
.png)


_logo%201.svg)


AI Summary
Introduction
The mastery of entity recognition and text classification is crucial for machine learning engineers in the field of natural language processing (NLP). These techniques underpin various applications, from chatbots to content moderation. Key aspects include understanding different learning methods, evaluating models using performance metrics, and optimizing data preprocessing and feature engineering. As AI advances, addressing challenges like few-shot learning, multimodal integration, adversarial robustness, and ethical considerations will be vital for NLP's ongoing development.

Brief Overview of Natural Language Processing (NLP)
As artificial intelligence (AI) continues to make strides, natural language processing (NLP) has emerged as one of its most significant subfields. NLP focuses on enabling machines to understand, interpret, and generate human language, which ultimately helps bridge the gap between humans and computers.
Importance of Entity Recognition and Text Classification in NLP
Entity recognition and text classification are important tasks in natural language processing (NLP) because they help to extract relevant information from unstructured textual data, which can be used to improve various applications, such as search engines, chatbots, and recommendation systems.
Entity recognition involves identifying and classifying named entities such as people, organizations, locations, dates, and other types of entities in text. This is important because it can help to extract important information from text and make it more usable for downstream applications. For example, if you're building a recommendation system for a bookstore, you might want to extract the names of authors, book titles, and other relevant entities from customer reviews to help inform your recommendations.
Text classification involves categorizing text into predefined categories or classes. This is important because it can help to organize and filter large volumes of text, making it more manageable for further analysis. For example, if you're analyzing customer feedback for a product, you might want to classify the feedback into positive, negative, or neutral categories to help identify common themes and areas for improvement.
Fundamentals of Entity Recognition
Definition and Importance of Entity Recognition
Entity recognition, also known as named entity recognition (NER), is a process that identifies and categorizes real-world objects, or "entities," within a text. These entities can include names of people, organizations, locations, and more. By accurately recognizing entities, machines can better understand the context of a given text and perform more complex tasks.
Types Of Entities: Named, Nominal, and Pronominal
Entities can be classified into three main types: named, nominal, and pronominal. Named entities are proper nouns, such as "New York City" or "Apple Inc." Nominal entities are common nouns, like "car" or "dog," while pronominal entities are pronouns that refer to other entities, such as "he" or "she.”
Popular Techniques for Entity Recognition
- 1. Rule-based methods: These methods rely on handcrafted rules and patterns, often using regular expressions, to identify entities in a text.
- 2. Supervised learning: In this approach, a model is trained on a labeled dataset, learning to recognize entities based on features extracted from the text.
- 3. Unsupervised learning: These methods cluster similar words or phrases together, identifying entities without the need for labeled data.
- 4. Hybrid methods: Combining rule-based and machine learning techniques, hybrid methods aim to leverage the strengths of both approaches.
Evaluating Entity Recognition Models: Precision, Recall, and F1-score
Precision, recall, and F1-score are commonly used metrics to evaluate entity recognition models. Here's how they are defined:
- 1. Precision: Precision is the number of true positive (TP) entities detected by the model divided by the total number of entities detected by the model (true positive + false positive). Precision measures the proportion of entities that the model correctly identified among all the entities it identified. A high precision score means that the model is accurate in identifying entities.
- Precision = TP / (TP + FP)
- 2. Recall: Recall is the number of true positive entities detected by the model divided by the total number of true positive entities in the data. Recall measures the proportion of entities that the model correctly identified among all the entities that were present in the data. A high recall score means that the model is able to identify most of the entities.
Recall = TP / (TP + FN)
- 3. F1-score: F1-score is the harmonic mean of precision and recall. It provides a balance between precision and recall and is often used as a single summary metric to evaluate entity recognition models. A high F1-score means that the model is performing well in terms of both precision and recall.
