
.png)

_logo%201.svg)


AI Summary
- FineWeb combines aggressive web data filtering, deduplication, and benchmark-driven evaluation to produce a higher-quality open pretraining corpus than typical Common Crawl extracts.
- Filtering decisions are validated by training proxy language models on candidate data slices and measuring downstream benchmark performance, not by heuristics alone.
- Effective deduplication removes near-identical content while preserving diversity, preventing the model from over-fitting to repeated patterns in web data.
- Open-sourcing both the dataset and the curation methodology enables reproducible research and accelerates community progress on multilingual data curation.
- Kili Technology delivers tailored, high-quality data for LLM training at scale, removing the data quality bottleneck so teams can ship higher-performing language models.
Data is the most valuable ingredient for machine learning models, from basic natural language processing models to the advanced frontier models we know today. Consequently, many companies keep their data curation methods and large datasets a closely guarded secret. To help machine learning engineers better understand and gain access to high-quality datasets, Hugging Face developed FineWeb and shared in its documentation the exact steps and processes they took to build and evaluate the performance of datasets used to train a language model.
In this article, we'll share the best insights from their report. Still, we highly recommend reviewing their documentation to replicate their entire process and understand the technical filtering and deduplication methods they've put to work.
Check out Hugging Face's technical report.
What is the FineWeb Dataset?
The FineWeb dataset is a cutting-edge resource for training Large Language Models (LLMs), featuring over 15 trillion tokens of cleaned and deduplicated English web data sourced from CommonCrawl. It undergoes rigorous data processing using the datatrove library, ensuring high-quality data optimized for LLM performance.
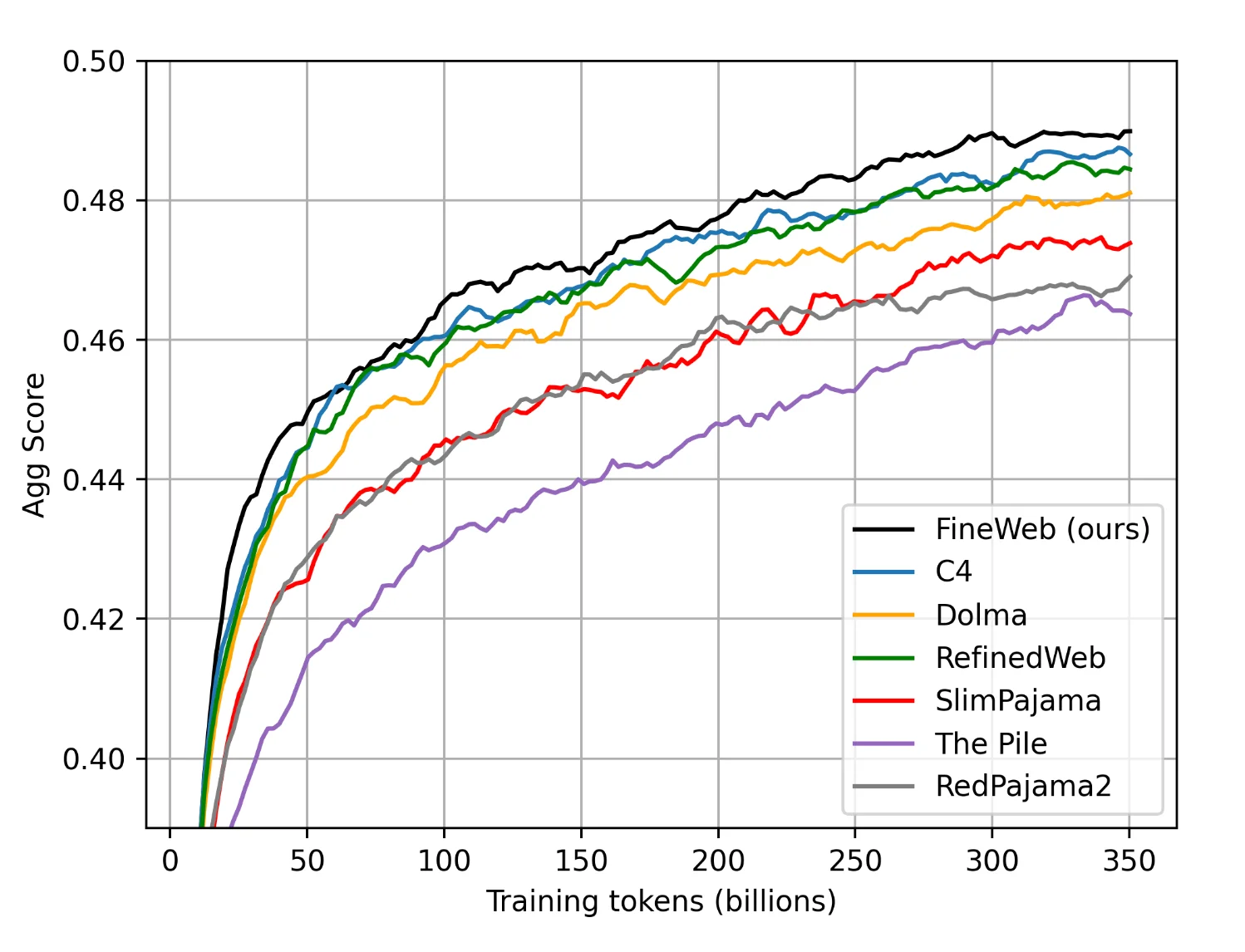
Originally designed as an open replication of RefinedWeb, FineWeb incorporates additional filtering steps, resulting in models that outperform those trained on other high-quality datasets like C4, Dolma-v1.6, The Pile, SlimPajama, and RedPajama. FineWeb is released under the ODC-By 1.0 license, promoting transparency and collaboration within the AI community.
