
.png)

_logo%201.svg)


AI Summary
Document Annotation and its Everyday Uses
Document annotation is one of the fundamental cornerstones of modern AI-powered technology and without it, the gap between humans and machines would be difficult to reduce. The process of document annotation is not complicated but it serves an incredibly important purpose. By using a combination of human annotators and platforms, it is possible to create better data so that all devices and services that are dependent on machine learning and AI can benefit and become smarter.
Document annotation is a time-consuming and expensive process but by automating it through the use of annotation solutions and platforms, the cost and time requirements can be reduced significantly. Let’s take a closer look at the process of document annotation, its importance, and its everyday uses:
What is Document Annotation?
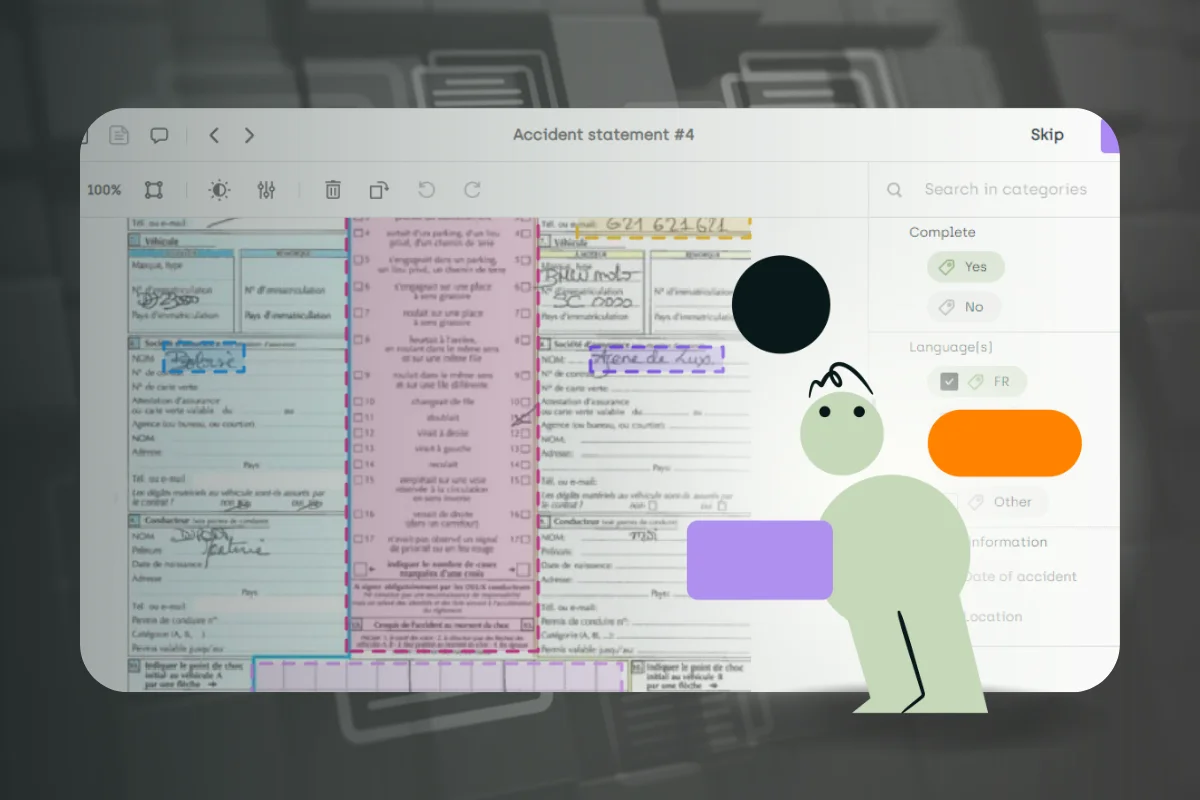
Document annotation is the process of adding labels to and organizing data in such a way that it becomes possible for computer systems to extract specific data from text sources such as documents. Without document annotation, it would not be possible for search engines to quickly extract specific data from a variety of documents such as long texts, e-books, invoices, and legal documents.
As digitalization becomes more widespread, document annotation becomes more important. This is especially important in the case of historical documents. Thanks to digitalization, these documents are now available in digital format and their contents can be analyzed and categorized much easier thanks to many tools used to document annotation.
