
.png)


_logo%201.svg)


AI Summary
Introduction
Image annotation is the basis and a requirement behind numerous commercial Artificial Intelligence (AI) products on the market, and it is one of the crucial processes in computer vision. It is the critical step to deliver AI in numerous business applications: to automate the processing of vehicle accident images in the insurance sector, to detect vehicles and pedestrians for autonomous vehicles in the transportation sector, to help medical personnel detect cancers on medical images, and much more.
Concretely, image annotation is the process of technically affixing labels to an image or a series of images. This process is used in different machine learning tasks: to classify images, to detect objects in images, and to segment images. The associated labeling task can then take various forms depending on the objective and the model constraints: from one label for an entire image to multiple labels for every cluster of pixels within that image, with many different possible shapes (bounding boxes, polygons, lines, and more).
Why is image annotation so important
Image annotation is the key prerequisite to successful computer vision applications and business value delivery. Indeed, labeling provides the knowledge that will be encapsulated into the AI model during model training. Despite the innovation of alternative computer vision fields (e.g., unsupervised learning), supervised learning relying on image annotation remains the most efficient solution to tackle very complex business problems.
The quality of annotated data directly impacts the performance of AI models, as poor annotations can lead to inaccurate predictions. Data is generally cleaned and processed where low-quality and duplicated content is removed before being sent in for annotation—ensuring that your dataset starts from a foundation of quality before the actual labeling work begins.
This is why leading enterprises invest significantly in building expert AI data—data that's been validated, refined, and enriched by the people who actually understand the domain.
In 2026, AI-assisted workflows commonly employ a Human-in-the-Loop (HITL) model where AI generates initial labels that humans refine. This approach combines the speed of automation with the precision of human expertise, particularly from subject matter experts who understand the nuances of specialized domains like medical imaging, manufacturing quality control, or financial document processing.
Image annotation is a significant investment in AI efforts that requires careful consideration of project size, budget, and delivery time. Whether you're developing computer vision projects for autonomous vehicles, medical image annotation applications, or retail inventory systems, the foundation of your success lies in high-quality annotated data.
What Are Different Image Annotation Applications?
Many current applications leverage image annotation, and the most influential use cases spanning the major industries are as follows:
Insurance
Insurance companies process a large number of images from accident photos to scanned accident reports. The processing of this data can be automated by annotating accidents on car images to detect the severity level, or by correctly extracting handwritten content with a custom optical character recognition (OCR) model. Annotation tools help create the training data needed for these AI models to perform accurate pattern analysis on claim documentation.

Transportation
With the increasing demand for transportation in a fast, accurate, and ecological way, computer vision applications have become numerous in the sector, leading to very large image annotation needs. Self-driving cars rely on computer vision models trained with correctly labeled images to detect objects in the picture and classify them. Object detection models must identify vehicles, pedestrians, traffic signs, and lane markings with pixel-perfect accuracy. Similarly, image annotation of vehicles can be used to estimate city traffic flows through detection tasks that track movement patterns over time.