Aggregate score of datasets performing selected tasks with Fineweb outperforming the group. Source: Hugging Face
Unlock the full potential of your LLMs with our data solutions
At Kili Technology, we understand the challenge of maintaining high-quality datasets for optimal LLM performance. Our platform provides robust tools for aligning your LLMs, ensuring they learn from the best data. With our expert workforce and advanced project management, we ease the alignment process, saving you time and resources.
Start a POC
Measuring Data Quality through Early Signal Benchmarking
But wait, how do we know how this dataset performs? Ensuring high data quality is critical for the performance of language models, but most methods for measuring data quality are logistically difficult or may not be effective enough to understand their impact on a model. Interestingly, Huggingface employed early signal benchmark tasks as a logical compromise.
Early-signal benchmark tasks are specific, relatively small-scale evaluation tasks used to gain quick insights into the effectiveness of a dataset or a data processing method. These tasks are designed to provide an early indication (or signal) of how well a language model is likely to perform if scaled up and further trained.
Here are a few of the advantages mentioned in their report:
- Rapid Feedback: Early-signal benchmarks allow researchers to quickly iterate on data processing methods and dataset curation techniques without the need for extensive training on full-scale models.
- Cost Efficiency: Evaluating smaller models on these benchmarks is much less resource-intensive than training and evaluating full-scale models, making it more feasible for experimentation and refinement.
- Performance Proxy: These tasks serve as a proxy for more comprehensive evaluations, helping to identify promising datasets and processing methods early in the development cycle.
Evaluation Benchmarks
In this project, Huggingface used a variety of benchmark tasks to evaluate their dataset iterations and compare their dataset against other publicly published datasets:
CommonSense QA
CommonSense QA is a dataset that evaluates a model's ability to answer questions requiring commonsense knowledge. It consists of 12,247 multiple-choice questions, each with five answer choices. The questions are generated using CONCEPTNET, a large commonsense knowledge base, and are designed to require reasoning beyond simple associations. The dataset aims to test the ability of models to incorporate and utilize commonsense knowledge effectively.