For example, a human reader may have no problem understanding the deeper meaning behind the phrase “you are killing it”, a machine learning model, however, may not be able to understand this sentence as easily. In fact, the sentence may be mislabelled as negative or violent when in fact, in most cases, it has a wholly positive meaning. This is where document annotation comes into play, by labeling text and providing the definition of this text to a machine learning model, computers can learn to interpret the text correctly and understand the deeper meaning in complex human speech and expressions.
Correctly annotated documents can be used as training data to teach ML- and AI-models how to interpret specific text more accurately and ML- and AI-models can use the information from annotated documents as a reference point for future use.
Why is Document Annotation Required?
Document annotation makes it possible for humans and machines to better interact with each other. This might sound far-fetched at first but think about it for a second, one of the core purposes of document annotation is to make it easier for computers to understand natural language queries and respond to search queries more effectively.
Document annotation greatly improves the training data that machine learning models require to power technology such as chatbots and makes it possible for machines to understand complex human language better. Data is one of the most valuable assets that a company can own but if data is not clearly structured and accessible, it is not easy to use, which reduces its value.
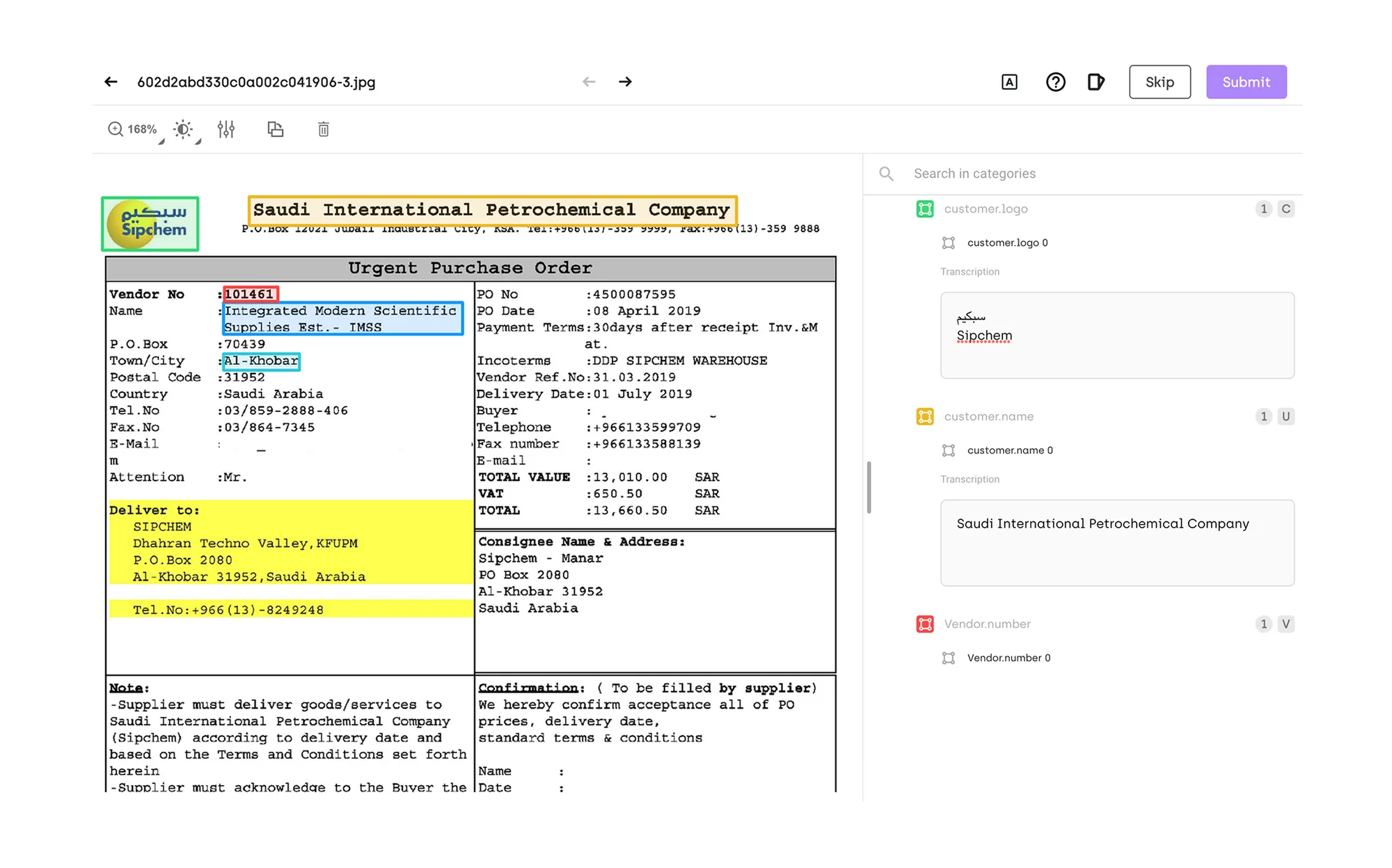
Annotated documents make it easier for search engines to find information in a variety of document types, including PDF documents, long texts, and other business documents like invoices and estimates. Since most businesses use a large number of documents on a daily basis, it only makes sense that these documents must be annotated so that the data in them can be found easily and quickly when needed. Aside from making it easier to find data, document annotation also plays an important part in the archiving and indexing of data.