F1-score = 2 (precision recall) / (precision + recall)
To evaluate an entity recognition model using these metrics, you need to have a labeled dataset (i.e., a dataset where the entities are annotated). Then, you can run your model on this dataset and compare the predicted entities with the labeled entities. You can calculate precision, recall, and F1-score using the formulas mentioned above. A high precision, recall, and F1-score are desirable for a good entity recognition model.
Fundamentals of Text Classification
Definition and Importance of Text Classification
Text classification is the process of assigning predefined categories, or "labels," to a given text based on its content. This technique is essential for tasks like sentiment analysis, spam detection, and topic categorization.
Common Applications: Sentiment Analysis, Topic Categorization, and Spam Detection
- 1. Sentiment analysis: This involves determining the sentiment or emotion expressed in a text, such as positive, negative, or neutral.
- 2. Topic categorization: This task consists of assigning a text to one or more predefined topics or categories.
- 3. Spam detection: Identifying and filtering out unwanted or malicious messages, such as spam emails or comments.
Popular Techniques for Text Classification
- 1. Traditional methods: Naïve Bayes, decision trees, and support vector machines (SVMs) are widely used for text classification, relying on statistical methods and feature extraction.
- 2. Deep learning methods: Convolutional neural networks (CNNs) and recurrent neural networks (RNNs) can automatically learn features from raw text, often resulting in improved performance.
- 3. Transfer learning and pre-trained models: Techniques like BERT, GPT, and RoBERTa leverage large-scale pre-trained models, fine-tuned on a labeled dataset.
- a. Fine-tuning involves training the model on a specific task, such as sentiment analysis, topic classification, or intent recognition, by providing it with a labeled dataset that includes examples of the different classes that you want the model to classify.
- b. Transfer learning involves reusing the pre-trained weights of the model and adapting them to the specific task at hand. This allows the model to learn from a smaller labeled dataset and achieve better performance.
Best Practices and Tips for Entity Recognition and Text Classification
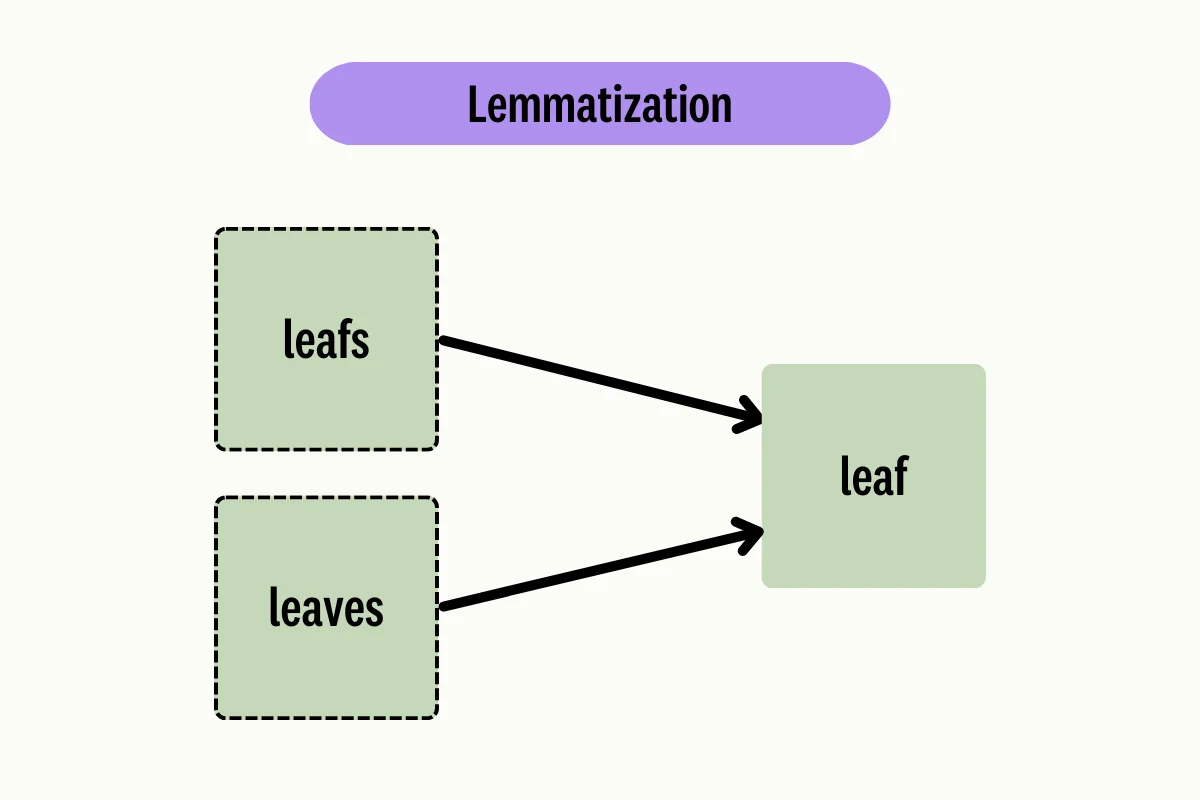
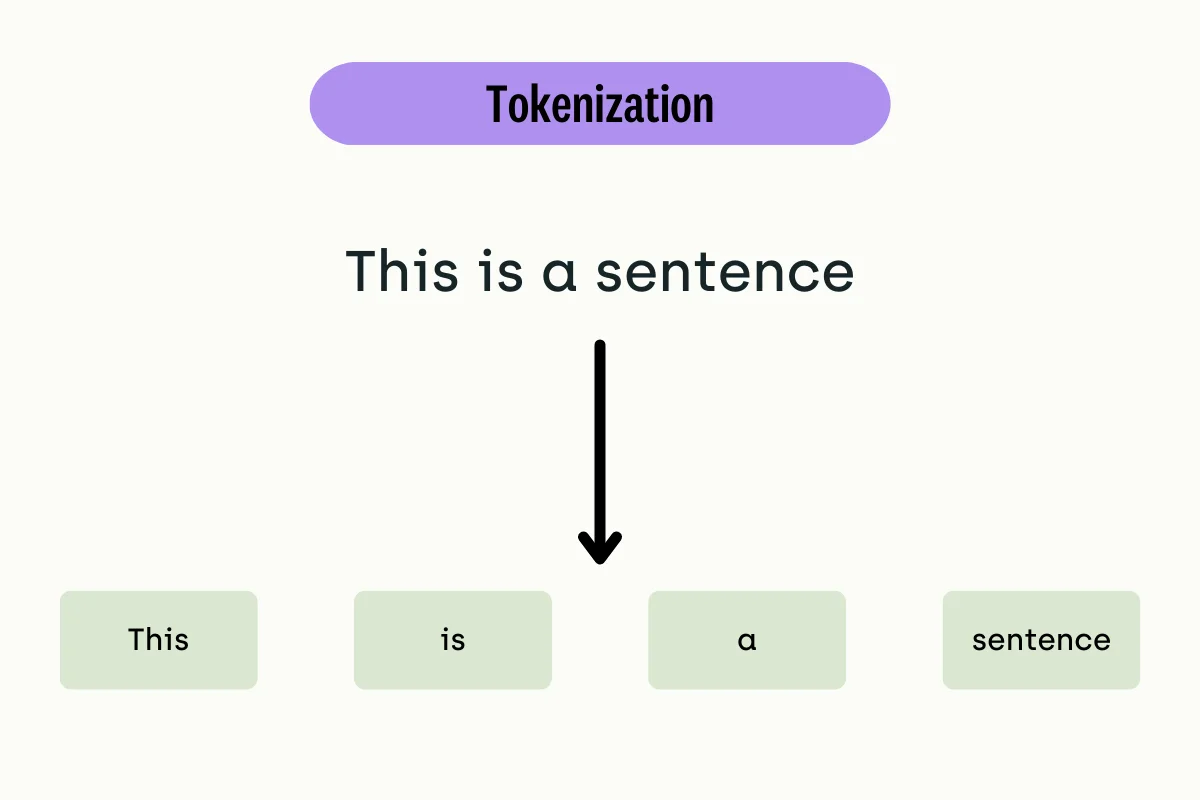
Data Preprocessing: Tokenization, Stemming, and Lemmatization
Before diving into modeling, it's crucial to preprocess your data. Tokenization involves breaking text into individual words or tokens. Stemming reduces words to their root forms, while lemmatization goes a step further by considering the context and part of speech. These techniques help reduce noise and improve model performance.