HellaSwag
HellaSwag is a dataset focused on commonsense reasoning in the context of narrative completion. It provides contexts and asks models to choose the most plausible ending from multiple choices. The dataset is designed to be challenging by including adversarial examples that are difficult for models to distinguish from the correct answer. This benchmark tests a model's ability to understand and predict the progression of events in a given context.
OpenBook QA
OpenBook QA is a dataset that requires models to answer elementary-level science questions. The questions are designed to test a model's ability to apply scientific knowledge and reasoning. Each question is accompanied by a small "open book" of facts that the model can use to answer the question. This benchmark evaluates the model's ability to integrate and apply specific knowledge to new problems.
PIQA (Physical Interaction QA)
PIQA focuses on physical commonsense reasoning, asking questions about everyday physical interactions and the use of objects. The dataset includes multiple-choice questions that require understanding of physical properties and affordances of objects. This benchmark tests a model's ability to reason about the physical world and predict the outcomes of physical interactions.
SIQA (Social IQa)
Social IQa is a dataset designed to evaluate a model's understanding of social interactions and social commonsense. It includes questions about social situations, asking models to predict the most appropriate response or action in a given context. This benchmark tests a model's ability to understand and reason about social dynamics and human behavior.
WinoGrande
WinoGrande is a large-scale dataset for commonsense reasoning, specifically designed to address the limitations of the Winograd Schema Challenge. It includes sentences with pronouns that require disambiguation based on commonsense knowledge. The dataset is significantly larger and more diverse than its predecessors, making it a robust benchmark for evaluating a model's ability to resolve ambiguous pronouns using commonsense reasoning.
ARC (AI2 Reasoning Challenge)
The AI2 Reasoning Challenge (ARC) is a dataset of science questions designed to test a model's ability to reason and apply scientific knowledge. It includes both multiple-choice and open-ended questions, covering a wide range of scientific topics. The benchmark is divided into an easy set and a challenging set, with the latter requiring more complex reasoning and knowledge integration.
MMLU (Massive Multitask Language Understanding)
MMLU is a comprehensive benchmark that evaluates a model's performance across a wide range of tasks and domains. It includes questions from various subjects, such as history, mathematics, and science, and is designed to test a model's general knowledge and reasoning abilities. The benchmark aims to assess the model's ability to perform well across multiple tasks without task-specific fine-tuning.
These benchmarks collectively cover a broad spectrum of commonsense reasoning tasks, from physical and social interactions to scientific knowledge and general reasoning, providing a comprehensive evaluation framework for natural language understanding models.
Iterate, iterate, iterate
By going through the Fineweb documentation, one can see the extensive and rigorous benchmarking that the Hugging Face underwent to optimize the Fineweb dataset as much as possible.
Each step was measured against these benchmarks to determine the correct steps to improve the quality of the data, balance its quantity, and understand how it impacts model training.