Annotated documents can be indexed much quicker and easier because the annotations that they contain make it possible for machine learning algorithms to analyze the contents of the data and automatically index the document correctly according to specific parameters such as document type, contents, and sensitivity.
Training data is used to teach machine learning algorithms to automatically index data. Properly annotated documents are an essential part of this process because it teaches AI systems to correctly index documents and the information that they contain.
What are the Different Types of Document Annotation
One size does not fit all when it comes to document annotation. Different types of documents can be annotated in different methods, depending on what the data will be used for and what the desired result is. Some of the most frequently used annotation methods include:
Named Entity Recognition (NER)
This form of document annotation is also referred to as named entity recognition and it refers to the process of adding labels to predefined words or phrases.
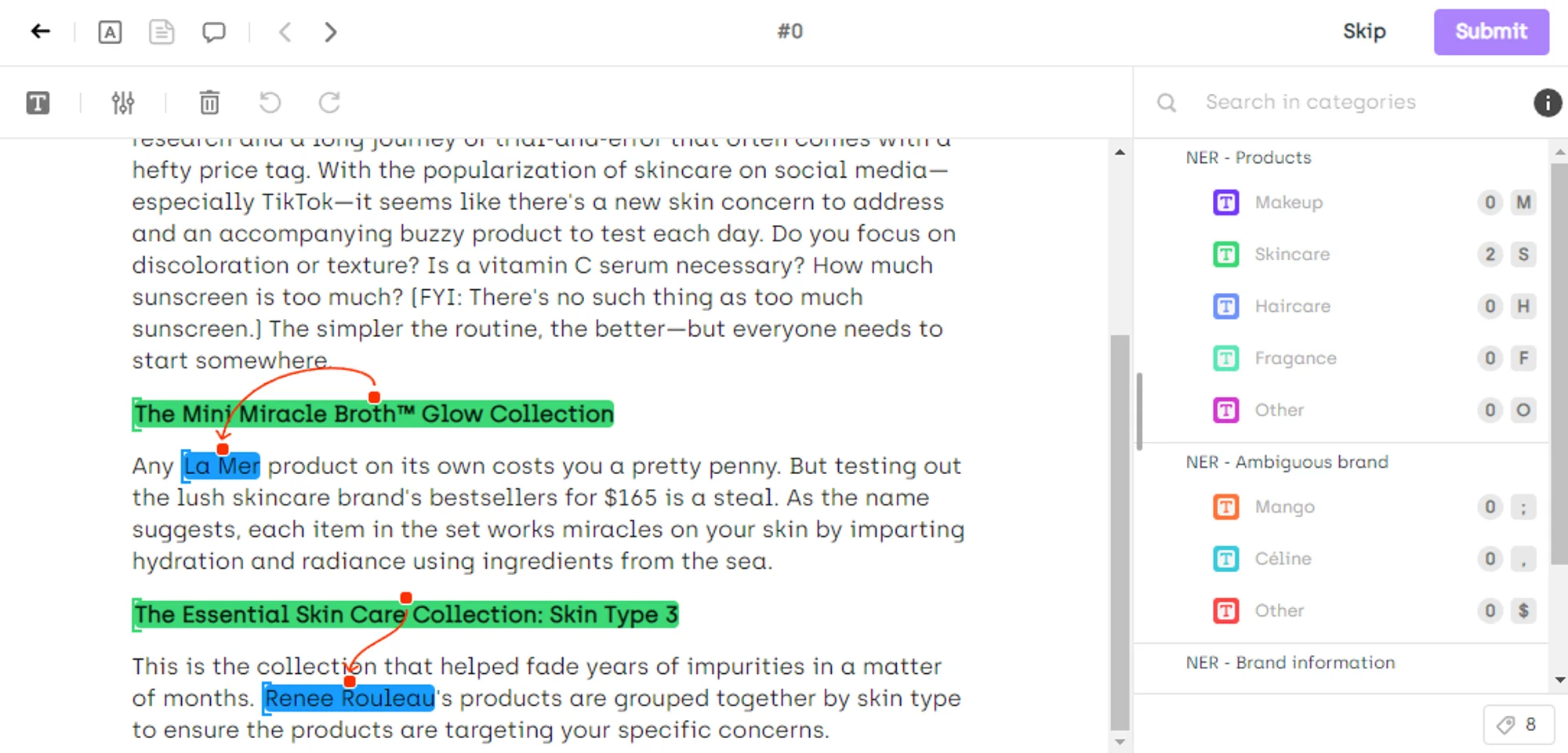
This type of annotation works well when the desired end result is to make it easier for machines to understand the subject matter of a specific text.
Named entity recognition has a large range of real-world applications, including:
- Customer Service Applications: Chatbots and some other automated processes can benefit from named entity recognition. For example, customer service requests can be routed to specific departments or people based on the contents of an email or instant chat message. By recognizing or annotating specific words in training data and teaching AI-powered systems to look for these phrases and take specific actions when they are found, customer service systems can be further automated and improved.
