
.png)

_logo%201.svg)


AI Summary
What is Image Classification?
In a society where digital images have become prominent in our daily lives, the volumes of data it has generated over the decades are massive. Computer Vision is a field of AI which uses a lot of data, mainly for image detection, recognition, and classification. Image Classification uses Machine Learning algorithms to analyze the presence of items in a picture and to categorize the picture.
This particular task forms the basis of Computer Vision and Image Recognition. Machines don’t analyze a picture as a whole. They only analyze a picture through pixel patterns or vectors. They will then categorize and assign labels to the elements they detect and classify them depending on the different rules that have been set up when configuring the algorithm.
Classifiers’ task is to take an input (a photograph for example) and to output a class label (extract the image features and predict the category from them).
There are two types of Image Classification techniques:
- If you are facing various pictures, and you only want to know whether the object in them is a cat or not, the problem you will have to handle is a binary classification. You only need to label one class of items for all images, or not to label it. The binary classification model is in charge of computing the presence or the absence of the object.
- If there is more than one category, you handle a multiclass classification problem which implies the creation of multiple labels that will correspond to various objects. The machine will then predict which single object class is contained in the photographs or pictures, among a set of predefined labels.
These techniques both mainly rely on the way the reference images are labeled. The following parts of this article will give a more detailed presentation of the way image classification works.
How does Image Classification work?
Machines have a very specific way to analyze images. The various techniques try to imitate the functioning of the human brain and eyes to propose an optimized analysis performance. The algorithms will leverage some pixel patterns which are very similar to what the machine has already seen. A whole process is necessary to build up an image classifier.
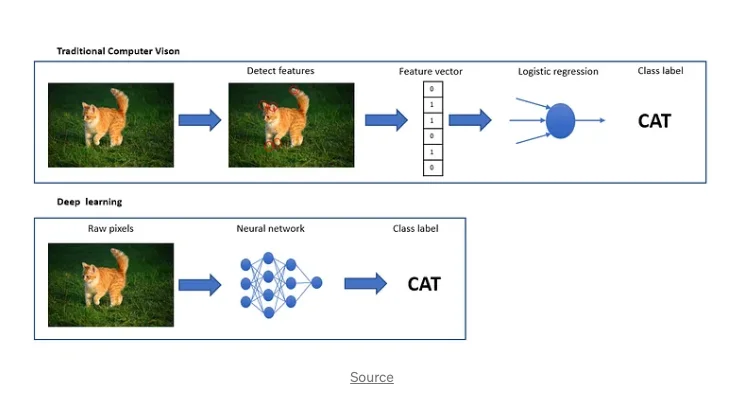
Source: Medium.com
The first step: creating a dataset for the machine to use as a reference
In the first place, Image Classification needs to have a reference dataset to work on. You can import a set of images from the API (Application Programming Interface) Keras via a code line. If you choose to use Python coding language, it could be a great solution for you. Once your dataset is installed, you might want to explore it for a few minutes, to discover the classes which have already been set.
Depending on how you want to use the images from your dataset, you might want to go through them and modify some of the original parameters:
- Making sure the machine can read the images and pictures with a few lines of code.
- All pictures and images should be the same size so that the computer can process all the images in a standardized format. That way, the machine will be able to go through the analysis more rapidly than having to analyze various pictures with different dimensions.
- The dataset should be augmented with more data, based on the resources there already are. Practicing data augmentation allows the machine to analyze many different versions of a dataset during the testing section. This specific step is a way to prevent overfitting, which refers to the risk for the machine to learn “by heart” the data seen during training sessions. The machine might ignore completely all unknown data and it might not be able to take into account new sets of pictures. Data augmentation can be done by changing the orientation of a picture, converting it to grayscale, rotating, translating, or blurring it. The more options you give to the machine, the higher the accuracy will be when analyzing the data.
Pre-processing your database is important if you want to have a solid dataset to work on, the next step is to create and set up a model which will learn to classify images.
Second Step: creating a model to detect objects: focus on Convolutional Neural Network
To classify images into multiple categories, you need to configure a classifier: an algorithm able to support your request. The most popular and accurate model type used to categorize images is CNN, which stands for Convolutional Neural Network.
What are CNNs?
Convolutional Neural Networks or CNNs are widely used in Image Recognition, Detection, and Classification. A CNN is a neural network architecture, inspired by human neurons, that can be trained on image data. To process images, it uses various filters and convolution layers which have to be pre-configured carefully.
Through these layers, CNN will create a feature map of the image, depending on the pixels which are represented. The whole matrix of elements will then be processed.
Understanding CNN architecture
CNN's use a very specific architecture, composed of convolutional layers and pooling layers (hidden layers). The number of layers which can be used during image processing may vary. A CNN model usually has between 3 to around 100 layers available for computer vision analysis.
Convolution layers refer to the application of filters to an input (a picture), one will filter pixel patterns based on the colors of the picture, another one will filter the shapes that are detected, etc.
After using a convolution layer, the algorithm will apply a pooling layer. This one will be in charge of collecting the information gathered by the previous convolutional layer. Its main task consists in cleansing the area and collecting data before proceeding with the application of a new filter.
When all the necessary filters and layers have been applied, the only thing left to do is apply the final layer to synthesize the information output by the previous layers. The classification results are then ready to be delivered.
These complementary steps make CNN's the most popular and effective Classifier tool in Machine Learning. They currently are at the state of the art for Image Classification tasks, due to their accuracy in the results and their ability to deliver them very quickly.
Third Step: training and validation of your algorithm
Now that you have created a valid dataset and set up a model to be used as a classification tool, we have to train it and test it to see if it is precise enough to provide us with the correct information.
Training with Supervised Learning
Computer Vision and Image Recognition tasks are based on the actions of the human brain. So if we want the method to be accurate, we need to train it and support it with a human hand. Supervised learning refers to a training of the data with a set that you labeled yourself. In other words, you imported your own set of pictures and created the classes by yourself as well. Input and output data are given to the algorithm. For example, You select a picture (input) of a group of cats with a bird, and you only want to know if there is a bird (output) on the picture.
Pro tip 💡
Dive into our guide on building high-quality datasets. Discover how to remove annotation errors by setting up the most accurate ontology, managing your labeling efficiency, and more!

