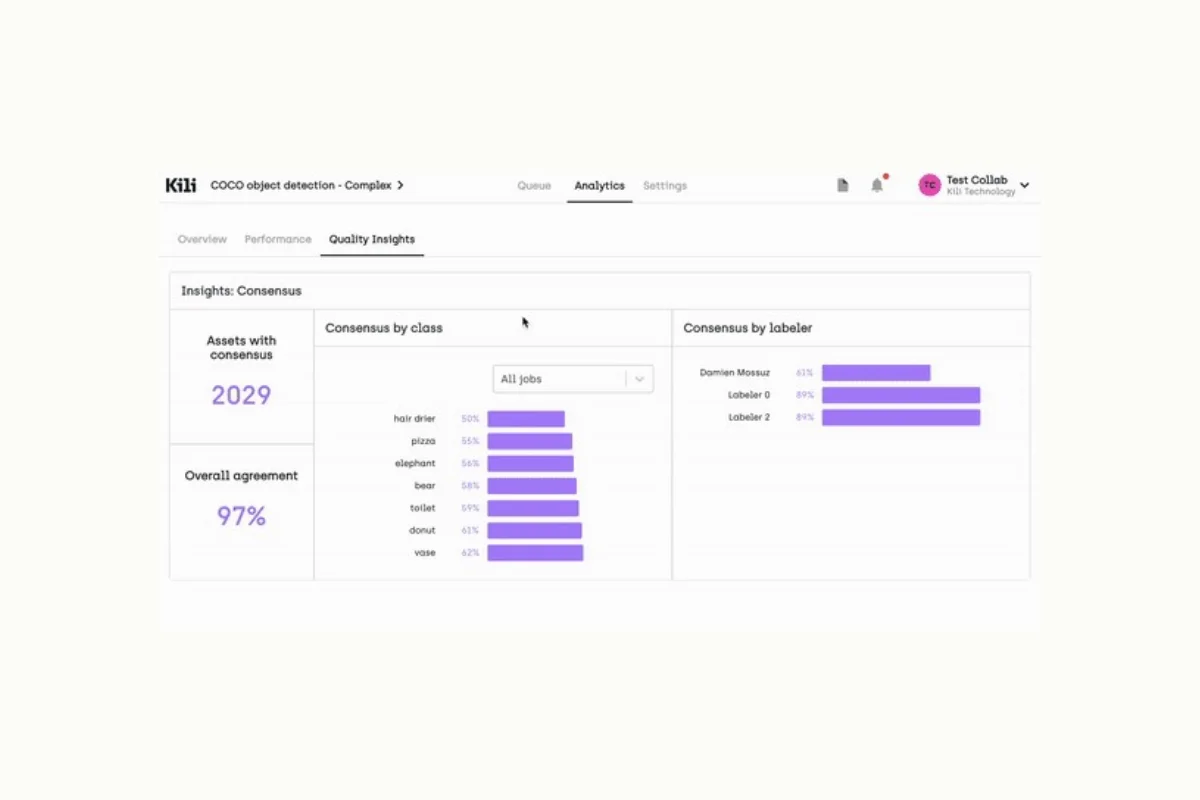
2. Quality Control and Efficiency
Since geospatial information is highly complex and contains a large variety of elements, it can be difficult to find a balance between correctness and labeling efficiency.
A recommended approach to maintain an accuracy and efficiency trade-off is to perform a semi-automated labeling process with the help of a data annotation process.
This way, a trained AI model can be implemented for initial label generation, after which a human reviewer can perform multiple consensus-based reviews using the labeling platform’s quality management features.
3.Handling Variability of Geospatial Images
Geospatial images can appear different during different seasons, times of the day, and the angles at which they were captured. This can pose a challenge when using automated machine learning models to label images since these algorithms must be trained on diverse data samples that reflect various conditions.
For instance, a landscape that is visible in bright sunlight will become harder to see at night, and conditions like haze or fog can obstruct certain features in the image. The model must be able to capture individual objects regardless of lighting conditions and angles.