- Hiring and Recruitment: Named entity recognition can be used to look out for specific words or phrases in employee CVs or applications. By using automation, AI-powered systems, and machine learning, the work of HR departments can be significantly reduced. For example, named entity recognition can be used to train machine learning models to scan through vast numbers of job applications and find the right candidates. A summary of the best candidates can then be presented to human employees for review and selection.
- Medical Industry: In the healthcare sector named entity recognition can be used to process a variety of important information. By using named entity recognition documents like patient records, medical reports, and medical research can be quickly analyzed to find the appropriate information.
As can be seen from these examples, named entity recognition is a very versatile form of document annotation that can be used in almost any industry.
Sentiment Annotation
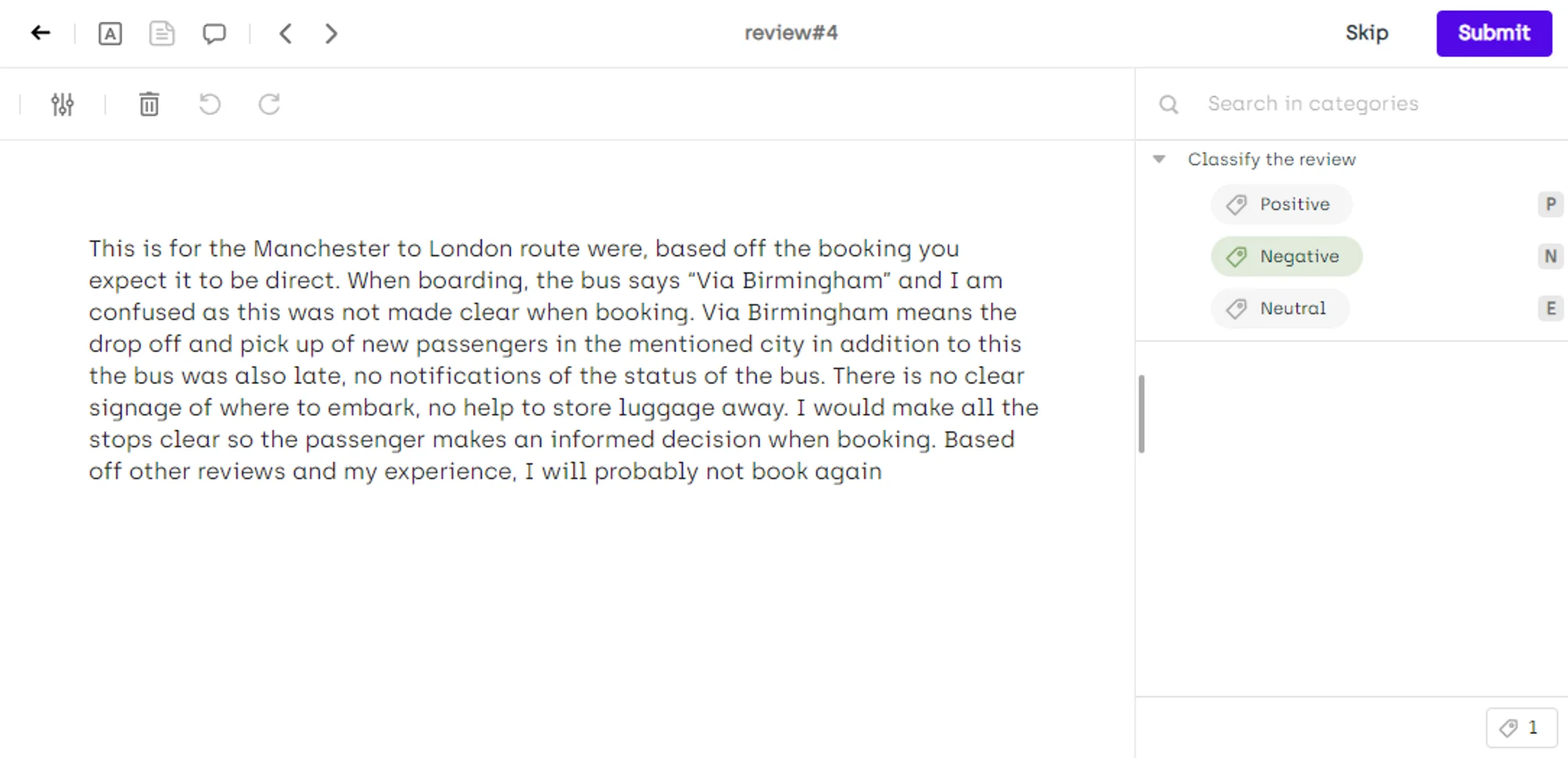
It can be difficult at times for humans to understand the sentiment behind a specific phrase or sentence, let alone for machines. This is where sentiment annotation becomes important.
Sentiment annotation is aimed at helping machine learning algorithms to understand the meaning or sentiment behind a specific phrase. By using sentiment annotation, machine learning algorithms can decide whether a phrase or word is positive, negative, or neutral. Understanding the sentiment behind the text is quite important and can be used in a variety of ways, including:
- Digital Marketing and Social Media: Sentiment annotation can be used to analyze social media posts to better understand public opinion. This is especially useful for companies that rely on social media marketing and by teaching an AI model to identify the sentiment of the text that makes up a specific social media post, companies can gain a better insight into consumer opinions. This data can then be used to develop different communication strategies.
- Deeper Customer Insights: Sentiment annotation allows AI models to better understand the sentiment behind customer interactions like reviews, e-mails, and instant messages. By analyzing these messages and looking at the sentiment behind a specific message, AI systems can automatically direct queries to specific departments or employees
- HR & Employee Engagement: Similarly to customer feedback and interactions, sentiment annotation can be used to train AI models to better interpret employee feedback and determine the sentiment behind a specific message or interaction. This type of document annotation is especially useful when a large volume of responses needs to be analyzed in a short period of time. One example of this is employee satisfaction questionnaires. By using sentiment annotation, employee responses can be analyzed much quicker and more accurately.
Semantic Annotation
Semantic annotation is a crucial part of document annotation, particularly when it comes to enhancing the capabilities of virtual assistants and chatbots. This form of annotation involves adding metadata to a document that describes the meaning of the content, making it easier for AI systems to understand and process the information.
