
.png)


_logo%201.svg)


AI Summary
- Fine-tuning adapts pretrained LLMs to specific tasks, domains, and tones, addressing limitations like hallucinations and lack of domain expertise that block production deployment.
- Supervised fine-tuning, RLHF, single-task fine-tuning, and parameter-efficient methods like LoRA each suit different goals, dataset sizes, and computational budgets.
- Distillation generates training data from larger models but inherits any domain expertise gaps in the teacher model, making human review essential for specialized work.
- Iterative fine-tuning workflows that combine machine predictions with structured human review converge faster on production-ready accuracy than single-pass training.
- Kili Technology supports the fine-tuning loop with custom evaluation metrics, classification, ranking, and transcription tasks on prompts, and integrations for ChatGPT, Bard, and Llama.
Fine-tuning Large Language Models (LLMs) is crucial in artificial intelligence and machine learning. It involves adjusting a model to follow specific instructions or answer questions using your specialized dataset. This process can transform a completion model, like GPT-3, into a chatbot model like ChatGPT.
In practice, fine-tuning can involve techniques such as instruction fine-tuning, reinforcement learning with human feedback, and single-task fine-tuning.
This article recaps what we learned in our most recent webinar, where we delve into the intricacies of fine-tuning Large Language Models (LLMs).
Watch the Full Webinar
LLMs show promise in accelerating the building of text-based applications such as chatbots and question-answering interfaces. But evaluating, knowing when to fine-tune, and fine-tuning LLMs is no small feat. Our recent webinar covers these topics to help you build your LLM apps successfully.

Why do we fine-tune LLMs?
Fine-tuning Large Language Models (LLMs) is a strategic endeavor that can significantly impact AI applications' utility, efficiency, and safety.
Performance Control
Enhancing Base Model Performance:
Fine-tuning acts as a catalyst in boosting the performance of the base model. By training the model on a specialized dataset, fine-tuning refines its understanding and response generation capabilities, often leading to improved accuracy and relevance in the generated outputs.
Greater Control over LLM Actions:
Fine-tuning provides a mechanism to exercise control over the actions of LLMs, enabling the creation of unique products or features. Through fine-tuning, developers can mold the model's behavior to align with a project's specific requirements and guidelines, ensuring that the model acts as a reliable and predictable asset.
Modularization
- Creation of Multiple Specialized Small Models: The journey from a generalized model to a task-specific model often involves the creation of multiple specialized small models. These models, each fine-tuned for a particular task, form a modular AI setup where different models cater to other functionalities within a system.
- Lower Memory and CPU Footprint: Smaller, specialized models are generally lighter on resources, requiring less memory and CPU power to function effectively.
- Less Latency: With a lower computational burden, these models can provide quicker responses, which is crucial for real-time applications.
- Dedicated Models: Having dedicated models for functions like content filtering or summarizing ensures that each function is performed by a model optimized for that particular task, leading to better performance and accuracy.
Fewer Dependencies
- Data Privacy: Managing and fine-tuning models in-house substantially mitigates the risks of exposing sensitive data to external services. This self-sufficiency in model management ensures that sensitive or proprietary data remains within the organization's control, adhering to data privacy regulations and standards.
- Cost-Efficiency: In-house fine-tuning circumvents the costs of third-party LLMs, especially those accessed through APIs. Moreover, having in-house expertise and resources for fine-tuning allows for scalability per the organization's needs without incurring additional costs from external services. This financial efficiency and enhanced performance through fine-tuning make a compelling case for investing in in-house fine-tuning expertise and resources.
