
.png)


_logo%201.svg)


AI Summary
Introduction
In our preceding publication, we delved into the captivating realm of foundation models and their versatility in various machine learning applications. Within that context, we addressed the constraints inherent in these models and outlined methodologies to enhance their output quality through fine-tuning. A notable aspect of our discourse centered on DinoV2, a transformer model developed by Meta, which proved particularly effective in a classification scenario. Specifically, we showcased how DinoV2 could be fine-tuned to achieve substantial improvements in its ability to classify images of casting products into "good" or "defective" categories.
Nonetheless, our prior article only provided a glimpse into this fascinating subject. In this present work, we shall conduct a more comprehensive exploration of DinoV2's characteristics and functionalities. Furthermore, we will offer a detailed exposition of the Jupyter notebook briefly referenced previously, thereby equipping you to fine-tune and effectively apply DinoV2 to your own machine learning use cases.
What is DinoV2?
DINOv2 (DIscriminative NOise Contrastive Learning V2), introduced by Meta Research in April 2023, is a self-supervised approach for training computer vision models. Being self-supervised, DINOv2 eliminates the need for labeled input data, allowing models built on this framework to acquire more comprehensive insights into image content. The code powering DINOv2, along with example models showcasing its application in diverse tasks such as depth estimation, semantic segmentation, and instance retrieval, has been made openly available by Meta Research.
DINOv2 utilizes a self-supervised learning technique, enabling the model to be trained on unlabeled images, yielding two significant advantages. Firstly, this approach eliminates the need for substantial time and resource investment in labeling data. Secondly, the model gains more profound and meaningful representations of the image input since it is directly trained on the images themselves.
Training the model directly on the images allows it to capture all the contextual information present in each image. To prepare the data for training, Meta researchers combined data from curated and uncurated sources, and these images were subsequently embedded. The uncurated images were processed to remove duplicates before being merged with the curated images to form the initial training dataset.
Prior to the introduction of DINOv2, a common method for building comprehensive computer vision models that captured image semantics involved a pre-training step using image-text pairs. For instance, models like OpenAI's CLIP, capable of tasks ranging from image retrieval to classification, were trained on a dataset of 400 million image-text pairs.
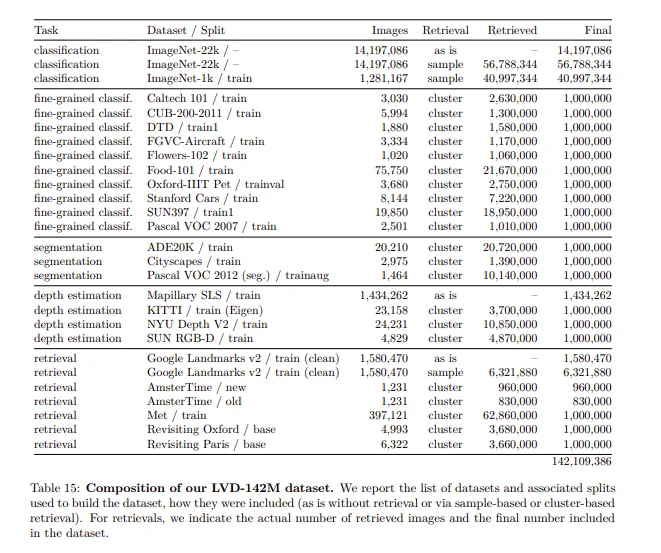
In contrast, DINOv2 diverges from this approach by being trained on 142,109,386 images. The DINOv2 paper features a table illustrating the sourcing of data for this dataset.
Self-supervised learning, briefly explained:
Self-supervised learning is a type of machine learning paradigm where a model is trained to learn from the data itself, without the need for human-labeled annotations. Instead of relying on external labels provided by humans, the model generates its own supervisory signals from the input data, making it a form of unsupervised learning.
In traditional supervised learning, a model is trained using labeled data, where each input is associated with a corresponding target output. For example, in image classification, a dataset of images would be labeled with corresponding class labels (e.g., "cat," "dog," "car," etc.), and the model learns to map the input images to the correct labels.
In self-supervised learning, the training process involves creating a surrogate task based on the data itself. This surrogate task requires the model to predict some part of the input data from another part of the same data. By formulating the task in this way, the model learns to understand the underlying structure and relationships within the data, effectively learning useful representations.
For example, in the context of computer vision, a self-supervised learning task could involve training a model to predict the missing portion of an image based on the rest of the image. The model learns to recognize meaningful visual patterns and representations during this process. Another common self-supervised task is "image rotation," where the model is trained to predict the angle of rotation applied to an image.