The primary goal of semantic annotation is to improve the comprehension of customer queries by AI systems. It does this by adding industry-specific jargon or terminology to phrases, which helps chatbots recognize and understand the specific language a customer may use. This is particularly important in industries where specialized language or technical terms are commonly used.
For instance, in the medical field, a customer might use terms like "hypertension" or "myocardial infarction". A chatbot equipped with semantic annotation can recognize these terms as referring to high blood pressure and heart attack, respectively, and respond appropriately to the query.
How is the Document Annotation Process Done?
Document annotation can be done in a variety of ways but the most convenient way to do document annotation is by using an automated document annotation platform. Document annotation can be a costly and time-consuming process and by having an automated platform do much of the work for you, you can save both time and money.
As mentioned before, it is crucial that text is annotated correctly because the incorrectly annotated text will influence the accuracy of AI-powered systems. While using an automated text annotation tool or platform is by far the easiest and the most cost-effective document annotation solution, there are alternative methods. The appropriate method is almost always dependent on the data in question and the desired outcome. For example, data that will ultimately be used as training data requires much more detailed annotations and might need extra care to ensure that information is labeled correctly. In these cases, it might be prudent to use a human annotator.
It is also important to remember that there are various types of document annotation and that each type is approached a bit differently. Some examples of how to document annotation are done include:
Named Entity Recognition (NER)
Named Entity Recognition is a process where annotators identify and categorize specific parts of a text into predefined categories. These categories can include entities such as people, organizations, locations, dates, and other specific terminologies.
The first step in NER annotation is to establish the categories that will be used. For instance, if the text is about global politics, the categories might include countries, cities, political leaders, international organizations, and so on. Annotators then scan the text and assign parts of the sentence to one of these categories. This process helps in extracting structured information from unstructured text data, which is particularly useful in tasks such as information extraction, question answering, and knowledge graph construction.
Sentiment Annotation
Sentiment Annotation involves labeling a block of text, sentence, or phrase with a sentiment value, typically positive, neutral, or negative. This type of annotation is crucial for understanding the emotional tone of a text and is widely used in areas like customer feedback, sentiment analysis,, social media monitoring, and brand reputation management.
Given the subjective nature of sentiment, it's often beneficial to have multiple annotators work on the same piece of text. This ensures a more balanced and objective annotation, as what might be perceived as negative by one person could be seen as neutral or even positive by another. By comparing and reconciling the annotations from multiple annotators, a more accurate sentiment label can be assigned to the text.
Semantic Annotation
Semantic Annotation involves adding metadata to a text that describes the meaning or context of the content. This can include adding industry-specific jargon or accounting for factors like sarcasm or irony.
For instance, in a text about finance, an annotator might add labels to identify financial terms or jargon. Similarly, if a sentence contains sarcasm or irony, the annotator might add a label to indicate this, helping AI systems to understand the intended meaning of the sentence.
Semantic annotation is particularly useful for tasks like text mining, information retrieval, and machine translation, where understanding the context and meaning of the text is crucial
The Importance of a Good Document Annotation Tool for Machine Learning
Data annotation tools play a pivotal role in the annotation process and in the realm of machine learning. They serve as the bridge between raw data and the machine learning models that need this data to learn and improve. Here's why having good text and image annotation tools is crucial for machine learning:
- Quality of Training Data: The quality of the training data directly influences the performance of machine learning models. A data annotation tool ensures that the data is accurately labeled, which in turn leads to more reliable and efficient models.
- Efficiency and Speed: Document annotation can be a time-consuming process, especially when dealing with large volumes of data. An efficient data annotation tool can automate this process, significantly reducing the time and effort required, and allowing for quicker deployment of machine learning models.
- Cost-Effective: Manual data annotation can be expensive, particularly when it requires the expertise of domain specialists. Automated annotation tools can drastically cut these costs, making the process more affordable.
- Scalability: As machine learning models evolve and the amount of data increases, the need for annotation grows as well. A good annotation tool can easily scale to accommodate these growing needs, ensuring that the machine learning models continue to receive the high-quality training data they require.
- Versatility: Different machine learning tasks may require different types of annotation. A good annotation tool can handle a variety of annotation types, from Named Entity Recognition (NER) to sentiment and semantic annotation, making it a versatile asset in the machine learning pipeline.