LLM fine-tuning methods
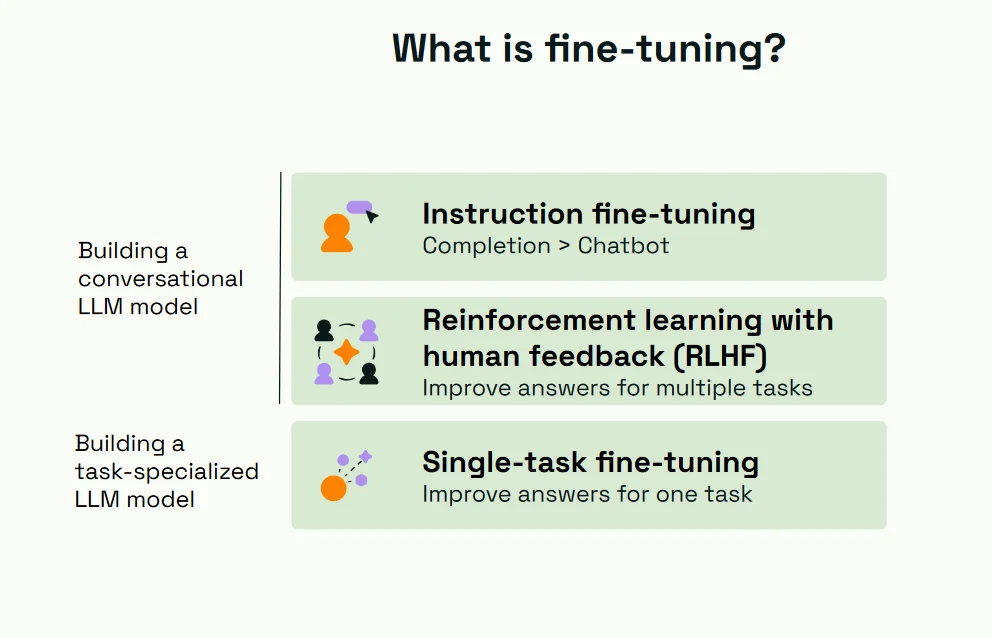
What is instruction fine-tuning?
One of the primary forms of fine-tuning is Instruction Fine-Tuning (IFT). This technique involves adapting the model to follow specific instructions or answer questions using a specialized dataset. The goal is to transform a general-purpose model into one that can understand and adhere to specific instructions embedded within the input data.
A classic example of this transition is the evolution from completion models like GPT-3 to chat models like ChatGPT. While GPT-3 is adept at generating text based on a given prompt, ChatGPT, post-instruction fine-tuning, excels at engaging in more interactive and instruction-driven conversations. This shift amplifies the model's ability to follow instructions meticulously, making it a suitable candidate for conversational applications.
The benefits of instruction fine-tuning are manifold. It enhances the model's instruction-following capability and opens doors for creating tailored solutions. By focusing on instruction adherence, this fine-tuning technique paves the way for creating chatbots or interactive AI assistants that can understand and respond to user instructions effectively, thereby enriching the user experience.
Combining instruction fine-tuning with RLHF
A complementary approach to Instruction Fine-Tuning is the implementation of Reinforcement Learning with Human Feedback (RLHF). This technique encompasses human feedback to refine the responses generated by the model iteratively. In a typical RLHF setup, model-generated responses are reviewed and rated by humans, and this feedback is used to fine-tune the model to generate better responses in subsequent iterations.
RLHF can significantly contribute to creating robust chatbot models when used with instruction fine-tuning. The combined effect of structured instruction adherence and iterative refinement through human feedback can result in a model that follows instructions accurately and provides more contextually relevant and user-friendly responses.
However, the journey towards effective reinforcement learning with human feedback isn't without hurdles. The practical application of this technique can be limited due to the complexity and the specific nature of the input required. Gathering consistent and high-quality feedback necessitates a well-structured setup and, often, considerable human labor. Moreover, the feedback loop must be meticulously designed to ensure the model learns effectively from the feedback it receives, which can be demanding.
Single task fine-tuning
Diverging from the broader scope of instruction fine-tuning and RLHF, Single Task Fine-Tuning (STFT) zeroes in optimizing LLMs for narrow, specific tasks such as toxic content detection or text summarization. In this fine-tuning technique, the model is tailored using a highly relevant dataset to the specific task at hand, thereby aligning the model's behavior closely with the desired outcome for that task.
The allure of Single Task Fine-Tuning lies in its potential to ramp up the precision in task execution significantly. By honing the model's focus on a singular task, STFT can push the boundaries of what LLMs can achieve, often resulting in a performance that might surpass generalized models or even specialized models not fine-tuned for the task.
The benefits extend beyond just enhanced performance. STFT opens up the possibility for organizations to have dedicated models for different functionalities, each excelling in its designated task. This approach not only ensures higher accuracy and efficiency but also allows for a more modular and organized setup, especially beneficial in scenarios where a variety of specialized tasks need to be executed concurrently.
Through the lens of fine-tuning, the expansive potential of LLMs can be harnessed and directed towards solving specific problems or improving particular aspects of a system. Whether it's instructing a model to adhere to guidelines, refining its responses through human feedback, or tailoring it for a specific task, fine-tuning stands as a pivotal process in the journey towards making LLMs a valuable asset in the ever-evolving landscape of artificial intelligence.
