
.png)


_logo%201.svg)


AI Summary
How do I automate labeling for geospatial datasets?
In the dynamic realm of geospatial data analysis, precise and efficient annotation of geospatial data holds utmost significance. As the accessibility of high-resolution satellites and aerial imagery continues to expand, there arises an escalating demand for proficient methodologies and tools to extract valuable insights from these extensive datasets.
This article aims to provide a comprehensive walkthrough of the optimization process for automating geospatial annotation, encompassing steps such as model pre-training and iterative refinement. We will delve into diverse models suitable for various contexts while emphasizing the pivotal role of human quality assurance in guaranteeing top-notch geospatial data annotation.
Auto data labeling vs. manual data labeling
The field of geospatial data labeling has been experiencing a significant shift from manual to more automated processes. This transition is driven by several key factors:
- Volume of Data: The sheer volume of geospatial data being generated today from sources like satellites, drones, and IoT devices is enormous. Manually labeling such large datasets is not only time-consuming but also practically unfeasible. A semi-automated approach to data labeling, on the other hand, can handle large datasets more efficiently, with algorithms performing the bulk of the work and humans validating and refining the results.
- Advancements in Machine Learning Models: The evolution and advancement of machine learning models have significantly facilitated the shift towards semi-automated data labeling. These models, trained on vast datasets, can detect a wide range of known objects and categories, as well as objects they have never seen before. This greatly enhances their performance on a wide range of segmentation tasks and can generate fully automatic annotation.
- Accuracy and Consistency: While manual data labeling is prone to human error and inconsistencies, semi-automated processes can provide more accurate and consistent results. Algorithms can detect patterns and features that might be missed by the human eye, while human involvement ensures that the context and nuances are correctly interpreted.
- Speed: Semi-automated data labeling can process and label data much faster than manual methods. This speed is crucial in many applications of geospatial data, where timely analysis and decision-making are important.
- Cost-Effective: While there is an initial investment in setting up semi-automated data labeling systems, they can be more cost-effective in the long run. They reduce the need for a large workforce and can operate round the clock, leading to significant cost savings.
- Scalability: Semi-automated data labeling systems can easily scale up or down based on the volume of data, which is a significant advantage when dealing with fluctuating data volumes.
- Quality Control: Semi-automated labeling allows for a balance between human expertise and algorithmic efficiency. While algorithms can process large amounts of data quickly, human involvement ensures that the quality of the labels is maintained, as humans can understand and interpret complex scenarios better than algorithms.
In the context of geospatial data, these factors are particularly important. Geospatial data often involves complex and varied features, from bodies of water and landforms to buildings and other man-made structures. Semi-automated data labeling tools, like those provided by Kili Technology, can handle this complexity and variety more effectively and efficiently than manual methods, providing a balance between speed, accuracy, and quality.
Automated data labeling process for geospatial data
Step 1: Start with a smaller pre-labeled dataset
Commence the automated data labeling process for geospatial data by assembling a smaller pre-labeled dataset that encompasses the diverse characteristics and intricacies of the larger dataset. This pre-labeled dataset will serve as the initial training data for your model.
Step 2: Integration with a data labeling tool
Integrate the larger unlabeled dataset along with the smaller pre-labeled dataset into the powerful framework of Kili Technology. This integration can be accomplished through our API or by utilizing the manual upload feature available on our platform.

Step 3: Customize your labeling interface
Leverage the customization capabilities offered by Kili Technology to adapt the labeling interface according to your specific needs. This customization empowers you to optimize the annotation process when the expertise of human labelers is required.
Step 4: Model-based Pre-Annotation:
To speed up the annotation process, Kili Technology also allows you to use your custom models to pre-annotate your data. This could be particularly useful for geospatial data as models may already exist for detecting certain features like bodies of water, buildings, etc. This model-based pre-annotation not only speeds up the process but also improves the quality of the labels. On Kili, you can upload these model-based predictions to your project, and you may also have multiple models and "tag" these predictions with the source model via GraphQL API.
Step 5: Smart Tool Enabled Labeling
Enhance your annotation process with automation tools that significantly boost both efficiency and accuracy. Kili Technology's platform integrates advanced features such as smart tool-enabled labeling, which offers substantial benefits by accelerating the annotation process and improving its precision. A key component of this feature is the integration of Meta's Segment Anything Model (SAM). SAM is a foundation model designed to handle generalized image segmentation tasks, making it a valuable tool in the comprehensive labeling process.
