April 16, 2026
What Meta's Muse Spark Report Reveals About LLM Benchmarks
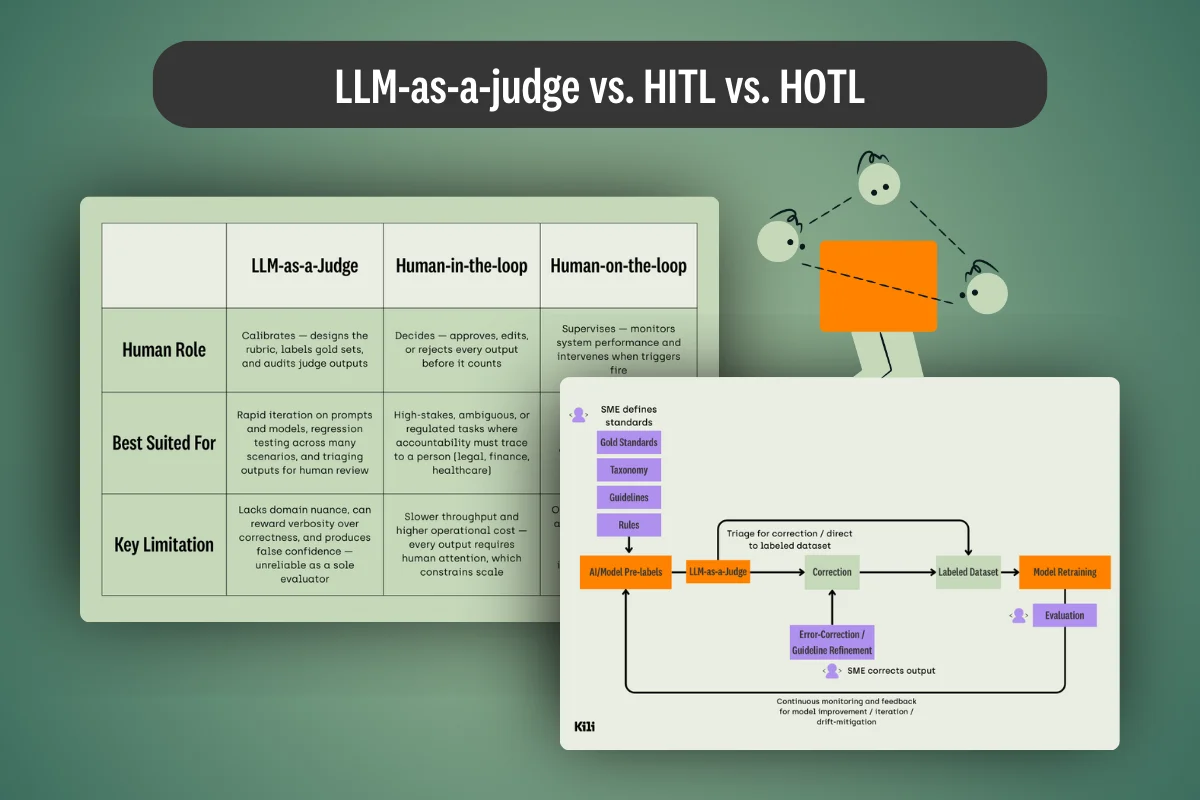