Put it to practice
Learn how to fine-tune large language models (LLMs) for specific tasks using Kili Technology. This tutorial provides a step-by-step guide and example on fine-tuning OpenAI models to categorize news articles into predefined categories.
Getting Started with Fine-Tuning

Embarking on the journey of fine-tuning requires a strategic approach towards data acquisition and model training. Here are some avenues and considerations to explore:
Open-Source Data
Open-source data is freely available and accessible to anyone. This enables developers to utilize vast amounts of data without incurring significant costs. For example, the Dolly dataset from Databricks is a massive 15k open-source dataset of instruction-following records that can be used to fine-tune an LLM.
However, you may not always find open-source data perfectly adapted to the specific domain you want to deal with. The availability and quality of such data can significantly impact the fine-tuning process and the resultant model performance.
User Feedback
User feedback, primarily used in reinforcement learning from human feedback, is pivotal in refining model responses to align better with human expectations and requirements. If users consistently give feedback about specific types of responses, the model can be fine-tuned to provide those responses better.
However, the feedback often tends to be single-dimensional and may not provide a holistic view required for model specialization. This limitation makes user feedback less recommended for a broader model specialization.
Distillation
Distillation involves generating examples, instructions, and responses using a large language model. The generated data is then used to train a smaller model, thus transferring knowledge from the larger model to the smaller one.
That said, the trustworthiness and domain expertise limitations of the teacher model (the large language model) can pose challenges. If the teacher model lacks expertise in a specific domain, the distilled data and the resultant student model will inherit these limitations.
Human Review or Generation
Engaging humans to generate instructional data or question-answer pairs can effectively curate high-quality training data for fine-tuning. However, this approach is resource-intensive and requires skilled human resources, posing a scalability challenge, especially for larger projects or more nuanced domains.
Combining Distillation with Human Review or Generation
Combining distillation and human review can mitigate the limitations of each method while leveraging their strengths. The large language model can quickly generate a broad range of examples through distillation. Then, human reviewers can review these examples, correcting errors and ensuring the examples are relevant and high-quality. This combination allows for the scalability of machine-generated examples and the precision of human review, resulting in a more effective fine-tuning process.
Fine-Tuning LLMs with Kili Technology

Regarding fine-tuning LLMs, Kili Technology offers a robust and efficient platform that can streamline the process. The platform's capabilities are not limited to just one fine-tuning technique but incorporates several for optimal results.