Step 6: Programmatic QA and Human-in-the-loop Annotation:
While pre-annotation is valuable, it is crucial to maintain human involvement to ensure the attainment of high-quality annotations. Implement programmatic quality assurance techniques provided by Kili Technology to enable your data labeling team to focus on handling more complex and nuanced data, while leveraging automated checks to verify the accuracy and consistency of the annotations.

Quality Control and Post-Processing:
Upon the culmination of the annotation process, Kili Technology furnishes an array of quality control tools to ensure the accuracy and integrity of the annotations. Through these tools, you have the opportunity to thoroughly review and rectify any potential discrepancies or errors within the annotations, guaranteeing a refined and reliable dataset. Once you have ascertained the desired level of quality and precision in the labels, you can seamlessly export the labeled dataset for subsequent analysis or utilization as training data for models, facilitating further exploration and advancements in your geospatial data analysis endeavors.
Model Training and Iteration
The labeled dataset obtained can now be harnessed for training machine learning models. As these models evolve and advance, they can be seamlessly reintegrated into Kili's platform, enabling enhanced pre-annotation capabilities. This establishes a valuable feedback loop, wherein the iterative utilization of improved models facilitates a continuous enhancement of label quality and process efficiency.
By capitalizing on this iterative feedback loop, the potential for refining and optimizing both the precision of the labels and the overall efficiency of the annotation process is perpetually fostered.
Learn More
Discover how foundation models are revolutionizing AI development and how you can overcome their limitations in real-life applications. Join us for an insightful webinar where we'll delve into the common mistakes and challenges of models like GPT-4 and SAM.
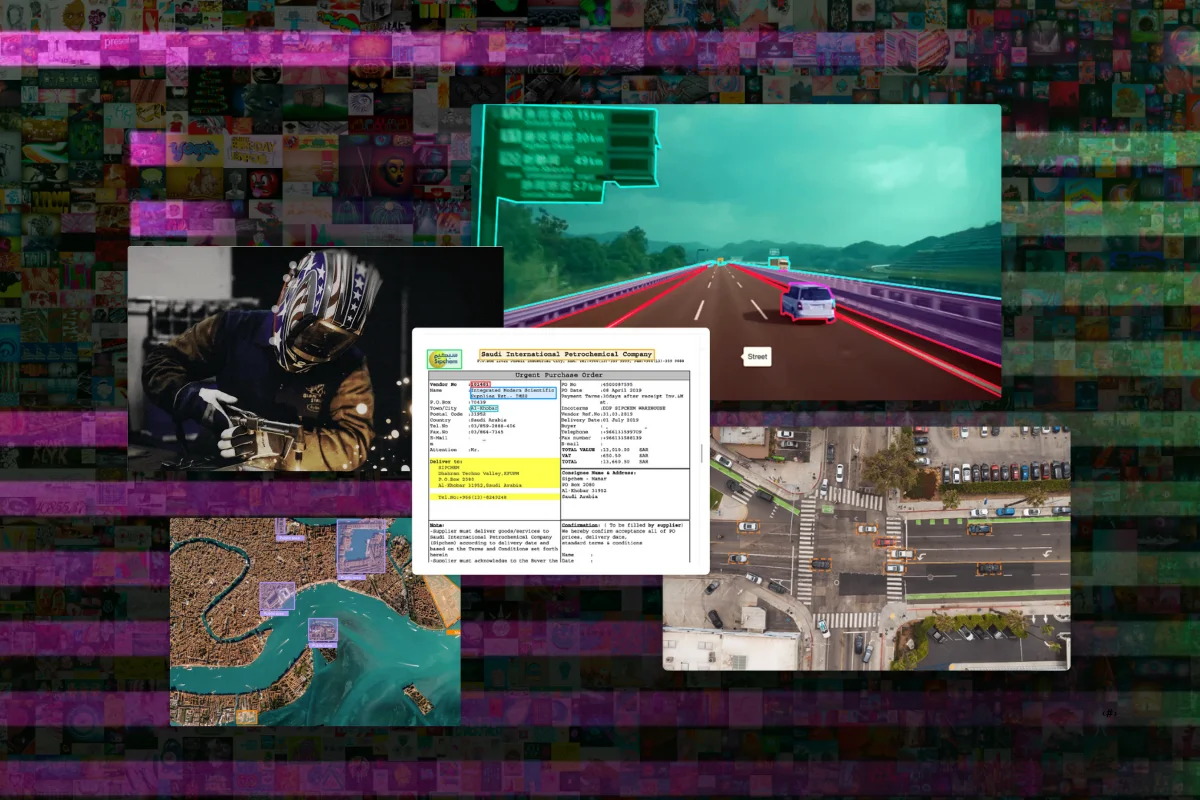
Models for Geospatial Data Annotation and Their Use Cases
Segment Anything Model:
The "Segment Anything Model" is a machine learning model specifically designed for segmenting objects from their backgrounds in geospatial data, such as satellite imagery.