To train the algorithm, various methods can be used: vector-related ones, which are used to divide the classes with a linear boundary. Decision Trees are also very common methods. And of course, Neural Networks like CNN-based models can be used. The algorithm simply has to answer yes-no questions to identify and categorize the different objects in the picture.
Supervised learning is much simpler to use but it can be very time-consuming and it might not be able to classify big data. The dataset has to be checked thoroughly. When somebody identifies a category of item, he or she can label all the classes the way he or she wants to. This allows the creation of a wide enough dataset for training, but it can be challenging. Results are usually better in terms of accuracy.
Training with Unsupervised Learning
Using unsupervised learning in Image Classification means letting the machine and the algorithm recognize what they are submitted. It usually works with pre-labeled data and inputs which haven’t been checked by people before training.
When encountering the first images, the machine will analyze whether the object corresponds to the first category. If not, it will try to find out if it could be similar to pixel patterns from the second category, etc. The machine has been programmed to analyze through CNN layers and filters we have mentioned earlier in this article. The algorithm is just processing a comparison between the reference image from its database with the picture which is being proposed to the machine. The method applies data augmentation automatically to see if pixel patterns could fit some of the images.
Another way to train the algorithm is to recognize and categorize cropped images. If we introduce a picture with a missing part in the middle, the system might be able to locate an image with similar pixel patterns around the missing part of the picture to analyze. This training method is called the Generative Model. But it requires developing some awareness of the context inside the system. Also, the system is not meant to recognize and analyze missing parts of images. This might lead to a lot of errors and negative results which is not a healthy base to work on when using Machine Learning and Deep Learning tools. These tools are supposed to acquire knowledge by themselves, using errors from the past. If too many errors are observed in the training phase, the algorithm might be confused and deliver only negative results, which is clearly not what we are looking for.
Another model used in unsupervised learning is the teacher-student approach. An input image is augmented in two different ways. Each of the new images is processed both through a teacher program and a student program. Both programs are set up with a different method to analyze the picture. The goal of this approach is to get as similar results as possible regarding Image Classification. This comparison approach has shown a strong accuracy in training results and seems to be extremely interesting for AI developers.
Unsupervised machine learning allows you to let the program learn various new patterns from data by itself. Humans do not need to control the training. The downside of it is that, since nobody has a hand on it, there is no way to keep an eye on the number of classes that the program has set up. Researchers and users are questioning the accuracy and precision of these methods for the moment.
Depending on the results of your model: the precision and accuracy of the categorization, the classifier you have created are validated.
Latest advances in Image Classification and Object Detection with Machine and Deep Learning
Deep Learning is an advanced field of Machine Learning, it gives even more power to the machine and the programs it uses. Classifiers in Deep Learning work mostly with CNNs, and a very high number of different layers, making the image recognition and classification even more complex. CNN's being inspired by the human eyes; you might be surprised when learning that some of the approaches have allowed surpassing the abilities of the human eye! Some of the algorithms used for Image Classification have proved to detect, recognize and categorize more items in a picture or a video than a person.
Image Processing has become a true part of our lives. It needs to be ever more efficient, to go faster, and to be more precise. This is why researchers have developed over the last few years, new optimized tools. In 2017 was invented the Mask R-CNN algorithm, which was a methodology based on CNNs and their various layers, and on instance segmentation was. Instance segmentation is the ability to fusion the use of bounding boxes and precise labeling of the input. This means the feature extraction needs to take into account a fine outlining of the detected objects. This new approach is mainly used in real-time videos.
In 2021 was introduced a newer version of YOLO (You Only Look Once), was an Image Processing tool: YOLOR (You Only Learn One Representation). YOLOR is meant especially for Object Detection. It is based, once again on the way the human brain functions. People are able to recognize objects only based on their previous experiences. And this is precisely where YOLOR’s creators got this idea from creating a tool able to keep a memory of what it has learned in the past for Image Recognition and Classification. YOLOR uses CNNs to function. When facing one input, YOLOR’s goal is to process many different tasks at the same time to provide the most efficient and accurate result and also to learn how to get different outputs. The number of layers that are necessary to make this approach work is unlimited and very hard to control.
The world uses Classifiers every day: detecting abandoned luggage at the airport, unlocking your phone, Facebook and your friends publishing a picture of your aunt from the last family reunion just because Facebook’s Image Classification program recognized the face of your aunt. Image Processing follows us all the time and everywhere.
This very last discovery in Deep Learning gives us an idea about how the human brain can be imitated and how it could be used in the future. Artificial Intelligence is still making baby steps into building a world full of automation. There is no doubt that IT researchers are not ready to stop working on that topic for a long time.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