Individual Deduplication and Diving Deeper into the Data
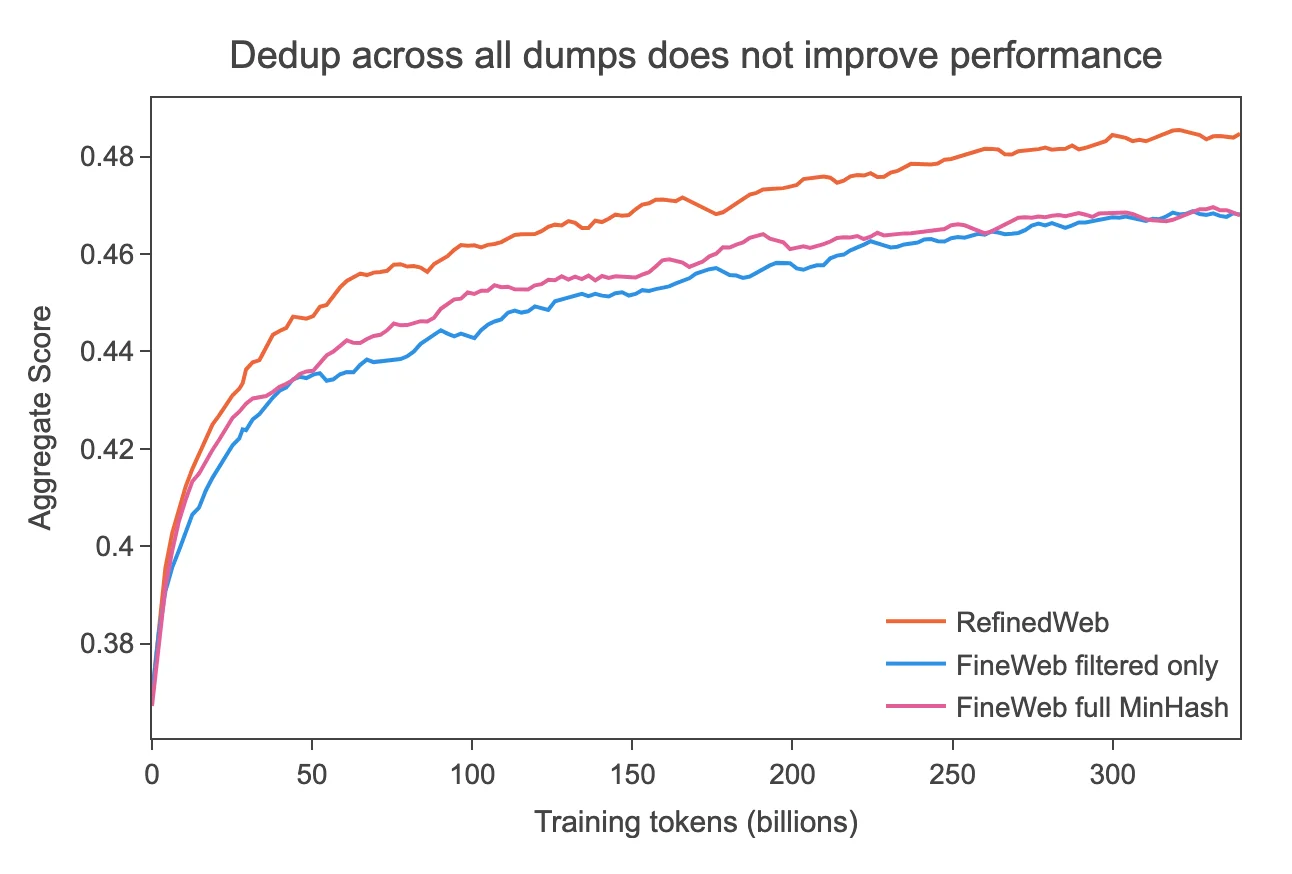
In the process of preparing your dataset, deduplication is a primary and vital step to improving your data's quality. To do it effectively, examining your data is helpful in coming up with a deduplication strategy, especially when doing so at the scale of the Commoncrawl dataset. Case in point, Hugging Face made an interesting discovery when applying Minhash deduplication to the entire Commoncrawl dataset.