A simple yet impactful use case for this model is urban green space analysis. By applying the Segment Anything Model to satellite imagery, it becomes possible to accurately segment and identify areas of vegetation and green spaces within an urban environment. This information can be crucial for urban planners and environmental researchers.
Urban planners can utilize the segmented data to assess the distribution and quality of green spaces, aiding in the development of strategies to improve urban livability and sustainability. Environmental researchers can analyze the segmented vegetation areas to study biodiversity, monitor changes in vegetation cover, and evaluate the effectiveness of urban greening initiatives.
The Segment Anything Model empowers effective geospatial analysis, enabling evidence-based decision-making for urban green space planning and management.

Source: https://github.com/facebookresearch/segment-anything
DeepLab:
DeepLab is a state-of-the-art deep learning model for semantic image segmentation. It utilizes convolutional neural networks (CNNs) to accurately assign semantic labels to individual pixels in an image, effectively distinguishing different objects or regions.
A simple use case for DeepLab is in autonomous driving. By applying DeepLab to the input from a vehicle's onboard cameras, the model can segment and identify various elements on the road, such as vehicles, pedestrians, traffic signs, and lanes. This information is vital for intelligent decision-making in autonomous vehicles, enabling them to navigate safely and respond appropriately to their surroundings. DeepLab's precise segmentation capabilities aid in improving the perception of the environment, enhancing object detection, and facilitating reliable path planning and collision avoidance systems.