Self-supervised learning has gained popularity due to its ability to leverage large amounts of unlabeled data, which are often more readily available than labeled datasets. It has shown promising results in various domains, including computer vision, natural language processing, and speech recognition. Pre-training models with self-supervised learning and then fine-tuning them on specific downstream tasks has become a successful approach for transfer learning, enabling models to perform well even with limited labeled data for the target task. DinoV2’s advantages
DinoV2 exhibits a remarkable set of high-performance characteristics that seamlessly lend themselves as inputs for straightforward linear classifiers. Its inherent adaptability renders it an optimal choice for constructing versatile foundational structures to address a wide array of computer vision tasks. Notably, DinoV2 demonstrates exceptional predictive prowess in tasks encompassing classification, segmentation, and image retrieval. Particularly intriguing is its superior performance in depth estimation, where the features of DinoV2 significantly surpass those of specialized state-of-the-art pipelines.
Do we still need to fine-tune DinoV2?
According to Meta's claims, while DinoV2 demonstrates notable performance without requiring fine-tuning, certain industry-specific scenarios necessitate the refinement of DinoV2 to uphold the most stringent accuracy standards. Several examples illustrate the significance of fine-tuning:
- Medical Imaging: In the healthcare domain, machine learning models play a crucial role in analyzing medical images like X-rays, MRIs, and CT scans. Given the critical nature of accurate diagnoses and treatments, fine-tuning DinoV2 can enhance the model's precision in detecting anomalies, diseases, and conditions within these images.
- Autonomous Vehicles: The safe navigation of autonomous vehicles relies heavily on computer vision models. These models must precisely identify and classify objects such as vehicles, pedestrians, traffic signs, and road markings. Fine-tuning DinoV2 becomes essential to minimize classification errors and prevent potential accidents.
- Facial Recognition: Facial recognition systems find applications in various fields, from smartphone unlocking to identifying suspects in surveillance footage. For these systems to be effective, high accuracy is paramount to avoid false positives and negatives, necessitating fine-tuning for optimal performance.
- Quality Control in Manufacturing: Machine learning models are employed in manufacturing to inspect products and identify defects. The accuracy of these models directly impacts product quality and manufacturing efficiency, making fine-tuning a critical step.
Fortunately, achieving high accuracy scores through fine-tuning is a relatively straightforward process, as demonstrated in our tutorial.
How do we fine-tune DinoV2?
Our tutorial demonstrates the utilization of the DINOv2 self-supervised vision transformer model with Kili Technology's image annotation tool for generating pre-annotations in a defect detection use case.
Modern foundation models (FMs) exhibit remarkable versatility, with large language models excelling in natural language processing and dedicated image processing models demonstrating exceptional performance in computer vision tasks like object detection and classification. To further enhance its performance on a specific task, such as image classification, an FM can be retrained on a limited set of examples in a process known as fine-tuning.
The tutorial encompasses the following steps:
- Configuring a project on Kili.
- Fine-tuning the DINOv2 model using a small set of labeled images on Kili.
- Generating pre-annotations on a set of images for labeling.
- Evaluating the quality of the generated pre-annotations within the Kili interface.
Let's start our tutorial by creating a new API key from our Kili dashboard. Login to your account and open "My Account" >> "My API Keys" section and create a new key to use in our code to create an API client object.
After setting the client we create a new project and download the Casting product image data for quality inspection from Kaggle.

Using Kili's SDK we can simulate the manual labeling process by calling the following code snippet.
nb_manually_labeled_assets = 200json_response_array = [
{"CLASSIFICATION_JOB": {"categories": [{"confidence": 100, "name": output_class}]}}
for output_class in output_class_array
]kili.append_labels(
project_id=project_id,
asset_external_id_array=external_id_array[:nb_manually_labeled_assets],
json_response_array=json_response_array[:nb_manually_labeled_assets],
label_type="DEFAULT",
seconds_to_label_array=[
random.randint(60, 300) for _ in range(nb_manually_labeled_assets) # simulate labeling time
],
)
# Replace the project_id below with your own project_id!
print(f"\nAccess your project at: https://cloud.kili-technology.com/label/projects/{project_id}")Once we have the project and the annotations configured, we can start the training phase. To be able to use the DinoV2 model we can acquire the pre-trained model from Torch's model hub. When we feed the model with an image, we notice that the output is a 384-dimensional vector, which serves as the image's embedding.
This embedding is a vector that represents the image within the latent space of the DINOv2 model. It encapsulates a compressed representation of the image, making it valuable for various tasks, including image classification. In order to make class predictions, it is necessary to augment the DINOv2 model with a classification head.
The following code snippet represents a compact neural network that will take the embeddings as its input and produce a score for the binary classification task.
class DinoVisionTransformerClassifier(nn.Module):
def __init__(self):
super(DinoVisionTransformerClassifier, self).__init__()
self.transformer = deepcopy(dinov2_vits14)
self.classifier = nn.Sequential(nn.Linear(384, 256), nn.ReLU(), nn.Linear(256, 1))
def forward(self, x):
x = self.transformer(x)
x = self.transformer.norm(x)
x = self.classifier(x)
return x
model = DinoVisionTransformerClassifier()After that, we choose a loss function and an optimizer for the training process. Binary cross-entropy loss serves as a conventional loss function for binary classification tasks. It quantifies the disparity between the predicted class and the actual ground truth class. A higher loss value indicates poorer model performance.