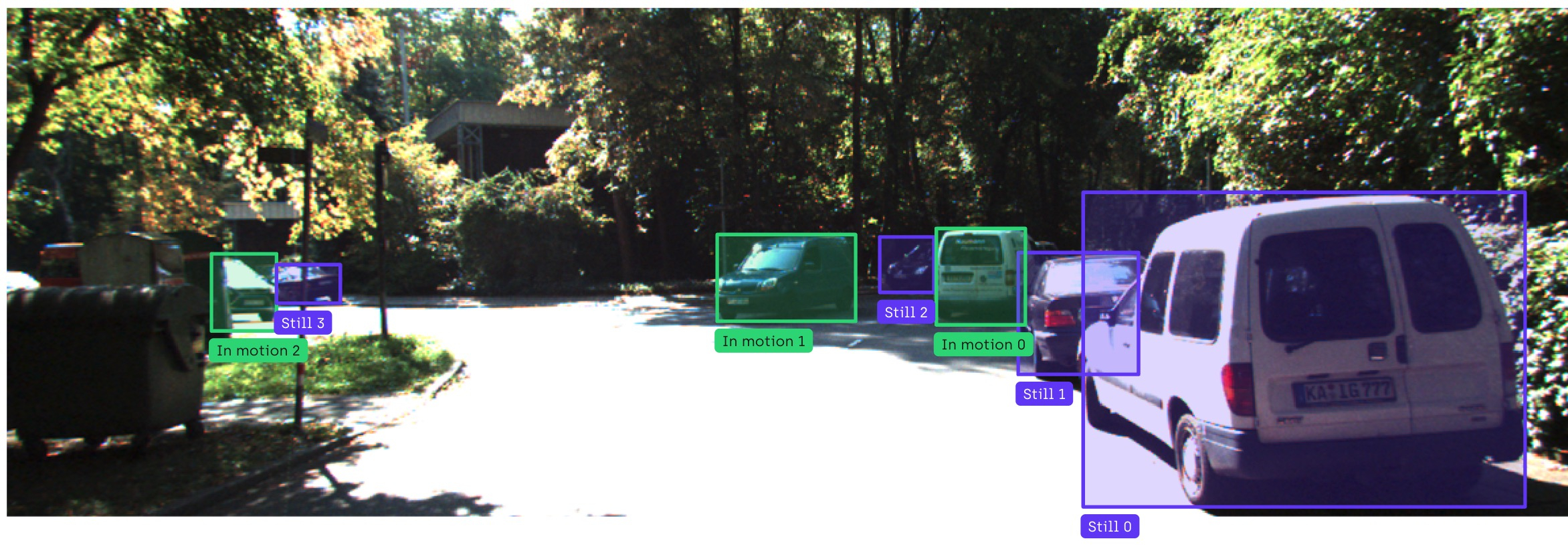
Manufacturing
Manufacturing businesses utilize image annotation to provide real-time information about inventory levels within their warehouses. Trained computer vision models can evaluate stock image data to decide if or when a product might soon be out-of-stock and needs replenishing.
In addition, specific manufacturers use image annotation to monitor key infrastructure elements within their plants. Teams digitally label images of their vital equipment components, information which can then be used to detect defects or to automate traditional visual inspections. For one of Kili Technology's manufacturing customers, enabling quality engineers to validate and refine AI models directly resulted in 5x productivity gains compared to their internal solution—demonstrating how expert AI data, validated by subject matter experts, delivers superior results.

Health and Healthcare
AI-powered applications enable augmented diagnostics for medical personnel, supporting them in their day-to-day job. Medical image annotation is critical for training computer vision models that examine medical imaging (X-ray, CT scans, MRI) to identify the probability of potential disease being present. Medical teams can train a computer model using a multitude of MRI scans labeled with both cancerous and non-cancerous zones until the computer vision model can accurately learn to differentiate them on its own.
Polygons outline irregular shapes with multiple vertices, commonly used for segmenting complex objects like buildings or tumors in medical imaging applications. This level of precision in annotation is essential when the stakes are as high as patient health outcomes.
Tracking of movements also has value for medical applications to detect neurological pathologies and facilitate medical recovery. This requires specific annotation using pose estimation to enable computer vision models to track human movements through key points on the body.
Privacy-first datasets involve techniques that automatically obfuscate sensitive details during the annotation process to comply with data privacy standards—particularly important in healthcare where patient confidentiality is paramount.