By harnessing DeepLab's advanced segmentation capabilities, autonomous driving systems can operate with heightened accuracy, efficiency, and safety.

Panoptic segmentation results obtained by Panoptic-DeepLab. Left: Video frames used as input to the panoptic segmentation model. Right: Results overlaid on video frames.
Source: https://ai.googleblog.com/2020/07/improving-holistic-scene-understanding.html
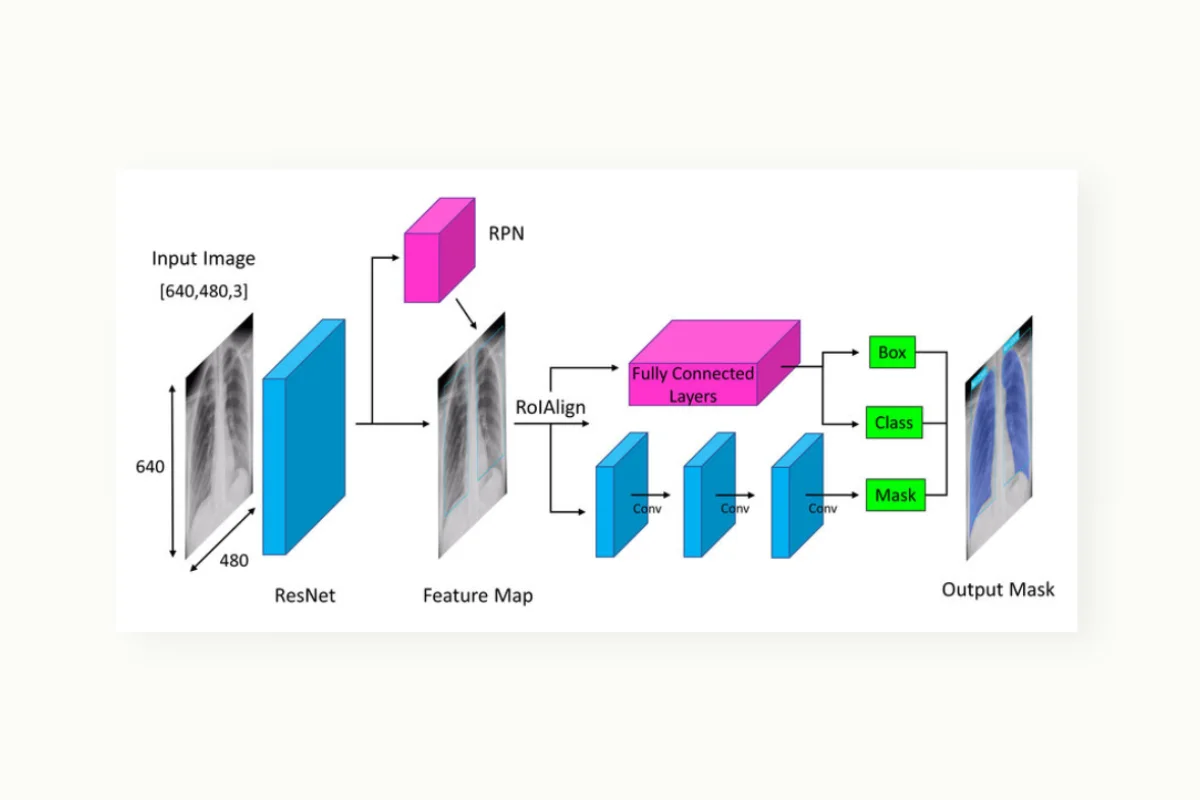
Mask R-CNN:
Mask R-CNN is a deep learning model for instance segmentation. It extends the Faster R-CNN model by adding a pixel-level segmentation branch, enabling accurate identification and segmentation of individual objects within an image.
A possible use case for Mask R-CNN is in medical imaging, where it can be employed to precisely segment and delineate different organs or tumors in MRI scans or X-rays. This allows for more accurate diagnosis, treatment planning, and medical research by providing detailed information about the location and extent of abnormalities within the images.
U-Net:
U-Net is a convolutional neural network architecture primarily used for image segmentation tasks. It consists of an encoder-decoder network design that allows for precise pixel-wise segmentation of objects in an image.
