
.png)


_logo%201.svg)


AI Summary
In the ever-evolving world of artificial intelligence (AI), high-quality and accurately labeled data are indispensable. This comprehensive guide will share with you what data labeling tools are and the value that they bring to your machine learning and AI projects. We will also share with you what to expect from the best data labeling tools to optimize the quality of your data and, consequently, enhance your AI projects.
Understanding What Data Labeling Tools Can Do For You

Challenges and Costs of Data Labeling
Data labeling is a pivotal but labor-intensive component of AI development. It offers the necessary input for your model to learn and make accurate predictions. However, this process can be tedious and error-prone when conducted manually.
While it's true that data labeling presents challenges in terms of labor and cost, these issues should not overshadow the immense importance and value of high-quality data labeling. Turning raw data to high quality labeled data is fundamental to AI success especially for supervised machine learning models, which constitute a significant portion of AI applications. Without properly labeled data, models would lack the necessary guidance to learn effectively.
Investing time and resources in high quality training data upfront can save much more downstream. At Kili, we believe a 10% increase in label quality can drive a 50% decrease in dataset size. Machine learning models trained on poorly labeled data can produce inaccurate results, leading to incorrect decision-making and potentially expensive corrective measures.
Understanding the challenges and benefits of data labeling, one might ask how do we solve for these issues? This is where data labeling tools come in. Employing the right tool is essential to circumvent these challenges and prevent raw data preparation from becoming a costly bottleneck.
How Data Labeling Tools Ensure High-Quality Data and Reduce Costs
As we discussed, high-quality training data is integral to the development and success of AI models. It enables AI models to make precise predictions and deliver more reliable results. This in turn reduces the cost of reworking or rectifying issues down the line, therefore leading to overall project cost savings.
Suppose you opt to manually label your data without using a data labeling platform. You can use a massive human workforce to perform data labeling. In that case, this process can be expensive, labor-intensive, time-consuming, and prone to human error. If you're working on a computer vision project and decide to label thousands of images manually, not only will it require significant man-hours, but the consistency and accuracy of labeling may also be compromised due to fatigue and human oversight.
This could result in incorrectly labeled data, which can mislead the machine learning model during the training process, leading to suboptimal performance or even failures in real-world applications. Furthermore, managing and coordinating a team of labelers can become a herculean task without a data labeling tool. This lack of coordination and standardization degrades the quality of your labeled data.
Advanced platforms, such as Kili Technology's data labeling tool, can automate and streamline the data labeling process and help collaborators stick to labeling guidelines, ensuring data is labeled accurately and consistently.
This significant efficiency and quality control reduces the time and costs associated with data preparation, thereby improving the quality of your data and enhancing your machine learning model's performance. To illustrate, Kili Technology’s data labeling solution reduced data labeling costs by two times for a multinational social video company thanks to a centralized and intuitive platform to handle all types of data, efficient workflows, and labeling data automation.
In the medical industry, particularly in ophthalmology, Kili Technology was able to help accelerate retinal disease detection at a low cost. The solution facilitated a healthcare company to produce a model that provided accurate retinal diagnosis in 60 seconds, thus reducing costs of AI eye screening by 40%.
What You Should Expect from the Best Data Labeling Tools
Now that we have a better idea of the value of data labeling tools. Let’s talk about essential capabilities that your data labeling tool must have to help you build high-quality training data for your AI applications.
Data Labeling Tool Capabilities According to Data Types
There are plenty of different data labeling tools out there. But first and foremost, a state-of-the-art data labeling solution should accommodate not just one but multiple data types - text, images, video, audio, and even sensor data, each requiring its unique approach to labeling. This versatility is key in bridging the gap between raw data and actionable insights.
For instance, autonomous driving projects necessitate labeling image data, involving object identification and recognition. Similarly, Natural Language Processing (NLP) tasks like sentiment analysis and entity recognition rely on accurately labeling text data. Video data labeling becomes paramount for computer vision research, surveillance systems, or content moderation platforms, while voice recognition systems require meticulous audio data labeling.
Consider the following data types which should be supported by sophisticated data labeling tools:
- Text: Text annotation applies to documents, emails, chat logs, and social media posts. Common annotation tasks include sentiment analysis, Named Entity Recognition (NER), and text classification.