Initial Setup and Project Creation
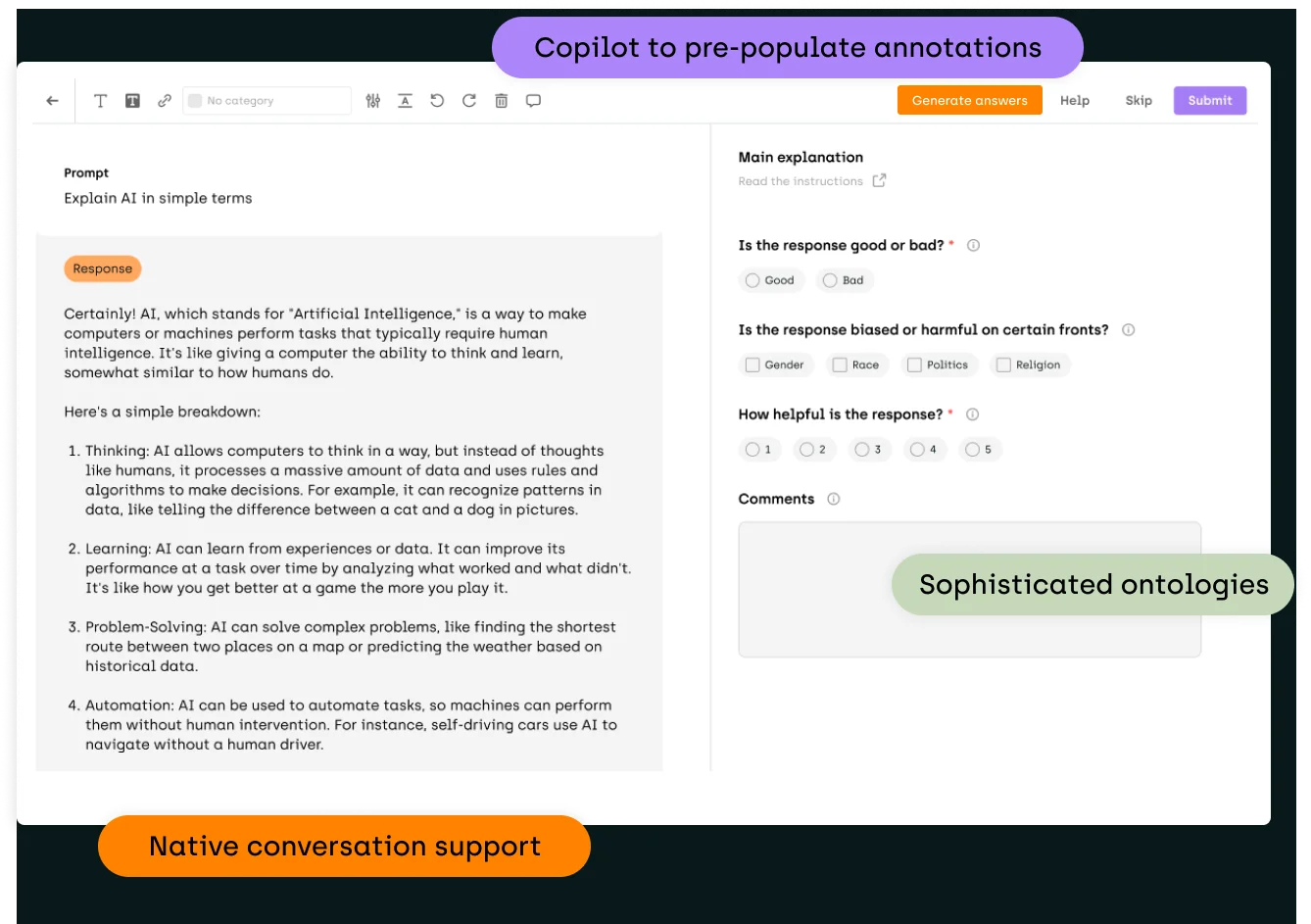
The first step in using Kili for fine-tuning involves setting up the project using the Python SDK. This includes defining an ontology or a set of categories for classification, creating the project, and then populating the project with data.
Generating Initial Predictions
Once the project is set up, the next step is to generate initial predictions. This can be done by calling on the OpenAI API. Different models, such as the Keri model, can be used depending on the specific needs and trade-offs between speed, quality, and cost. The model generates pre-annotations based on predefined classes and handles any unclassified content.
Importing Predictions and Simulating Human Input
After generating the initial predictions, they are imported to Kili. Here, users can review these pre-annotations and provide feedback. Kili allows for the simulation of human input or feedback using random generation to expedite this process. This creates a human-model intersection of union, allowing users to determine if the model's output matches the expected results or needs further fine-tuning.
Fine-Tuning and Re-Predicting
Following human feedback, the fine-tuning process begins. This involves exporting the reviewed labels and making adjustments based on the differences between the model's predictions and the human-labeled data. Once the model is fine-tuned, it can be re-predicted on top of the existing projects.
Iterative Fine-tuning
One of the critical features of Kili is its support for iterative fine-tuning. Users can repeat the process of generating predictions, reviewing results, and fine-tuning the model as many times as necessary until the desired level of accuracy is achieved. This iterative process ensures the model continually improves and adapts to new data and feedback.
By combining machine learning capabilities with human feedback, Kili Technology offers a balanced approach that leverages the strengths of both for optimal results.

Watch video
Conclusion
Fine-tuning stands at the crossroads of theory and practical utility in Large Language Models. It is the bridge that carries the theoretical prowess of LLMs into real-world applications, enabling organizations to tailor AI solutions according to their unique requirements.
As the AI community progresses towards open-source LLMs and in-house fine-tuning, the onus is on the practitioners and organizations to explore and adopt fine-tuning techniques that align with their use case requirements. The endeavor may present challenges, but the rewards - performance, control, and customization - are worth the effort.
Embark on the journey of fine-tuning, explore the available resources, and tailor your models to carve a niche in the expanding universe of AI applications. The path is laden with learning and the potential to unlock new vistas of AI capabilities, waiting to be harnessed for creating solutions that resonate with the needs and aspirations of the modern world.
Build high-quality LLM fine-tuning datasets
The best AI agents are built on the best datasets. See how our tool can help you build the best dataset to fine-tune an LLM.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