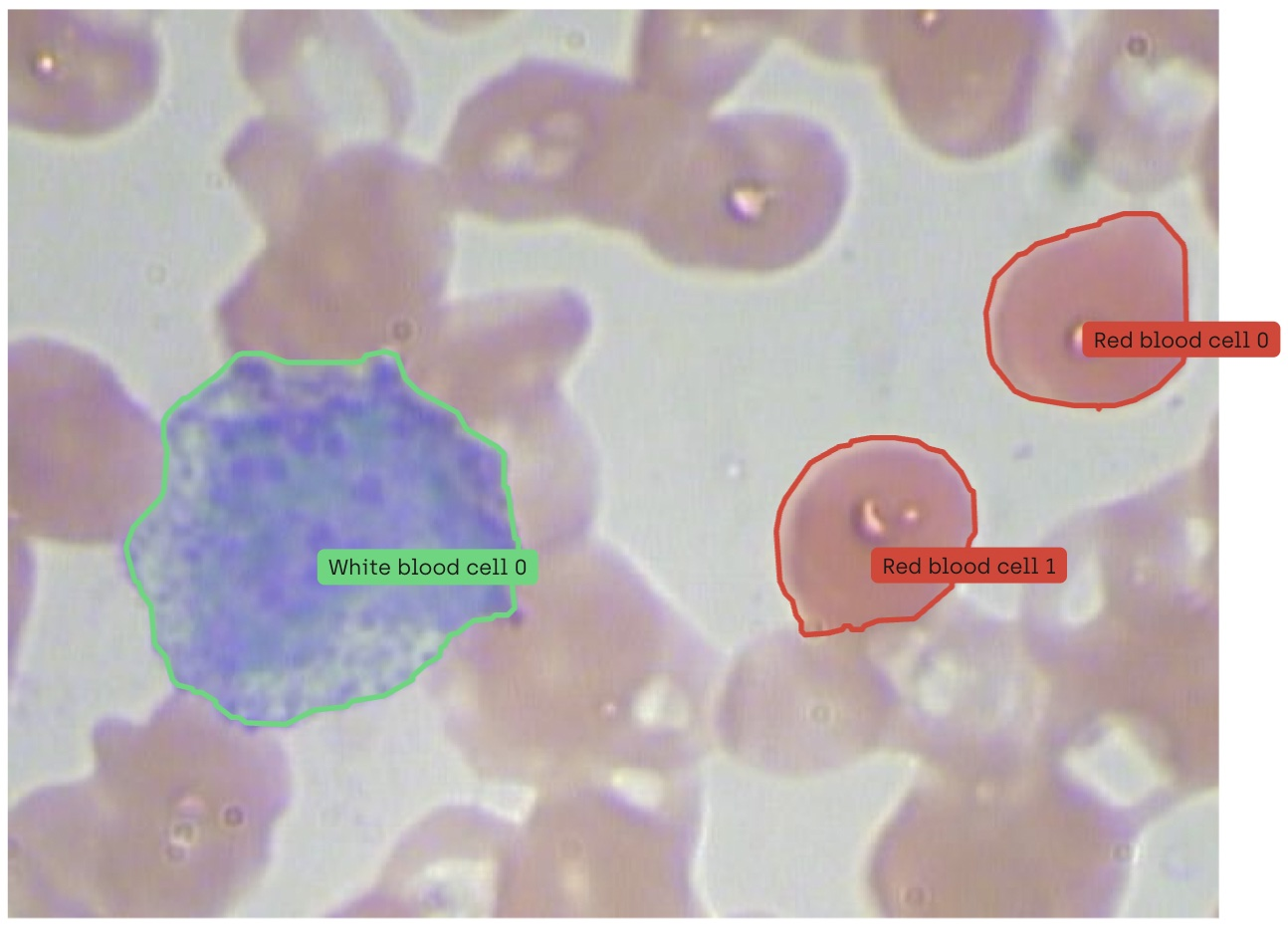
Agribusiness
The agriculture industry utilizes AI, video or image-based, for a myriad of benefits:
- Estimating future crop yield
- Evaluating soil content
- Planning for future agricultural expansion
- Developing autonomous vehicles & machinery
- Automating landmarking
One farming business annotates still-shot digital images using semantic segmentation to distinguish between weeds and crops—right down to the pixel level. This annotated imagery is then used to apply chemical pesticides to those areas only where weeds are growing, rather than sprayed onto the entire field. This process reduces chemical weed spraying, saving significant amounts of money on pesticides yearly.

Finance and FinTech
Banking and finance companies use facial recognition technology to verify the identity of their customers withdrawing money from their ATMs. This is accomplished through what is called a pose points image annotation process, which digitally maps key facial features such as eyes, nose, and mouth. Consequently, facial recognition presents a more direct and precise method of defining identity, reducing the prospect of fraud.Banking and finance companies use facial recognition technology to verify the identity of their customers withdrawing money from their ATMs. This is accomplished through pose estimation annotation, which digitally maps key points on facial features such as eyes, nose, and mouth. Facial recognition presents a more direct and precise method of defining identity, reducing the prospect of fraud.