- Images: Image data labeling pertains to photographs, diagrams, and maps. Typical tasks include image segmentation and image classification.
- Audio: Audio files, including speech, music, and sound effects, can be annotated. Labeling tasks can range from speaker diarization to music genre classification.
- Video: Video data, like movies, TV shows, and surveillance footage, can be annotated. Action recognition, object tracking, and facial recognition are some common labeling tasks.
- Sensor data: This involves the annotation of sensor data, such as GPS data, accelerometer data, and environmental sensor data, with common annotation types including activity recognition, location tracking, and environmental monitoring.
Advanced tools like Kili Technology offer intuitive interfaces for these data types, supporting an array of labeling tasks such as classification, entity recognition, sentiment analysis, object detection, and speech recognition.
Enable Collaboration for Your Data Labeling Teams
One of the most important features a data labeling solution should have is its ability to foster collaboration. Collaboration is critical to successful data labeling, particularly for large projects that involve several team members or departments. It can help prevent redundancies, streamline processes, and promote a more unified approach to data labeling.
When choosing your tool, know that it should allow multiple team members to work on the same dataset concurrently, promoting efficiency and synergy among team members. And, regardless of your team's size or your business's scale, your chosen tool should be adaptable.
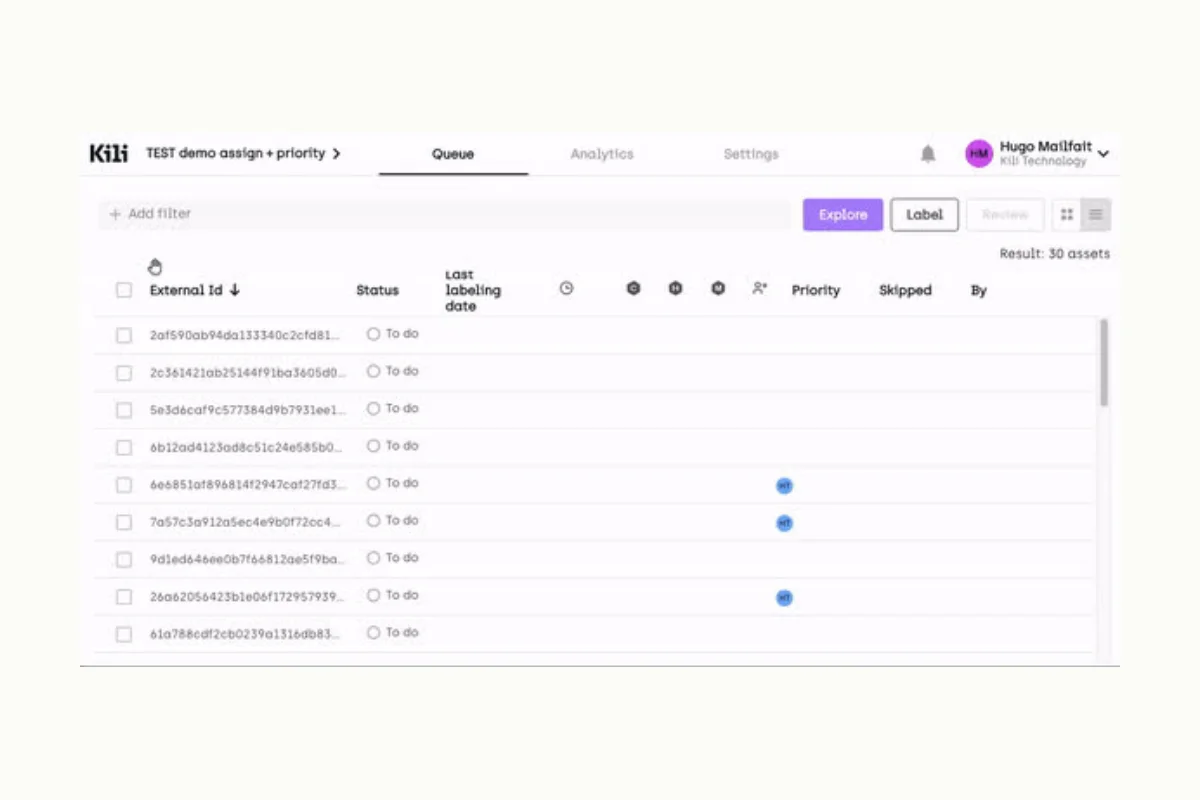
Key features to look out for in advanced collaborative data labeling tools include role-based access, analytics, and varying levels of permissions. Role-based access ensures that every team member has the appropriate level of access, aligning with their respective roles and responsibilities. Comprehensive analytics can help track progress, identify bottlenecks, and streamline the labeling process. Different levels of permissions provide a balanced level of control and autonomy among the team members, fostering accountability while maintaining organizational structure.