It simply isn’t possible to cover all possible edge cases when feeding an AI model with image samples, which is why a human reviewer must be present to enhance the quality of algorithm-generated labels.
4. Dealing with Dynamic Geospatial Features
Geospatial images capture landscapes and regions on the Earth’s surface that are constantly changing, which necessitates regular updates to the existing training data.
For example, an area that might have been a forest three years ago could be a residential district today, and this would require continuous amendments to labels that were previously generated.
There has to be continuous monitoring of regions that have previously been labeled, and the annotation workflow must be flexible enough to accommodate changing existing labels or adding new features to an existing frame.
Again, organizations would benefit from using a training data platform to create a flexible, streamlined annotation workflow that can be regularly monitored and updated over time. This platform must preferably contain version control features that allow labelers to keep track of changes made to the dataset, allowing them to revert to previous versions whenever needed.
5.Geometric Distortion
Geospatial images, particularly aerial and satellite images, tend to suffer from geometric distortion. This occurs because the perspective from which images are taken can result in the misplacement of objects relative to their actual position in the real world.
Due to this, objects in geospatial images can appear smaller than they are in reality.
Orthophotography can be used to mitigate this challenge. This is a process in which image distortion is corrected by aligning the final image correctly with real-world coordinates.
However, orthophotography poses another issue: The resultant images from this process cannot be treated as regular image files since they contain geo-coordinates. These files have different formats since they contain spatial information.
A training data platform that can handle geospatial files will help organizations effectively label complex geographical objects and handle large volumes of data efficiently.
Choosing the Right Geospatial Image Labeling Tool
Watch video
As highlighted in the previous section, many of the challenges faced when labeling geospatial data, such as complexity, variability, and geometric distortion, can be mitigated with the help of a data labeling tool.
However, it is crucial for organizations to choose the right tools to meet their annotation needs. This is because a platform that is unable to process and efficiently manage geospatial data could lead to a waste of valuable time and money.
In this section, we will highlight three key features you should look for when choosing a geospatial image labeling tool:
1.Support for Various File Formats
The tool of choice must be able to read and write geospatial file formats such as GeoTIFF, Shapefile, and KML, as they contain geographical objects that regular image files do not have.
2.Ability to Handle Large Datasets and Multiple Labeling Projects
Since geospatial data is often larger than regular image files, the software should be able to handle large volumes of data without slowing down or crashing.
This becomes even more critical when labelers are working on various annotation tasks simultaneously. Organizations must ensure that the data labeling tool of choice not only supports multiple labeling projects but also allows for effortless access and transition between these tasks.
3.Asset Navigation
Geospatial files are massive and complex, and the platform of choice must make it as easy as possible for users to zoom in and move around different sections of the image. These navigation features should enable labelers to handle files in real-time.
Employees should be able to perform object detection on small items within the image without experiencing a dip in geospatial data quality or any significant delays in processing time.