Banks and insurance companies are progressively enabling business experts to test and validate model outputs—bridging the gap between data science and business reality. Instead of data scientists guessing what underwriters need, underwriters validate it directly. This results in faster iteration, better machine learning models, and AI that actually solves business problems.
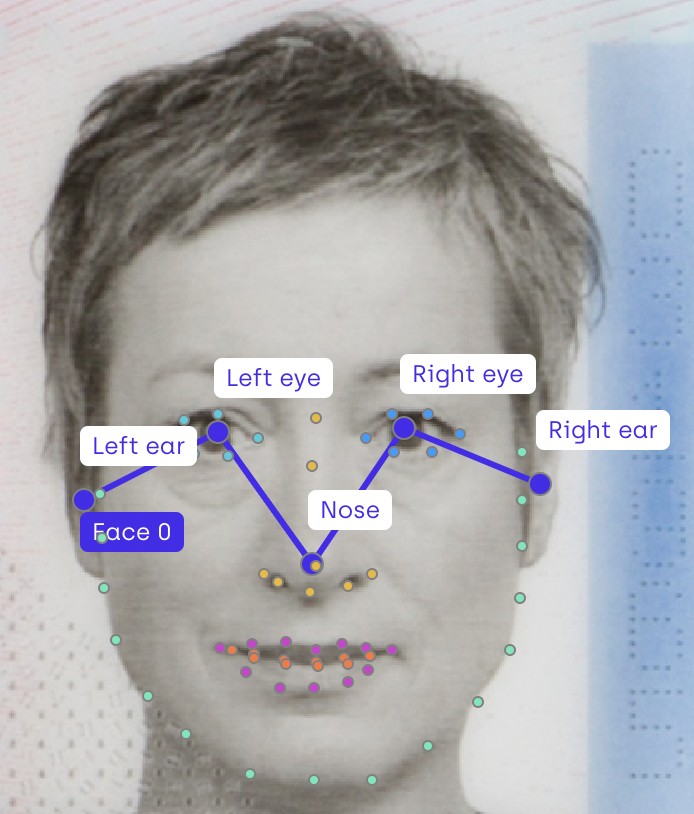
Retail
Image annotation is required to build a computer modeling system to examine an entire product catalog and administer the end user's results. Retailers are also piloting image annotative systems within their stores. These systems periodically scan and manage digital images of product shelves to decide if a product is close to running out of stock, revealing that it requires reordering. These systems can also check and scan barcode images to collect product information using what is known as image classification, which is a key method used for digital image annotation – which will be discussed further below.

Labeling in the retail sector
Drone/aerial imagery
The development of drone technologies has seen applications in various industries, reducing the cost of complex visual inspections. This development came with the production of a lot of image & video data, on which AI systems can be applied. Geospatial image annotation involves working with specialized image data captured from satellite, aerial, or drone sources, requiring tailored approaches and annotation tools for effective labeling.

Security and surveillance
Various computer vision use cases are valuable in the sector—for example, to automate the detection of hazardous situations and potentially raise security alerts. For these use cases, CCTV images can be used for image annotation, training object detection models to identify specific objects, people, or behaviors that warrant attention.

Robotics
The robotics sector relies on computer vision for the autonomous evolution of the robot in its own environment. This requires strong labeling efforts of images to tackle all possible situations that the robot can encounter and deal with particular sector constraints (e.g., depth estimation challenges for object grasp). The applications of computer vision are wide in the sector: from the space industry to industrial and medical applications.

What are the different types of image annotation?
What Are the Different Types of Image Annotation?
As described earlier, image annotation is the process of annotating target objects within a digital image's region of interest. This is performed to train a machine to recognize objects under the same classes in unseen images and visual scenes. However, this method can be quite challenging because there are different approaches to developing deep learning model architectures and techniques for training a machine to accomplish this task.
Indeed, image annotation can be leveraged to fulfill various annotation types and computer vision tasks:
Image Classification: The simplest form of image annotation where a class label (e.g., presence of a given object) is attributed at the entire image level. Classification involves labeling the entire image, while object detection involves drawing boxes around specific objects.