For even more effective collaboration, consider these best practices:
- Unify labels: Consistency in labeling across the team is crucial. Ensuring all members adhere to the same labels reduces confusion and enhances data quality.
- Handle questions and issues collectively: Encourage an environment where team members can openly discuss their questions or issues. This not only helps solve problems faster but also promotes knowledge sharing and a deeper understanding of the data.
- Automate workload distribution: Automating task assignment can greatly enhance efficiency. It ensures an equitable distribution of workload and helps maintain a steady pace of work.
- Provide clear labeling instructions: Clear, concise, and comprehensive instructions form the bedrock of high-quality data labeling. They guide your team members and ensure everyone is on the same page.
Fostering collaboration in your data labeling team through a capable tool and following these best practices can significantly enhance the quality of your labeled data, driving the performance of your AI models.
Handling Quality Control in the Data Labeling Process
Quality control is a critical aspect of data labeling. Without it, inconsistencies and errors can creep into the data, undermining the performance of your AI models and ruining your data labeling efforts. Implementing effective quality workflows is vital to ensure high-quality data and continuous improvement of the labeling process.
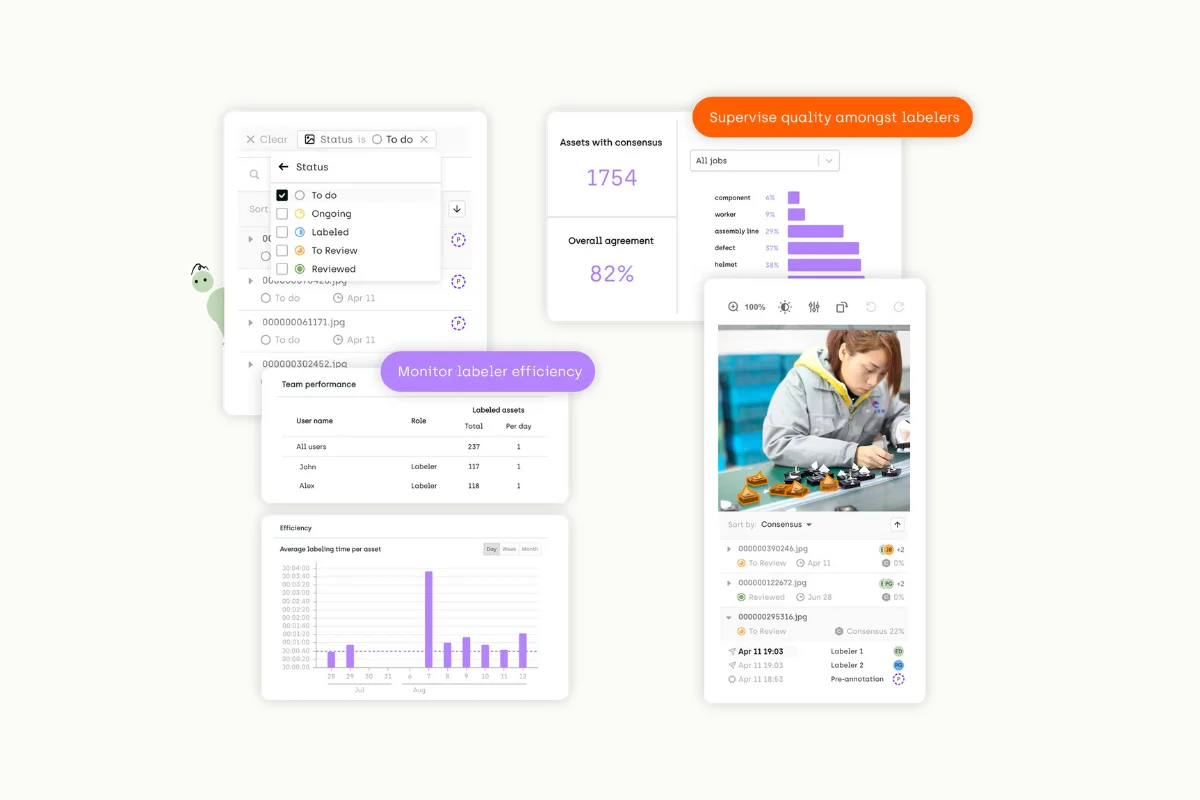
Best practices for quality control involve a combination of strategies. For instance, using continuous feedback allows your team to collaborate more effectively and address issues promptly. Performing random and targeted reviews ensure that all labeled data is audited periodically. Adding quality metrics provides a clear gauge of the accuracy of your labels. Finally, setting up programmatic quality assurance (QA) can help automate the quality control process.