Ensuring that document annotation is done correctly
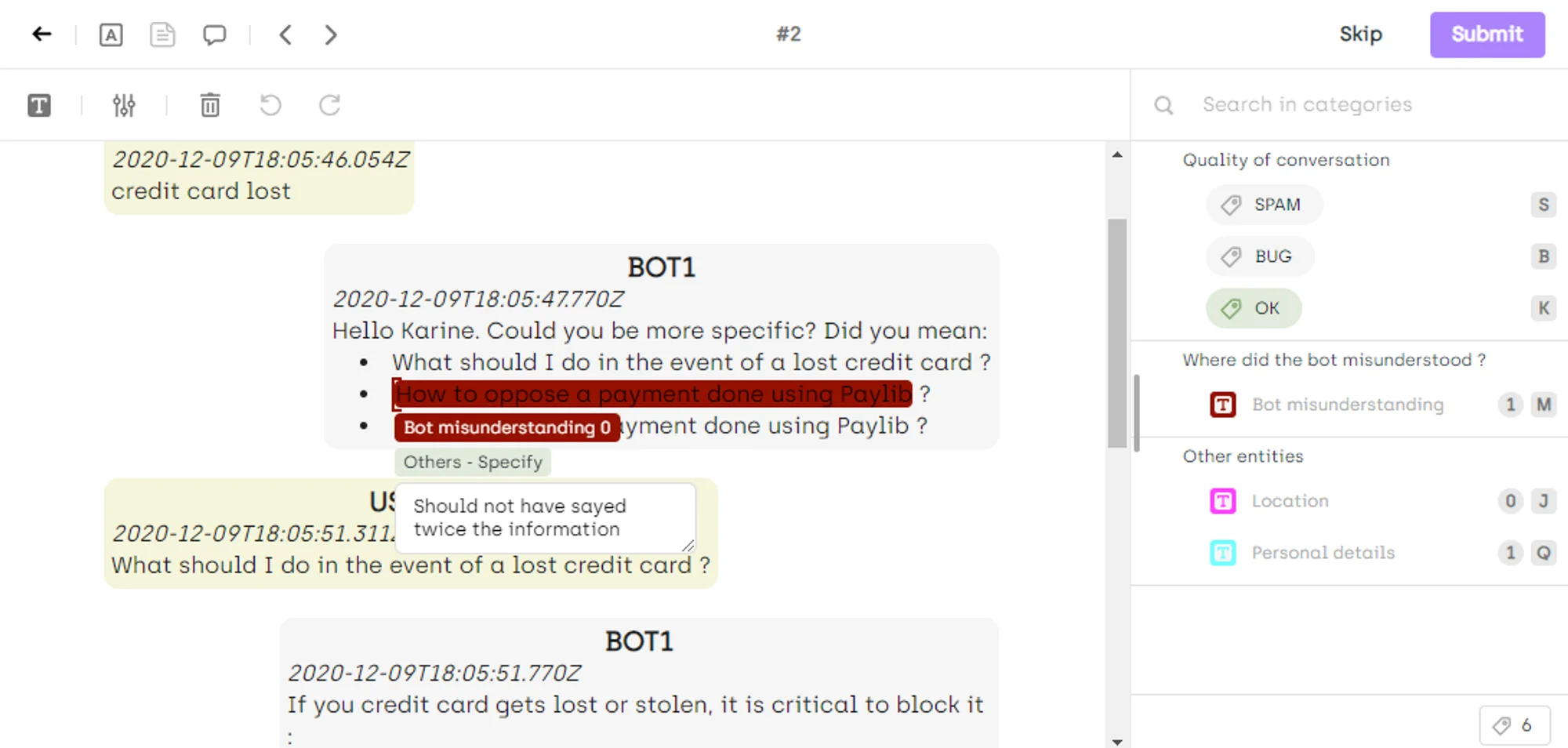
Ensuring the quality of document annotation is a critical aspect of preparing data for machine learning models. The accuracy and reliability of the annotations directly impact the performance of the models trained on this data. Here are the key steps a data labeling team should take to ensure the quality of document annotation, incorporating best practices from the Kili platform:
Multiple Annotation and Continuous Feedback
The first step in ensuring quality is to employ multiple annotations. This process involves having the same text annotated by different annotators. The rationale behind this approach is that multiple perspectives can help reduce subjectivity and bias in the annotations.