4.Advanced Display Settings
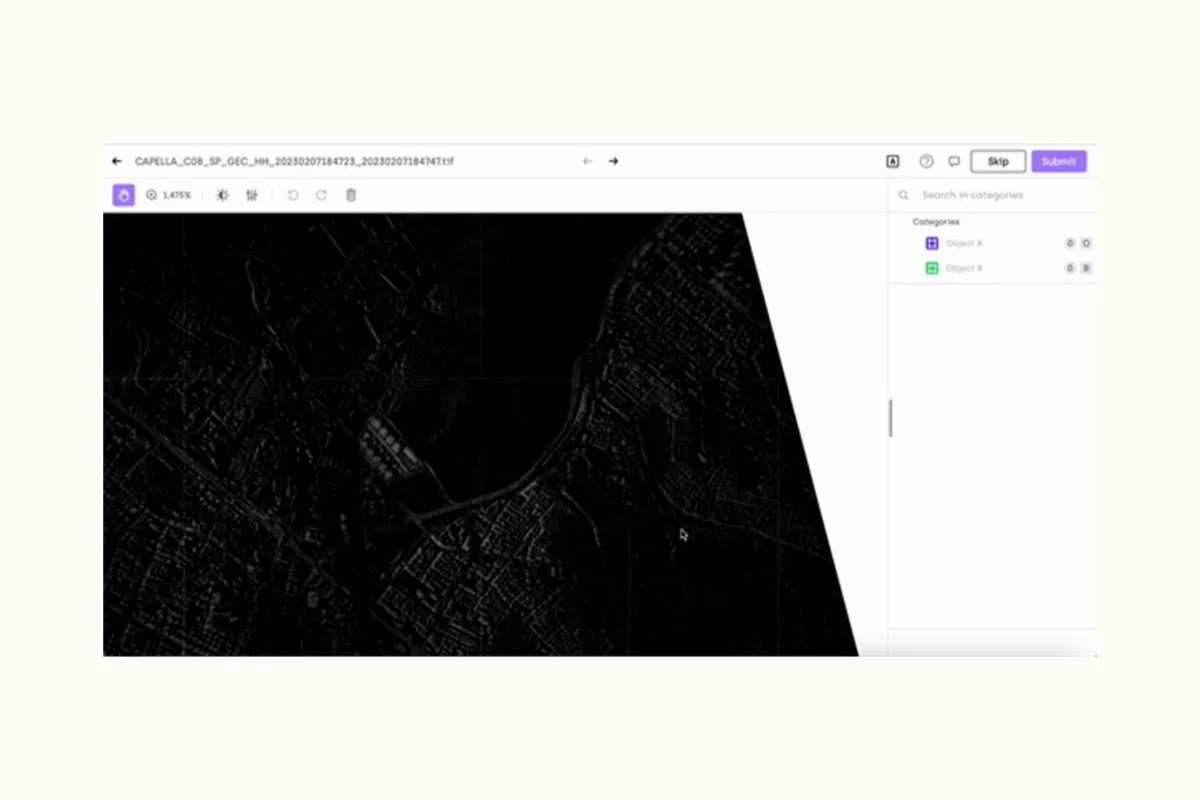
When annotating geospatial data, you might find the need to improve the visibility of certain objects within the image. The labeling tool you select must have features that allow users to manipulate image parameters such as brightness and saturation.
For example, Synthetic Aperture Radar (SAR) images, which is an emerging technology that allows users to create 2D or 3D reconstructions of objects, may need to be adjusted for better interpretability.

The ability to tweak parameters within these images will help labelers to clearly identify features that need to be annotated and can greatly enhance the accuracy of bounding box placement under different lighting conditions.
Furthermore, spatial resolution often differs based on the source of geospatial data, and a good labeling platform must be able to handle varying resolutions.
5. Machine Learning Assistance
Semi-automated data labeling is an ideal method for annotating geospatial data, as it provides a balance between efficiency and precision.
The training data platform you select must have functionalities to help your team improve the quality of AI-generated labels. This includes AI review features to compare the model’s output with the ground truth.
Furthermore, if mislabeling takes place due to a lack of training samples for a specific class of objects, the software must have quality management features that highlight this discrepancy, allowing the team to act quickly and seamlessly including new samples.
Conclusion
Accurate and detailed labeling of geospatial data is essential for training machine learning algorithms and generating reliable predictions. However, the complexity, volume, and variability of geospatial images present unique challenges in the labeling process. It requires domain expertise, attention to detail, and the ability to handle different file formats, large datasets, and geometric distortions.
Choosing the right geospatial image labeling tool like Kili Technology is crucial for efficient and effective annotation. The tool should support various file formats, handle large datasets and multiple projects, provide asset navigation features, and offer advanced display settings. Additionally, machine learning assistance features, such as AI-generated labels and quality management capabilities, can greatly enhance the efficiency and accuracy of the labeling process.
By addressing these challenges and leveraging appropriate labeling techniques and tools, organizations can harness the power of geospatial data to drive informed decision-making, improve urban planning, monitor environmental changes, and enhance healthcare services. Accurately labeled geospatial data lays the foundation for successful AI and machine learning applications in the geospatial domain, paving the way for advancements and innovation in a wide range of industries.
Watch video