Object Detection: Detection of an object in an image, with the identification of the location and the category of the associated object. You can train object detection models to identify and locate multiple objects within a single image.
Segmentation: Refers to dividing the various parts of an image into categories.
- Semantic Segmentation: A specific subclass of segmentation where each pixel of a picture is attributed to a given category, hence leading to the establishment of various pixel-based regions in a picture. In this case, multiple objects will be treated as one category.
- Instance Segmentation: A specific subclass of segmentation where, as opposed to semantic segmentation, objects are treated individually—allowing you to distinguish between multiple instances of the same class label.
- Panoptic Segmentation: Combines semantic and instance segmentation by classifying all pixels in the image and identifying which instances they belong to. This comprehensive approach provides complete scene understanding.
To fulfill the above roles, various image annotation shapes may be required:
Bounding Boxes
This is a simple yet versatile type of image annotation, and the primary reason why this method is among the most widely used techniques to annotate images in a dataset for a computer vision application's deep learning model. As its name implies, objects of interest are enclosed in bounding boxes—rectangles defined by coordinates that specify the location of the object.
On Kili, yo annotate using a bounding box, select an object class and then click and drag the cursor on the asset, or select annotation vertices with two mouse clicks. Bounding boxes can be used together with tasks like object detection, transcription, classification, and semantic segmentation.
Polygons
Polygons are used in place of simple bounding boxes for more precise image annotation. This method increases model accuracy in terms of finding the locations of objects within a region of interest in the image, and improves object classification accuracy. Polygons remove the noise around the object of interest—the unnecessary pixels around the object that tend to confuse classifiers.
You draw polygons by placing multiple points to create shapes that closely follow the contours of irregular objects. This is commonly used for segmenting complex tasks involving buildings, tumors, or any object with non-rectangular boundaries.
Semantic Segmentation
This is the most precise type of image annotation since the annotation comes in the form of a mask attributing a category to a given object on an image at the pixel level. The task of image semantic segmentation consists of detecting specific regions of objects within an image. In image segmentation, the goal is not only to identify the presence of given objects but also to identify their positions, dimensions, and shape through work at the pixel level.
Modern annotation tools like Kili Technology provide interactive semantic segmentation powered by SAM 2 (Segment Anything Model 2), which allows annotators to create high-quality segmentation masks with just a few clicks rather than manually drawing every pixel.

3D Cuboids
This is an image annotation method commonly used for target objects in 3D scenes and photos. The difference between this method and bounding boxes is that annotations for this technique include depth, not just height and width coordinates.
Line Annotation

Lines and splines are used for this image annotation method to mark the boundaries of a region of interest within an image. Polylines are used to annotate line segments such as wires, lanes, and sidewalks. This method is often used when regions of interest containing target objects are too thin or too small for bounding boxes. You can draw lines by placing points along the path of the object being annotated.
Landmark Annotation
Line annotation in Kili Technology
Also known as dot annotation, this method uses key points as annotations around target objects. This is frequently used for finding and classifying target objects surrounded by or containing much smaller objects. You place points at specific locations to mark features of interest.