Moreover, specific strategies such as Consensus and having a gold standard can be employed to increase the reliability of the data labels. Consensus works by having more than one labeler annotate the same asset and then measuring the level of agreement between the different annotations. This is a key measure for controlling label production quality.
At Kili Technology, a feature for highlighting the gold standard is Honeypot. Honeypot is a tool for auditing the work of labelers by measuring the accuracy of their annotations. Assets used as Honeypot are intelligently distributed and sent for annotation to all project labelers, thereby providing a measure of the agreement level between the ground truth and the annotations made by the labelers.
Advanced Data Labeling Features
Sometimes it's worth looking into tools with more advanced features, as these can dramatically enhance the overall effectiveness of your data labeling process, leading to improved AI model performance. These include the seamless integration with data pipelines, the automation of labeling processes, the capacity for model iteration, and the integration of smart tooling functions.
Integration with Data Pipelines: A crucial feature of any data labeling solution is its ability to integrate directly with popular cloud storage platforms. This allows for easy data transfer, enhanced data security, and streamlined data processing workflows. A well-documented API and a flexible Python SDK can further bolster this integration process. These software tools provide more control over how data is processed within the tool, thereby optimizing efficiency.
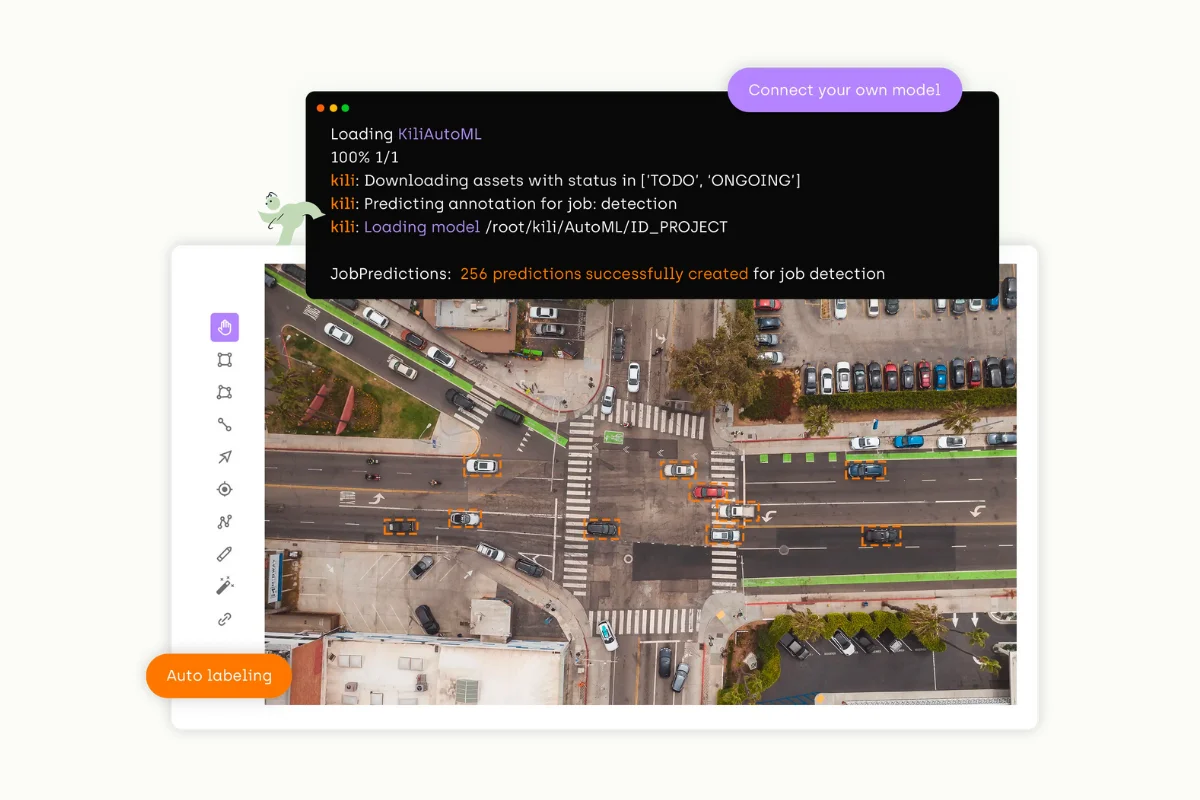
Automation and Model Iteration: Automation features in data labeling tools can leverage your existing AI model predictions to pre-label data, accelerating the labeling process and reducing human intervention. This automated annotation should also facilitate model iteration, a process where AI models learn from past labeling tasks to enhance their future performance. Such automation and model iteration capabilities improve the accuracy of AI models and the efficiency of data labeling tasks.