One possible use case for U-Net is in biomedical image analysis, particularly for segmenting cellular structures. For instance, in medical microscopy, U-Net can be employed to accurately segment cell nuclei, enabling quantitative analysis and aiding in various medical research applications such as cancer diagnosis, drug discovery, and pathology studies. U-Net's ability to handle intricate structures and produce highly detailed segmentations makes it well-suited for various image segmentation tasks.
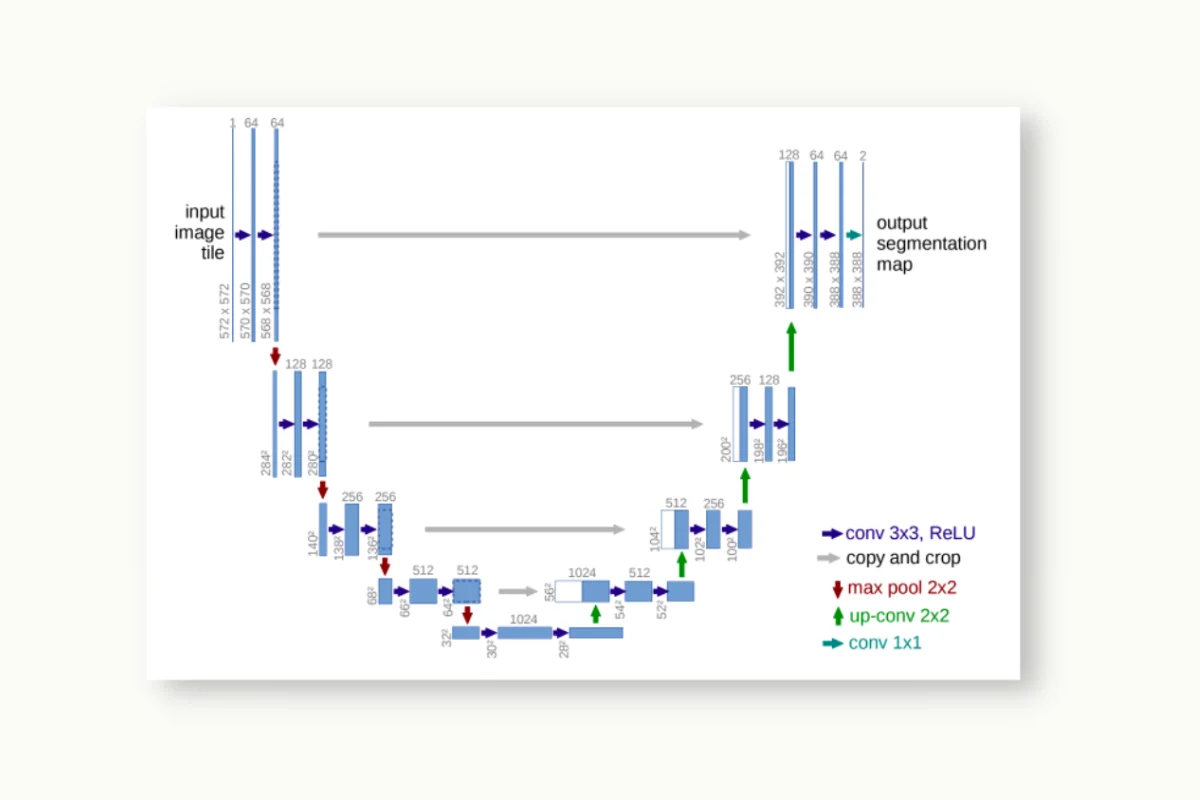
Source: https://paperswithcode.com/method/u-net
YOLO (You Only Look Once):
YOLO is a popular object detection algorithm known for its real-time performance. It takes an input image and predicts bounding boxes and class labels for multiple objects in a single pass through the network.
A simple use case for YOLO is in video surveillance systems, where it can detect and track objects in real-time, enabling applications such as crowd monitoring, anomaly detection, and object counting. YOLO's efficient architecture and fast inference speed make it well-suited for scenarios that require real-time object detection, ensuring quick and accurate analysis of video streams. Chick out our detailed guide about YOLO in this article.
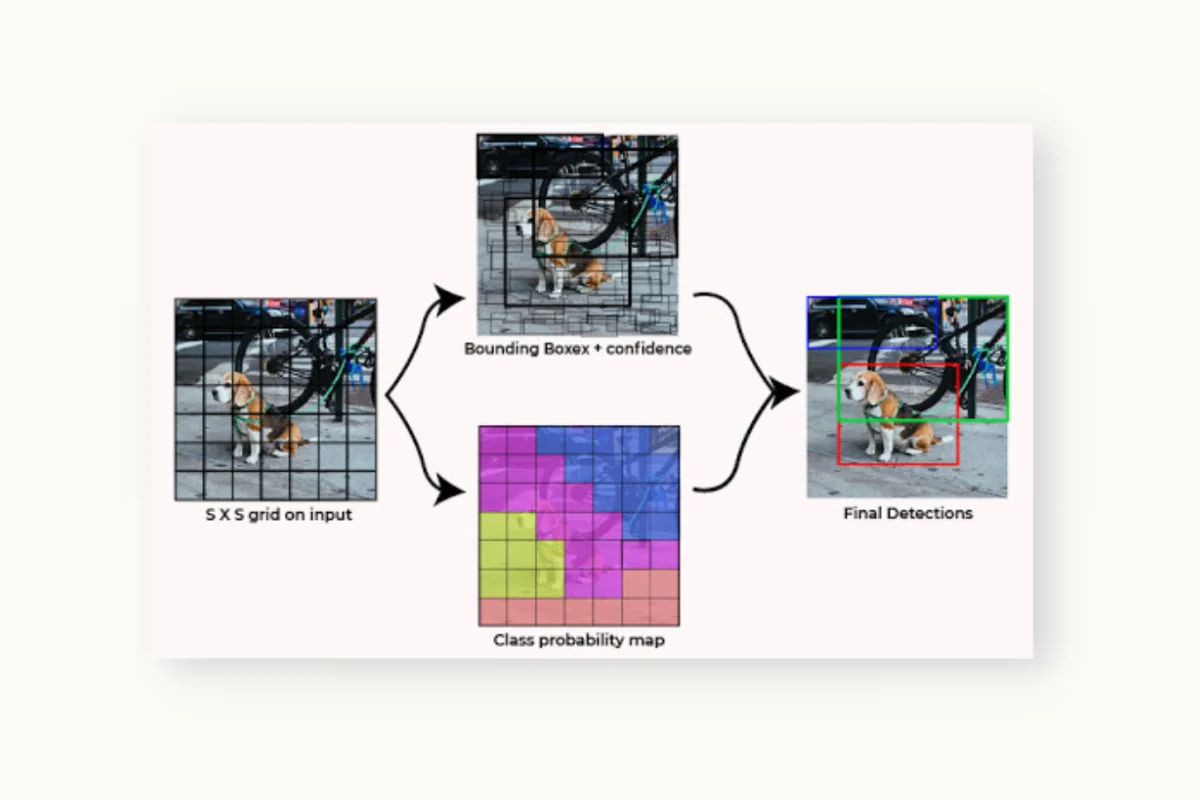
Source: https://www.geeksforgeeks.org/yolo-you-only-look-once-real-time-object-detection/
Quick note on these models: All of the models mentioned are open-source and have implementations available in popular deep learning libraries like TensorFlow and PyTorch. However, you should always check the license before using them in a commercial project.