Pose estimation
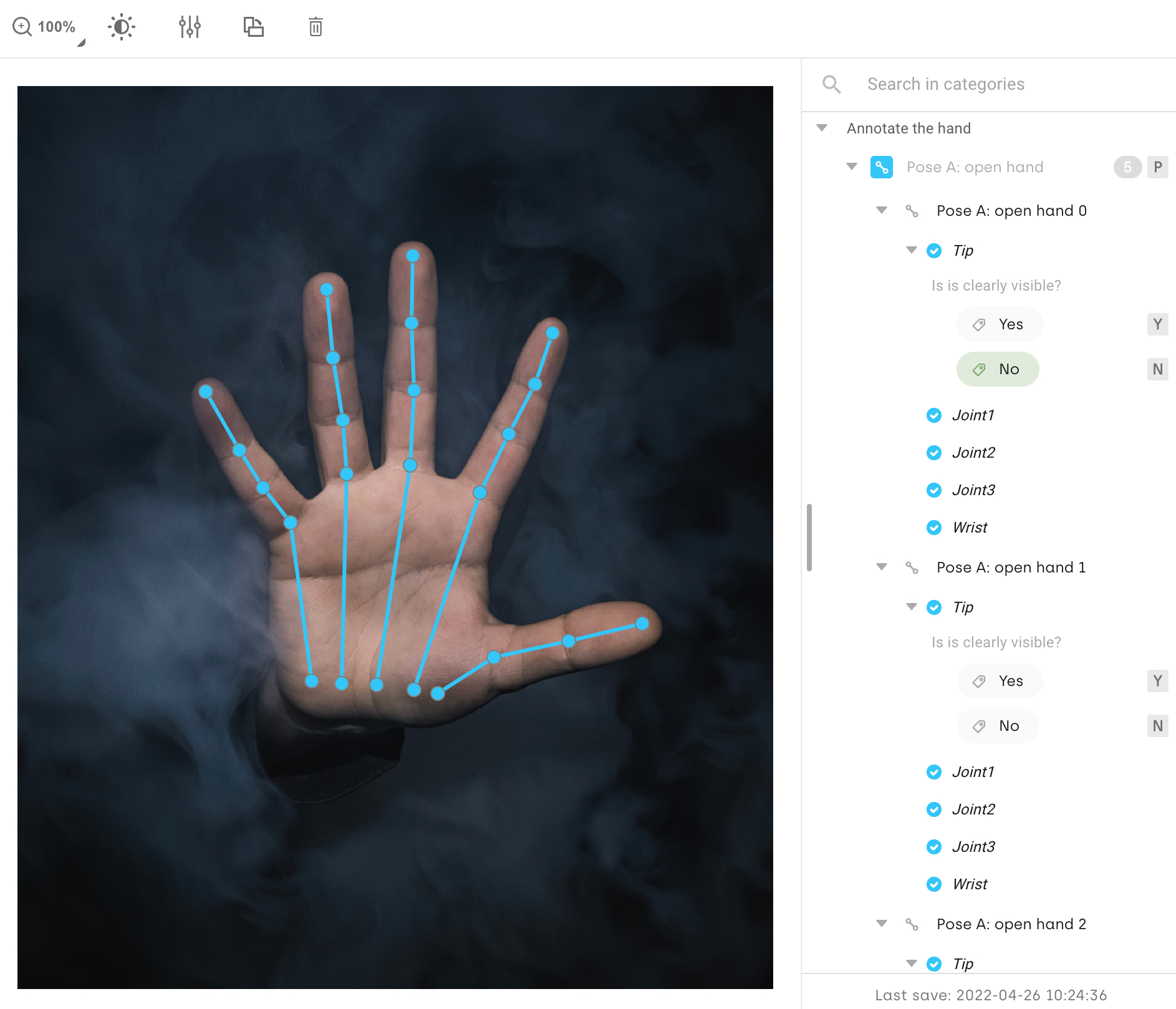
Pose estimation combines key points and lines, with specific knowledge encapsulation related to the order of the associated points. This can be particularly useful in the medical sector to track body movements: typically a human arm movement can be tracked with three main points: shoulder, elbow, and hand.
Pose estimation annotation is about detecting the position and orientation of an object. You can set up categories and pose points, deciding if each point is mandatory or optional. When you place a point on the image, this automatically triggers the selection of the next point in the pose list, helping you annotate faster.
OCR Annotation for Scanned Documents

Scanned documents are images from which we can extract the characters to be processed by a computer using Optical Character Recognition (OCR) methods. This type of task requires combining a bounding box to locate a phrase on a document with a transcription task to extract the associated content.
What Do You Need to Annotate Images?
Four key elements are required to start your image annotation task: 1) a diverse set of images representing reality, 2) trained annotators to fulfill the task, 3) a suitable annotation platform to achieve the project goal, and 4) a project management process to avoid pitfalls.
Diverse Images
Diversity of the images to label is key for the model to behave correctly. The first diversity to reach is the correct balance in terms of class: if you are trying to detect cars & motorbikes on road images, your model needs to be trained on a significant amount of both of these categories.