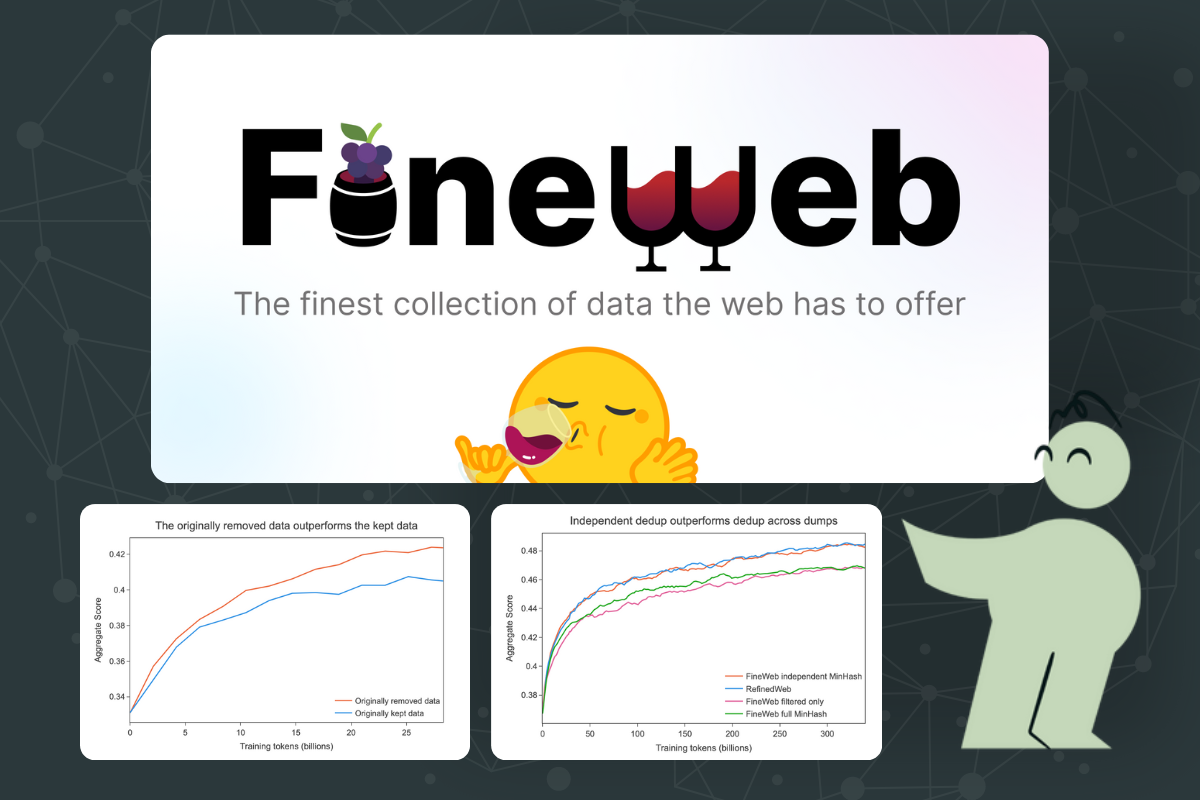
More deduplication is not always the answer
In Hugging Face's process, they discovered that more deduplication may not always be the answer to a higher quality dataset.
In the initial method, the dataset comprised more than 90 CommonCrawl dumps, and MinHash deduplication was applied iteratively across the entire dataset in the most recent to oldest order. Each dump was deduplicated against itself and all previous dumps.
Barely any improvement after deduplication
However, despite extensive deduplication efforts, model performance did not significantly improve. Surprisingly, models trained on deduplicated data performed similarly or even worse than those trained on non-deduplicated data.
The problem: too much quality data removed
To understand why, Huggingface ran another experiment. An experiment on the oldest dump (2013-48) revealed that pre-deduplication, there were approximately 490 billion tokens, which reduced to around 31 billion tokens post-deduplication, signifying a 94% reduction.