Feature Engineering: Bag-Of-Words, TF-IDF, and Word Embeddings
Transforming raw text into numerical features is essential. Bag-of-words creates a matrix with text documents as rows and words as columns, indicating word frequency. TF-IDF (term frequency-inverse document frequency) is an extension of the bag-of-words approach that adjusts word importance based on how frequently it appears in the entire dataset. Word embeddings, like Word2Vec or GloVe, represent words as continuous vectors, capturing semantic relationships between them.
Handling Imbalanced Datasets: Resampling and Cost-Sensitive Learning
Imbalanced datasets can lead to biased models. Techniques like oversampling (creating copies of minority class instances) or undersampling (removing instances from the majority class) help balance class distribution. Cost-sensitive learning assigns different weights to classes, making misclassification of the minority class more penalized during training.
Hyperparameter Tuning and Model Selection
Optimizing model hyperparameters is crucial for achieving top performance. Techniques like grid search, random search, or Bayesian optimization help find the best combination of hyperparameters. Model selection involves comparing different algorithms and selecting the one that performs best on your data.
Ensuring Model Explainability and Interpretability of AI Output
As AI systems become more integrated into our lives, it's essential to understand how they make decisions. Techniques like LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations) help provide insights into model predictions, fostering trust and promoting responsible AI use.
Real-World Use Cases and Applications
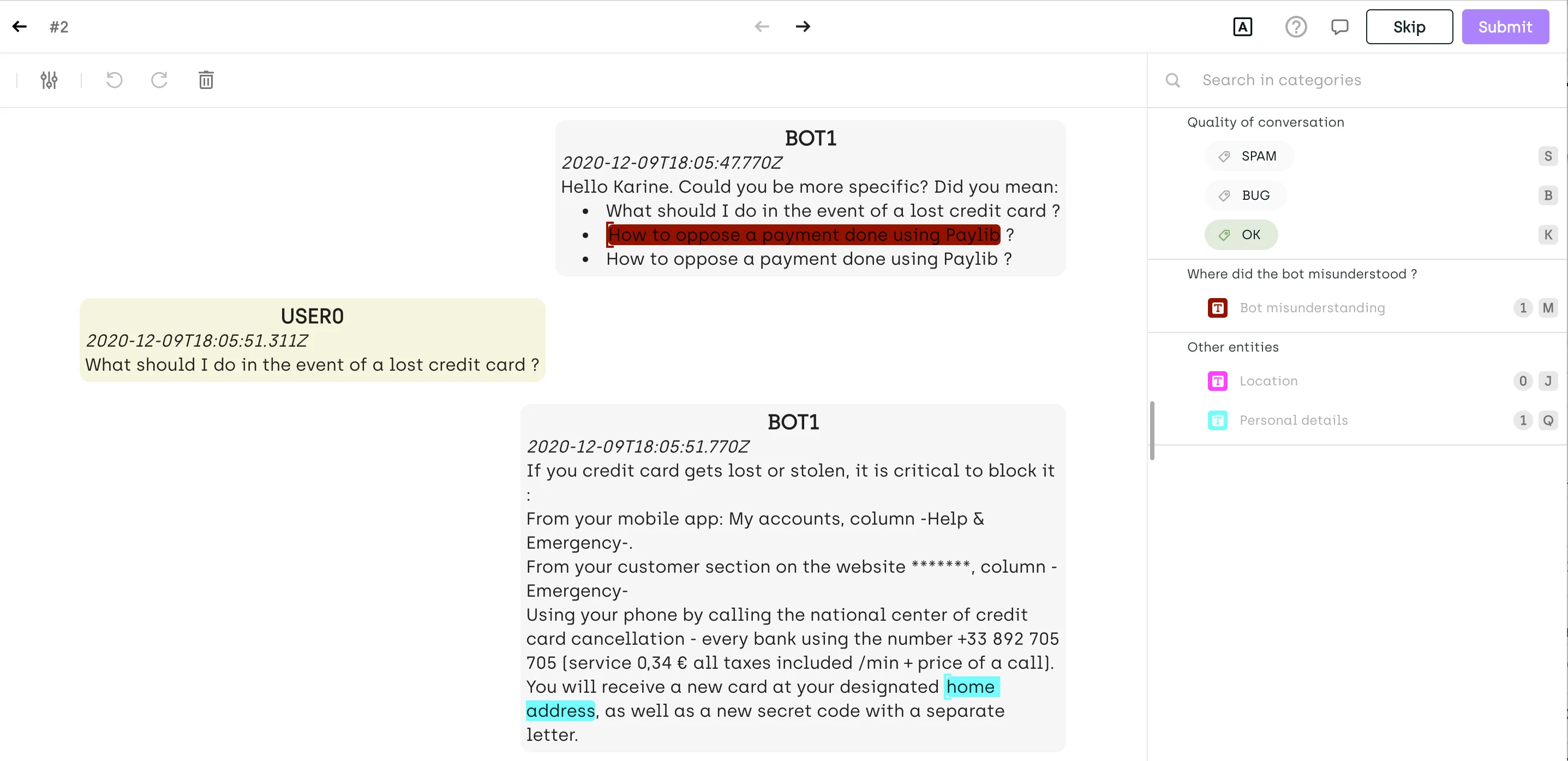
Entity Recognition in Customer Service Chatbots