In addition, diversity among classes is also important to cover all potential situations that the model may encounter in the future. For example, when detecting road vehicles from CCTV, it will be important to have class diversity (cars but also trucks, motorbikes, bicycles) and external condition diversity (day, night, sun, rain). Your dataset should include examples that represent the full range of scenarios your model will encounter in production.
Suitable Annotation Platform
A suitable image annotation tool is key to delivering a labeling project fast & efficiently. Many solutions are available: from in-house development or open source tools to enterprise platforms. Important dimensions to assess for the selection are:
- Productivity: How quickly can annotators complete labels? Does the tool support model assisted labeling to accelerate work?
- Quality: What quality management features exist? Are there consensus and honeypot capabilities?
- Project Management: Can you track progress, manage users, and coordinate workflows at scale?
- Security: Does the platform meet enterprise requirements? Is on-premise deployment available?
- ML Ops Integration: Can you export data in COCO format and other formats? Does it integrate with your existing infrastructure?
Open source software options like Label Studio and CVAT provide basic annotation capabilities, but enterprise platforms offer additional features for collaboration at scale, security compliance, and advanced automation.
Manual labeling involves human annotators using tools to draw boxes, shapes, or highlight pixels around objects and assigning categories. But modern annotation tools also provide active learning capabilities and model-based pre-annotation to speed up the process.
Trained Annotators and Subject Matter Experts
Trained annotators will do the work—they can be in-house or outsourced depending on the project needs and the complexity of the underlying task. Training the workforce is important at the beginning of a project: this has to rely on extensive annotation guidelines including examples & describing edge cases. Then, a test/train project can be used with a review step to make sure the labeling team has the correct understanding of the task.
The most successful AI projects go beyond generic annotators to involve subject matter experts—the radiologists, engineers, underwriters, and quality inspectors who truly understand what "good" looks like in their domain. When radiologists validate diagnostic AI, when underwriters refine fraud models, when engineers improve quality inspection —they're building expert AI data that performs better in production.
Labeling workforce expertise level can be raised and maintained thanks to small iteration loops and continuous improvement of labeling guidelines. This collaborative approach between data scientists and domain experts is what separates average AI projects from exceptional ones.
Project Management Process
Managing a labeling project is a complex task that needs a dedicated process. This process has to consider the timeline, the team, the requirements, the distribution of the tasks, the manual/automated labeling approach, and quality management.
Multi-step workflows enable structured validation processes where annotations meet the highest quality standards before final approval. Teams can define different review stages, assign specialized reviewers at each step, and systematically validate data with increasing levels of scrutiny.
How Long Does Image Annotation Take?
Image annotation task duration strongly depends on the type of task and the associated complexity. An image classification job can be very fast (less than 1 minute per image) for a basic task when the picture doesn't require too much analysis to have a first decision.
On the other hand, segmentation jobs are the most complex tasks when a very high level of precision needs to be reached at the image pixel level. In this case, the annotation task can reach dozens of minutes per image.
However, these timelines can be dramatically reduced through:
- Model assisted labeling: Use pre-trained models to generate initial annotations that human annotators refine
- Active learning: Prioritize labeling the most informative images that will have the greatest impact on model performance
- Interactive segmentation: Tools like SAM 2 create segmentation masks with just a few clicks rather than manual pixel-by-pixel work
- Smart tracking for video: Automatically propagate annotations across video frames
The combination of automation and human expertise in a HITL workflow delivers both speed and quality—organizations can annotate images much faster while maintaining the accuracy that expert validation provides.
Getting Started with Image Annotation
Image annotation is a significant investment in AI efforts, but the right approach and annotation tools can dramatically improve your outcomes. Here's how to begin:
- Define your use case: What specific computer vision tasks do you need to solve? Object detection? Image classification? Semantic and instance segmentation?
- Prepare your dataset: Ensure you have diverse, high-quality images. Before one can start annotation, data is typically cleaned and processed to remove low-quality and duplicate images.
- Choose your annotation types: Select the shapes and methods appropriate for your task—bounding boxes for detection, polygons for complex shapes, segmentation masks for pixel-level precision.