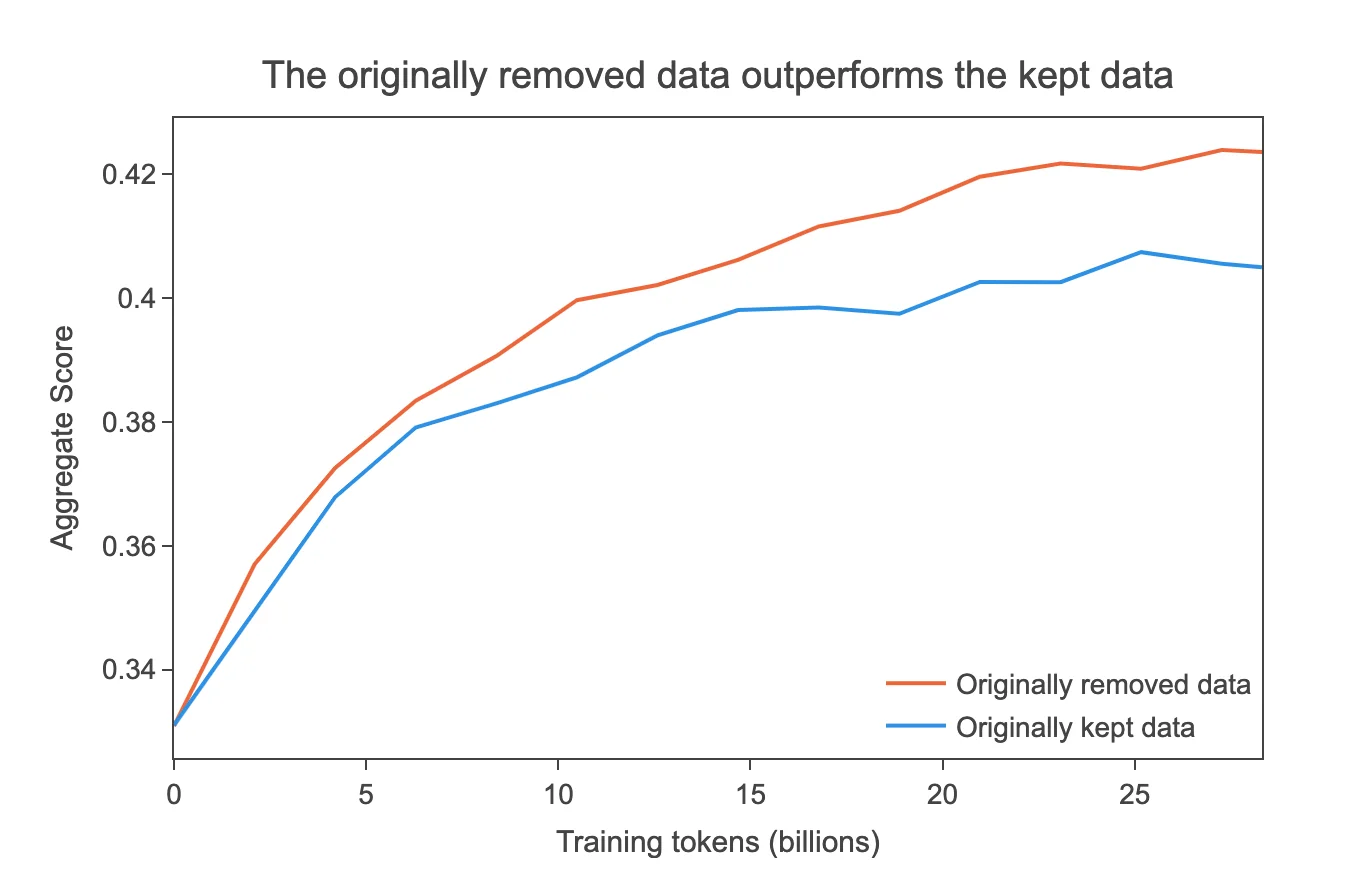
Training on the remaining tokens versus the initially removed tokens showed that the originally removed data were of higher quality than the retained data. Upon closer inspection, it was revealed that the original dataset contains significantly more advertisements, lists of keywords, and poorly formatted text compared to the removed data.
Trying out individual dump deduplication
In this process, each data dump is processed individually, and duplicate data is only removed within each dump. No comparison is made between different dumps. For instance, if there are 90 data dumps, deduplication is only applied within each individual dump.
As a result, each dump retains more unique data because it is not being compared against other dumps. This approach results in a larger dataset because duplicates between different dumps are not removed. The focus of this approach is to eliminate duplicates within a single dump, potentially preserving more high-quality and diverse data.