In addition, continuous feedback is a crucial part of this process. Labelers should be encouraged to provide feedback and ask questions in case of doubt or lack of understanding through a dedicated panel. Reviewers and managers can then answer these questions, providing more information to the labeler and ensuring a better understanding of the task at hand.
Inter-Annotator Agreements and Issue Resolution
The next step is to measure the level of agreement between the annotators, a process known as inter-annotator agreement. This involves comparing the annotations from different annotators to see how often they agree on the labels assigned to the same piece of text.
If there's a high level of agreement, it's a good indication that the annotation is reliable. If there's disagreement, it can highlight areas of ambiguity or confusion that need to be addressed. In cases where two or more annotators agree and one disagrees, the majority opinion is usually considered correct.
Reviewers and managers can also raise issues on annotated assets and then send the assets back to the same (or different) labeler for correction, ensuring that any errors or inconsistencies are addressed promptly.
Random and Targeted Reviews
Performing random and targeted reviews is another important step in ensuring the quality of annotations. Using the Explore view and available filters, reviewers can focus on the most relevant assets, classes, and labelers. For instance, they might focus on labels generated today for a regular, daily check, or focus on new labelers to check their work more closely.
Automated review can also be activated to make the Kili app randomly pick assets for review. This eliminates human bias when assigning assets to be reviewed and ensures a more balanced review process.
Quality Metrics and Programmatic QA
Adding quality control metrics such as Consensus and Honeypot can help measure the performance and accuracy of the annotations. Consensus is useful for evaluating simple classification tasks, while Honeypot can be used to measure the performance of a new team working on your project.
Setting up programmatic QA can simplify and boost your QA process by using a QA bot. This can help avoid a lot of back and forth between your labelers and reviewers, making the process more efficient.
A data labeling team can ensure that their document annotations are of the highest quality, providing a solid foundation for training reliable and effective machine learning models.
A Case Study on Insurance:
The importance of a good data annotation tool for machine learning can be best understood through a real-world application. Let's consider the case of Europe’s first insurtech company, which leveraged AI to outperform customer expectations.
Luko faced a significant challenge when it acquired a Pet and Dog Liability insurance company. The company had little automation on the pet health portfolio they took over, resulting in most invoices needing to be manually processed. This was a time-consuming task that led to longer claim processing times, which was not in line with Luko's commitment to delivering a first-in-class customer experience.
To overcome this challenge, Luko turned to Kili Technology. Kili's data annotation tool allowed Luko to industrialize the production of high-quality training data, which was crucial for improving the performance of their AI model. The platform enabled faster annotation, which meant less time spent per invoice and access to a larger dataset to train the AI model. This, in turn, decreased project lead times.
The impact of using Kili Technology's data annotation tool was significant. Luko was able to improve the model performance from 45% to 70%, leading to shorter wait times for customers and a more efficient and effective AI model. This resulted in a 50% increase in customer satisfaction, thanks to rapid claims processing.
A good data annotation tool is not just a nice-to-have, but a must-have in the world of machine learning. It ensures the delivery of high-quality training data, increases efficiency, reduces costs, and scales according to needs, all while offering the versatility to handle different types of annotation tasks. These factors combined make it an indispensable tool in the development and improvement of machine learning models.
Conclusion
Document annotation is one of the most important aspects of modern AI-powered technology because it serves to decrease the gap between humans and machines. Document annotation makes it possible for machines to develop a deeper understanding of human language and the technology has several considerable applications. High-quality document annotations are one of the best ways in which training data can be improved, which will ultimately result in better technology and allow humans to focus on more complicated tasks while automated technology assists with repetitive and mundane tasks. Document annotation has many advantages for both large and small companies and it is imperative that more organizations invest in this technology. Automated annotation platforms and solutions have made it easier and more affordable for everyone to participate in the process of document classification and annotation and as such the use of the document, annotation is set to continue increasing in the future.
Learn more!
Discover how training data can make or break your AI projects, and how to implement the Data Centric AI philosophy in your ML projects.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