Smart Tooling Functions: Incorporating smart tooling functions, such as integration with SAM (Segment Anything Model), a foundation model built by Meta, can significantly improve the labeling process. SAM excels at generalized image segmentation tasks and can provide real-time segmentation masks for interactive computer vision applications. The integration of SAM into a data labeling solution, like Kili Technology, allows labelers to annotate their image or computer vision datasets efficiently.
Another example is being able to provide annotation propagation capabilities. This feature streamlines the annotation process by using the first frame of an annotated video or sequence to automatically propagate labels to subsequent frames, thereby significantly accelerating the labeling process and improving label consistency across frames.
Prioritizing Data Security in Your AI Projects
Data security should be non-negotiable in any AI project, with strict adherence to regulations like GDPR, HIPAA, among others. Your chosen data labeling platform must ensure confidentiality, safeguarding sensitive data from breaches or unauthorized access.
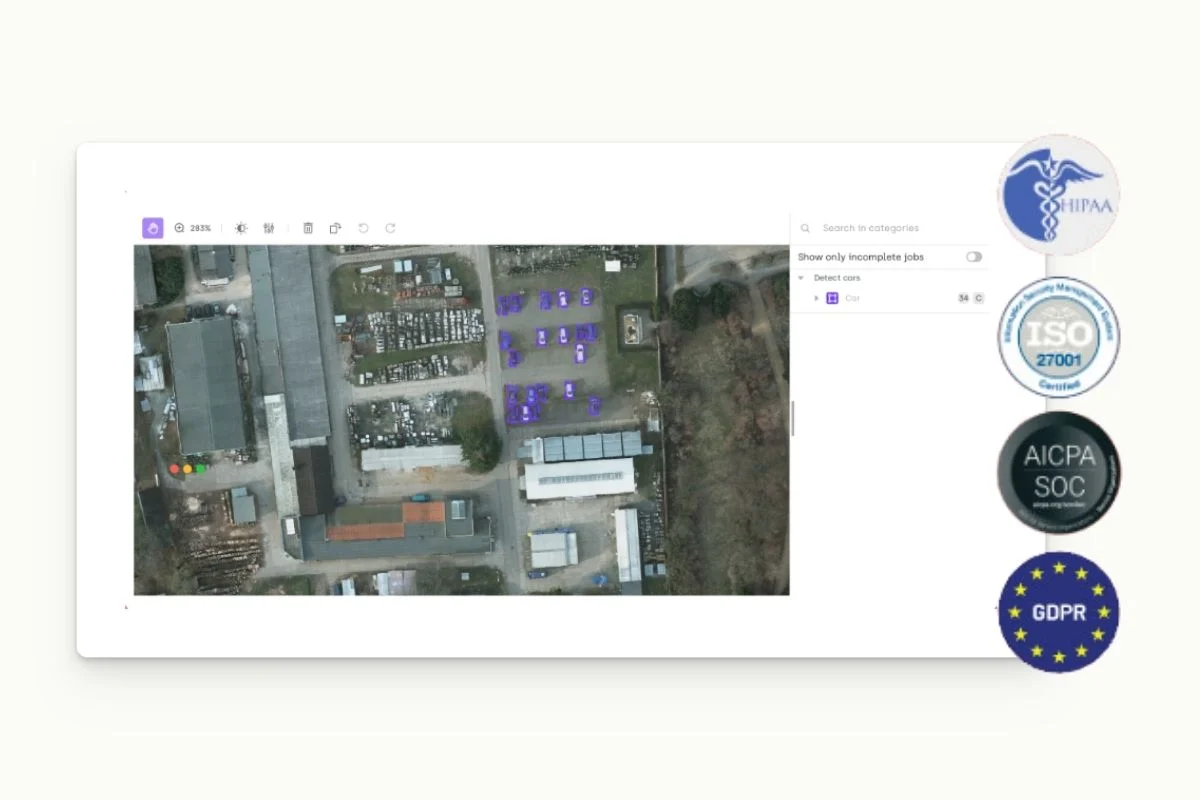
Platforms like Kili Technology prioritize robust security features, with secure hosting options, authentication protocols, and encrypted data storage. Moreover, leading data labeling tools offer secure native integrations with major cloud storage providers such as AWS S3, Azure Blob Storage, and Google Cloud. This secure transfer between your cloud storage and the data labeling tool is crucial to maintaining data safety.
Learn More
Handling sensitive data? Check our best practices for sensitive data annotation projects! To get insider tips on how to manage data to prevent security breaches, read our dedicated whitepaper.
Read
Beyond these features, responsible data labeling software providers like Kili Technology comply with stringent security and privacy standards, including SOC2, ISO, HIPAA, and GDPR. They ensure data security through measures like data encryption, extensive access controls, and regular security audits.
Choosing the Best Data Labeling Tool
Tailoring the Choice to Your Specific Needs
Selecting the appropriate data labeling tool for your project is a critical decision that should be dictated by your specific needs and project requirements. Aspects to consider include the type and volume of data you plan to label, your budget constraints, and any distinctive features your project might necessitate.