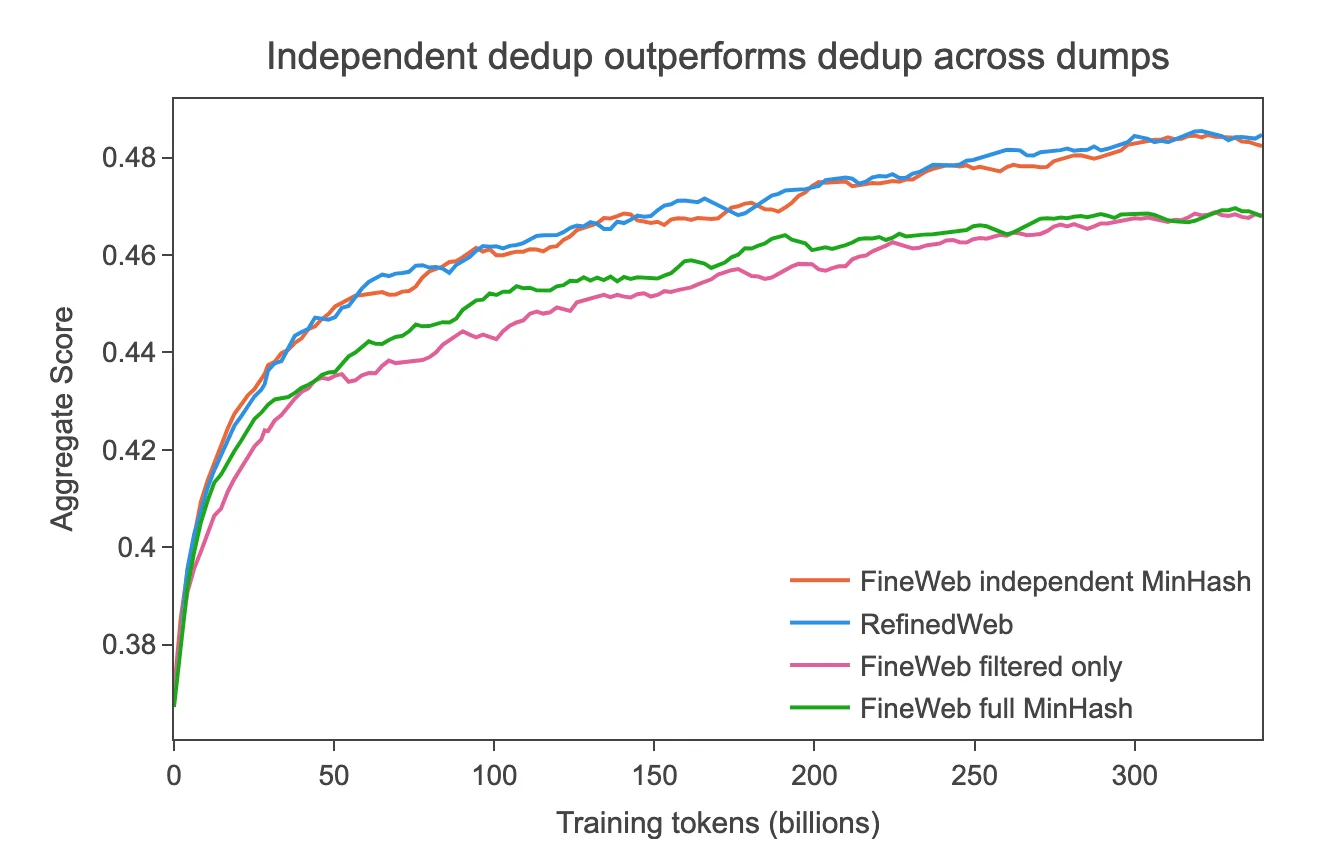
A reminder: dive deep into the data
Oftentimes, we can be tempted to start executing well-known strategies immediately especially when dealing with a dataset at the scale of Commoncrawl; however, examining data closely (at least going through some sampling) before starting is not only sensible but essential for ensuring that the deduplication process enhances, rather than harms, the quality and diversity of the dataset.