Entity recognition allows chatbots to extract important information from user input, like names, addresses, or product types, enabling personalized and efficient customer support.
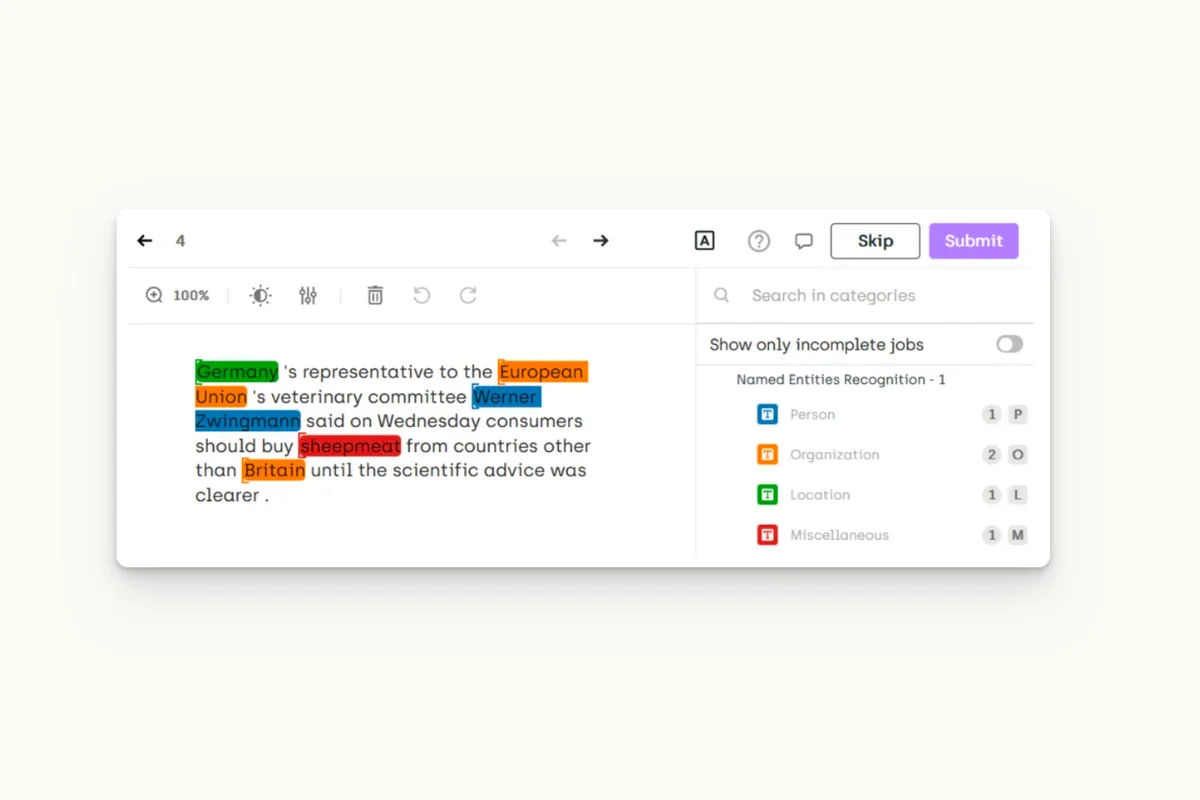
Kili Technology is used to perform Entity Recognition of a Chatbot Text
Text Classification for Social Media Analytics
By classifying social media posts into categories like sentiment or topic, businesses can better understand their audience, track brand perception, and uncover market trends.
Entity Recognition for Knowledge Graph Construction
By identifying entities and their relationships in text, machines can build knowledge graphs that represent complex real-world information, paving the way for more advanced AI applications.
Text Classification for Automated Content Moderation
Classifying text into categories like spam or inappropriate content helps maintain safe and healthy online communities by automating the moderation process.
Future Trends and Challenges in Entity Recognition and Text Classification
Zero-Shot and Few-Shot Learning in AI
As labeled data becomes more scarce, techniques like zero-shot and few-shot learning, which require little or no labeled data, will become increasingly important. As labeled data becomes more scarce, techniques like zero-shot and few-shot learning, which require little or no labeled data, will become increasingly important. In the field of Named Entity Recognition (NER), pre-annotating tasks with machine learning models like ChatGPT can greatly reduce the amount of manual labeling needed, making zero-shot and few-shot learning more accessible for NER tasks.
Multimodal Learning and Fusion Techniques in AI
Integrating text with other data modalities, like images or audio, can lead to more powerful AI systems that better understand the world.
Adversarial Examples and Robustness in AI