As a reminder, a high-performing data labeling tool should ensure:
- High Quality Data and Consistency: The tool should guarantee high-quality and consistent data labeling, directly impacting your AI model's accuracy and performance.
- Effective Collaboration: An optimized and intuitive user interface is vital to enhance collaboration among team members and streamline the labeling process.
- Versatility: The tool should offer comprehensive labeling options for diverse data types like images, text, audio, and video.
- Scalability: With growing datasets, the tool should be capable of scaling up to meet increased data labeling demands.
- Security: It should provide a secure environment for handling and storing sensitive data, complying with standards like GDPR and HIPAA.
Additionally, you should convene a team of stakeholders who understand your project's needs. Aside from data labeling experts, you will want to include ML engineers and data scientists, data project managers, subject matter experts, and IT security specialists to account for the details we just discussed. When in doubt, you may want to check out our Data Labeling Platform 2023 Checklist to help your team in making a decision.
Try Before You Buy
Most data labeling software will provide some form of free trial so teams can decide on the tool that works best for them. Kili Technology offers a comprehensive free trial, allowing up to 5 users to make 5,000 annotations across all data types. The trial also includes the advanced capabilities we discussed in this article, such as quality workflow features, quality and productivity metrics, access to Kili's API and Python SDK, and support via Documentation and a Slack Community.
Learn More
Download our free excel template on how to choose your data labeling platform, and get instant access to the features checklist that will help to accelerate your data labeling.
Selecting the right data labeling tool is a critical decision that can significantly impact the success of your AI projects. By understanding the capabilities and features of these tools, you can make an informed decision that best fits your needs, ensuring your AI project excels with high-quality data.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