The process of determining the best strategy for deduplication involves several steps:
- Perform data profiling and sampling to understand data characteristics.
- Identify potential clusters of duplicates and unique data points.
- Based on the initial assessment, define the deduplication strategy (e.g., individual deduplication within each dump).
- Implement deduplication on a small subset as a pilot test.
- Evaluate the impact on data quality and model performance.
- Apply the refined strategy to the entire dataset.
- Monitor and adjust the process to ensure the best balance between deduplication and data retention.
Enhance your LLMs with Kili Technology's comprehensive evaluation solutions.
Ensuring the quality and performance of your language models can be a daunting task. Kili Technology offers LLM evaluation tools that help you measure and enhance your models effectively. Our solutions leverage a skilled workforce and efficient project management to provide precise and reliable evaluations, driving better outcomes for your AI projects.
Start a POC
Creating custom filters and building on previous work
In preparing datasets for natural language processing and machine learning models, filtering plays a crucial role. It helps enhance data quality, improve model performance, and optimize resource usage. The process involves selecting, cleaning, and refining the data to improve its quality and relevance.
After deduplicating the Fineweb dataset, Hugging Face conducted another round of evaluations and found that another publicly available dataset, C4, outperformed theirs in the benchmark tasks they had selected.
In response, they applied C4's filtering process to their Fineweb dataset and also created custom filters to surpass C4's performance.
Screenshot of Hugging Face's post sharing their methodology for creating more filters.

From Hugging Face's process, we can gather the following insights:
Benchmarking Against High-Quality Datasets: Successful datasets like C4 should be used as benchmarks for developing and validating filtering methods.
Heuristic Filtering: Implementing heuristic filters at multiple levels (line and document) effectively removes noise and irrelevant data. Domain-specific knowledge is essential to creating meaningful filters, such as removing "lorem ipsum" text and JavaScript notices.
Statistical Analysis: Collecting a wide range of statistics from datasets helps understand the differences between high-quality and low-quality data. Statistical measures like the Wasserstein distance can identify significant metrics to differentiate data quality.
Iterative Validation: Validating filters through iterative testing and ablation studies ensures that they effectively improve data quality and model performance.
Balanced Filtering: It's crucial to avoid overly aggressive filtering that may remove useful data. The goal is to achieve a balance that maximizes quality without significantly reducing the dataset size.
The value of open source
Hugging Face has always championed open source. As the development of large language models becomes more accessible, understanding the importance and process of achieving high-quality large datasets is vital to fueling AI progress.
Building high-quality datasets for natural language processing and LLM training demands a meticulous approach to data collection, filtering, and deduplication. Hugging Face's FineWeb project is a great example of best practices in preparing large datasets, offering valuable insights into this intricate process.
By combining robust filtering techniques, effective deduplication, and rigorous performance evaluation, FineWeb achieves superior dataset performance and sets a new standard for open datasets in the machine-learning community. The transparency and dedication to open sourcing, both the studies and datasets, foster collaboration and accelerate advancements in the field. For those looking to replicate or build upon this work, the detailed steps and methods shared by Hugging Face provide an excellent roadmap, promoting an open and collaborative environment that benefits the entire AI community.
Training large language models from scratch
Creating high-quality datasets for training Large Language Models (LLMs) is a complex and essential task. The insights from Hugging Face's FineWeb project underscore the importance of meticulous data curation, rigorous filtering, and thorough benchmarking to achieve optimal model performance. By embracing these best practices, you can significantly enhance the effectiveness of your AI models.
Kili Technology stands out in this domain by providing meticulously tailored, high-quality data for LLMs at scale. Our expertise ensures that your models are trained on the best possible datasets, eliminating the data quality bottleneck and allowing you to ship the highest-performing large language models. Feel free to consult with one of our experts to help you get started.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