The Importance of Quality Assurance
While leveraging models for the automation of geospatial data annotation brings notable efficiency, the integration of human expertise remains imperative for quality assurance. Human involvement is indispensable in validating and rectifying the annotations generated by the models. This practice guarantees not only swift data processing but also upholds the utmost level of accuracy and dependability.
In essence, automating geospatial data annotation entails a cyclical procedure that involves the utilization of pre-trained models, refining annotations through human expertise, and iterating the process via active learning. The selection of an appropriate model tailored to the specific use case is paramount. Nevertheless, even the most advanced models require human supervision to ensure stringent quality assurance, guaranteeing that annotations respect the exacting standards essential for effective geospatial analysis.
Watch video
Frequently asked questions
What is automated data labeling for geospatial data?
Automated data labeling for geospatial data refers to the process of using machine learning algorithms or models to assign labels or annotations to geospatial data automatically. It involves leveraging computational methods to identify and annotate various geospatial elements, such as objects, boundaries, or features, in satellite imagery, aerial photos, or other geospatial datasets.
By automating this process, it eliminates or reduces the need for manual annotation, enabling efficient and scalable labeling of geospatial data for tasks like object detection, land cover classification, or urban planning.
Why is geospatial data labeling and annotation hard?
Geospatial data labeling and annotation pose challenges due to the inherent complexity and diversity of spatial information. Geospatial datasets often exhibit high variability, encompassing various terrains, objects, and environmental conditions. Accurately identifying and annotating intricate geospatial features requires specialized domain knowledge, as well as dealing with potential data quality issues like noise, occlusions, and scale variations. Additionally, the large-scale nature of geospatial datasets adds to the difficulty, necessitating efficient and scalable annotation methods to handle the sheer volume of data.
What is the best tool to automate labeling geospatial data annotation?
There isn't a single "best" tool for automating geospatial data annotation as it depends on various factors such as specific requirements, dataset characteristics, and available resources. However, in Kili Technology we provide a very powerful tool to automate geospatial data annotation. It leverages pre-trained models or custom models to annotate geospatial data with speed and accuracy. Our platform also supports active learning for further optimization, as well as integration of human expertise for quality assurance. With our tool, you can easily and efficiently annotate datasets of different sizes, ensuring that all your geospatial projects are consistently labeled with the highest level of accuracy.
What are some best practices for auto labeling geospatial data?
When it comes to auto-labeling geospatial data, implementing best practices is crucial for effective results. It is recommended to begin with a smaller pre-labeled dataset that represents the diversity of the larger dataset. Utilizing a reliable data labeling tool like Kili's platform with its customizable interfaces can enhance efficiency during the annotation process. Incorporating pre-existing models for initial pre-annotation not only improves speed but also enhances the overall quality of the labels. Introducing smart tools or AI-enabled features can further enhance accuracy and speed. Programmatic quality assurance techniques should be employed to ensure the annotations meet high standards. Finally, it is important to iterate the process by retraining models and incorporating human expertise to continuously improve the quality of the annotations over time.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