To mitigate the loss, we employed the Adam optimizer, a widely adopted optimization algorithm for neural networks. Adam is a stochastic gradient descent method that calculates adaptive learning rates for each parameter of the model, facilitating more effective training and convergence.
Finally, we set the training loop for a total of 15 epochs like the following:
epoch_losses = []
for epoch in range(num_epochs):
print("Epoch: ", epoch)
batch_losses = []
for data in dataloaders["train"]:
# get the input batch and the labels
batch_of_images, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# model prediction
output = model(batch_of_images.to(device)).squeeze(dim=1)
# compute loss and do gradient descent
loss = criterion(output, labels.float().to(device))
loss.backward()
optimizer.step()
batch_losses.append(loss.item())
epoch_losses.append(np.mean(batch_losses))
print(f"Mean epoch loss: {epoch_losses[-1]}")
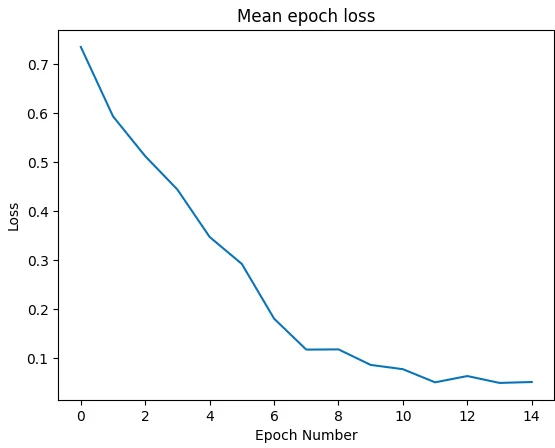
print("Finished training!")After the full execution of the training loop, we plot the graph of the loss during the training phase. As evident from the plot displayed below, the loss progressively decreases with an increasing number of epochs, indicating the successful learning of image classification by the model.
When the loss ceases to decrease further, it signifies that the model has converged, and the training can be halted. In this instance, the training could have been concluded after 11 epochs.
Now, as we have the model fine-tuned on the labeled images from Kili, we can use it to generate pre-annotations on a set of images to label. Let's start by downloading unlabeled images using Kili's API like the following:
non_labeled_assets = kili.assets(
project_id=project_id,
fields=["id", "content", "externalId", "jsonMetadata"],
status_in=["TODO"], # we choose assets to label
first=max_nb_assets_to_label,
download_media=True,
)
print("\nNumber of fetched assets to label: ", len(non_labeled_assets))After that we switch the model to evaluation mode since we don't want to update the weights of the model anymore. After feeding all the fetched data to the model and getting the generated labels, we proceed to upload the predictions to Kili, where they serve as pre-annotations (predictions) and inference labels.
The pre-annotations prove beneficial for the labelers, as they are displayed within the Kili interface, expediting the asset labeling process. Simultaneously, the inference labels serve the purpose of assessing the model's performance against the judgments made by the labelers.
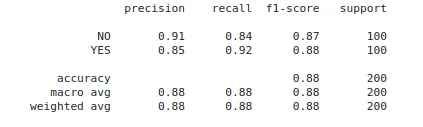
Finally, we can evaluate the performance of the fine-tuned model by using the classification_report function and we can see that we get an accuracy of ~95% for the fine-tuned DINOv2 model on our binary classification task.
The full code is available in this notebook.
Fine-tune your Computer Vision models with the best data
Complete any image or video labeling task up to 10x faster and with 10x fewer errors. Try out our platform for free.
What’s next? Shifting Focus to High-Quality Data
As our exploration into the potential of DinoV2 and other self-supervised learning models progresses, it becomes increasingly evident that the quality of the training data plays a pivotal role in determining their performance. While DinoV2 has showcased remarkable results without necessitating fine-tuning, the data itself emerges as the next frontier in elevating the efficacy of these models.
Datasets characterized by high quality, diversity, and careful curation can profoundly enhance the learning capabilities of models like DinoV2. Although the model's capacity to learn from a diverse array of images is a compelling attribute, the inherent quality and diversity of these images significantly influence the model's comprehension and predictive prowess.
In conclusion, while DinoV2 and its counterparts in self-supervised learning have already demonstrated impressive outcomes, the future advancements of these models pivot on the quality of the data employed during training. By directing our attention to high-quality data, we can continue to push the boundaries of what these models can achieve and unlock their full potential.
Additional Reading:
DINOv2: Learning Robust Visual Features without Supervision
3 Ways to Adapt a Foundation Model to Fit Your Specific Needs

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