Developing models resistant to adversarial attacks, where inputs are deliberately manipulated to cause misclassification, is crucial for maintaining AI system security.
Ethical Considerations and Mitigating Biases in AI
Ensuring AI models are ethical and unbiased is a growing concern, requiring ongoing research and the development of new techniques to address potential issues.
Natural Language Processing and Text Classification: Wrap Up
And there you have it, folks! We've taken a deep dive into the world of entity recognition and text classification, exploring the nitty-gritty of these essential techniques for machine learning engineers in the realm of natural language processing. From best practices in data preprocessing and feature engineering to tackling imbalanced datasets and model evaluation, we've covered it all. Plus, we've touched on real-world applications and the future of the field.
But hey, AI is a fast-moving landscape, and there's always something new to learn! So, keep your eyes peeled for the latest techniques, trends, and ethical considerations to stay on top of your game and contribute to responsible AI development. By delving into the ins and outs of entity recognition and text classification and putting a strong focus on being data-centric, you'll be ready to face real-world challenges and push the boundaries of NLP.
Remember, the secret sauce is practice and never-ending learning. Go ahead and dive into new datasets, tinker with various techniques, and use your skills to create a positive impact in the world of AI. Put in the time to gather top-notch data and find the right tools for labeling - trust me, it'll be worth it. So, buckle up and enjoy the ride. Happy coding,!
Resources
Github Repositories
https://github.com/huggingface/transformers/tree/main/examples
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