- Select an annotation platform: Evaluate tools based on productivity, quality management, security, and integration with your ML infrastructure.
- Engage domain experts: The most successful computer vision projects involve subject matter experts who understand your specific use case and can validate that annotations are accurate.
- Implement quality workflows: Use consensus, review stages, and honeypots to ensure your annotated data meets the quality standards your AI models require.
Expert AI data isn't just labeled data—it's data that's been validated, refined, and enriched by the people who actually understand the domain. That's the difference between building AI that works in the lab versus AI that works in the real world.
How Does Kili Support Complex Image Annotation?
Kili Technology is the collaborative AI data platform where industry leaders build expert AI data. The platform has been designed to overcome the challenges linked to image annotation by enabling cross-functional collaboration between data science teams and domain experts throughout the AI development lifecycle.
Collaboration at Scale
Kili's user-friendly interface enables business experts and subject matter experts to participate directly in AI development. Thousands of images can be processed and reviewed with ease by non-technical users through autonomous workflows that don't require constant ML engineer intervention.
Uncompromised Speed and Quality
Organizations using Kili achieve 30% faster delivery time without sacrificing data quality. The platform supports rapid POC development with two-week evaluation and iteration cycles for AI use cases. Quick POC turnaround enables rapid experimentation to validate approaches before scaling.
Enterprise-Grade Capabilities
The platform supports 500+ concurrent users and enables launching 100+ use cases across modalities in months. Key capabilities include:
- Customizable interfaces for all your data annotation types
- Powerful workflows for fast & accurate annotation with model assisted labeling
- Automation tools including SAM 2 for interactive semantic segmentation to speed-up labeling
- Analytics & Reporting to monitor project progress
- Labeling mistake identification & fixing in ML datasets
- Advanced quality metrics including consensus and honeypot to get quality insights
- Issue workflows to spot anomalies and solve errors
- CLI and delegated access to import & export data effortlessly in COCO format and other formats
- Role-based access to manage your team at scale
- Powerful SDK & API to integrate into your MLOps infrastructure & automate labeling
Specialized Annotation Tools
Kili provides comprehensive annotation tools including:
- Bounding box tool for object detection with support for nested classification and transcription tasks
- Semantic segmentation with both standard drawing and interactive segmentation powered by SAM 2
- Pose estimation for tracking body movements and facial features
- Named entity recognition for text and document annotation
- OCR capabilities for extracting text from scanned documents
- Geospatial imagery support for satellite, aerial, and drone images with geo-coordinates
- Video annotation with smart tracking to propagate annotations across frames
Enterprise Security
Kili's security standards enable government and intelligence clients. On-premise deployment options ensure sensitive data stays within your infrastructure, making the platform trusted by highly regulated industries including healthcare, defense, and financial services.
Conclusion
Image annotation is foundational to computer vision success. From labeling images for object detection to creating pixel-perfect segmentation masks, the quality of your annotations directly determines the performance of your AI models. Similarly, video annotation plays a crucial role in enabling AI systems to accurately interpret and analyze video content.
The most successful organizations recognize that building expert AI data requires more than just annotation tools—it requires collaboration between technical teams and domain experts throughout the AI development lifecycle. When subject matter experts validate and refine annotations, the result is AI that's not just faster to deploy—it's better.
Whether you're working on medical image annotation, autonomous vehicle perception, manufacturing quality inspection, or any other computer vision project, the principles remain the same: diverse data, expert validation, quality workflows, and the right annotation tools will set your AI initiatives up for success.
Bibliography/webography
- Open source datasets (Kitti dataset from Andreas Geiger and Philip Lenz and Raquel Urtasun, BCCD dataset, Open data commons, ffhq dataset)
- Press articles (e.g., Venturebeat.com - Tesla AI Chief explains why self-driving cars don’t need lidar)
Resources:
- Make Training Process Productive With Kili AutoML And Weights & Biases
- Image Recognition Models: Three Steps To Train Them Efficiently
- What Is The Best Image Segmentation Tool?
- Understanding Supervised Machine Learning Applied To Image Recognition
- How To Read & Label Dicom Medical Images On Kili
- Automatic Error Identification For Image Object Detection In Kili

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