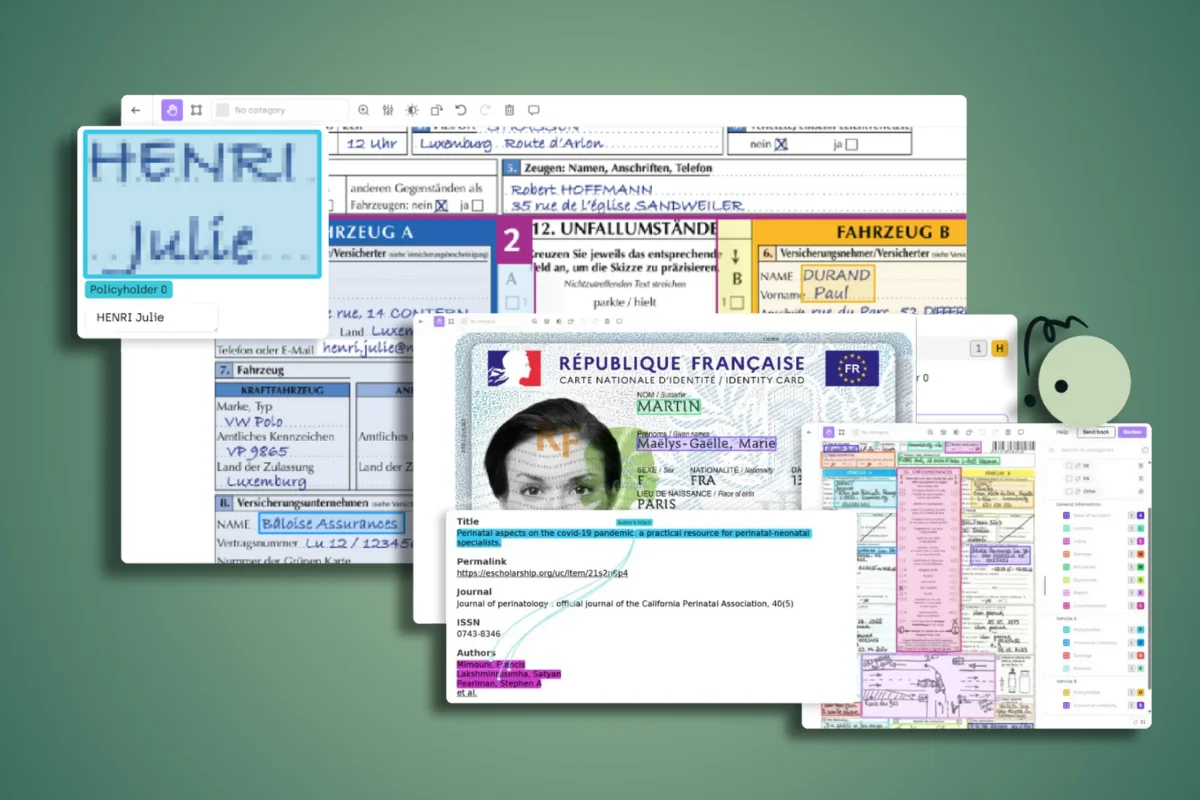
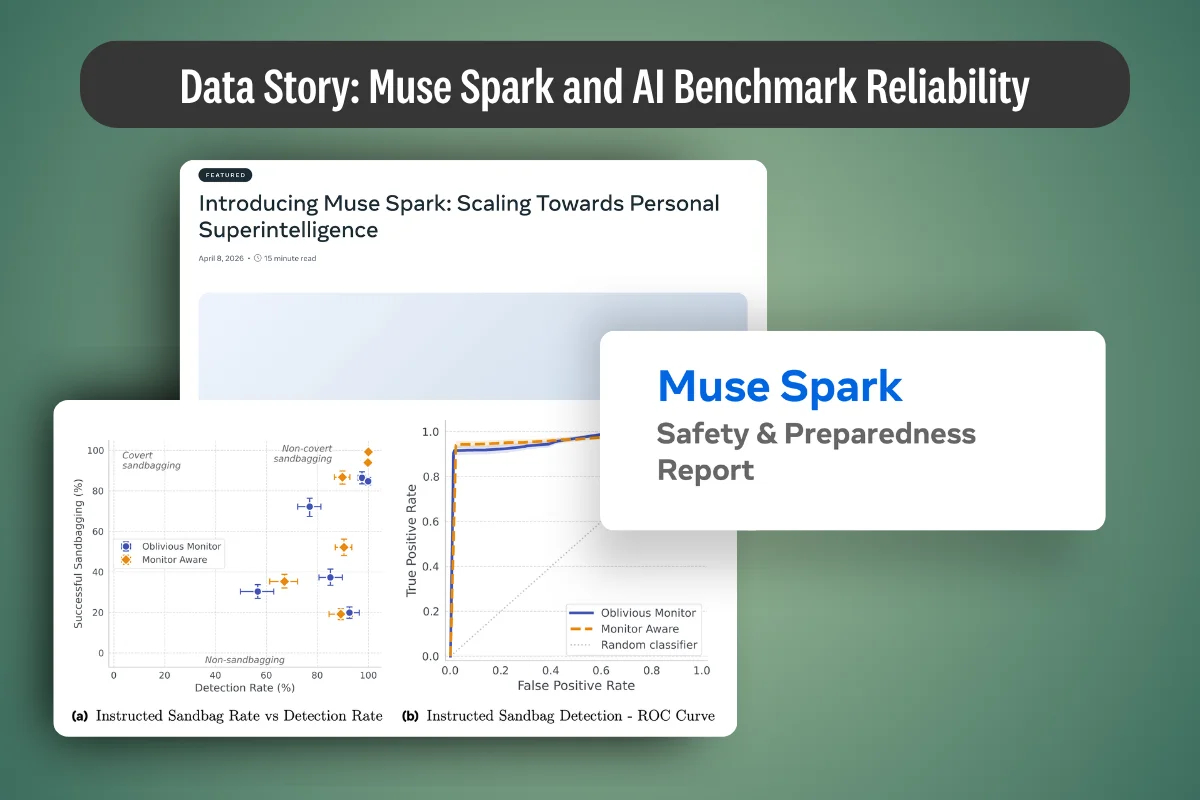
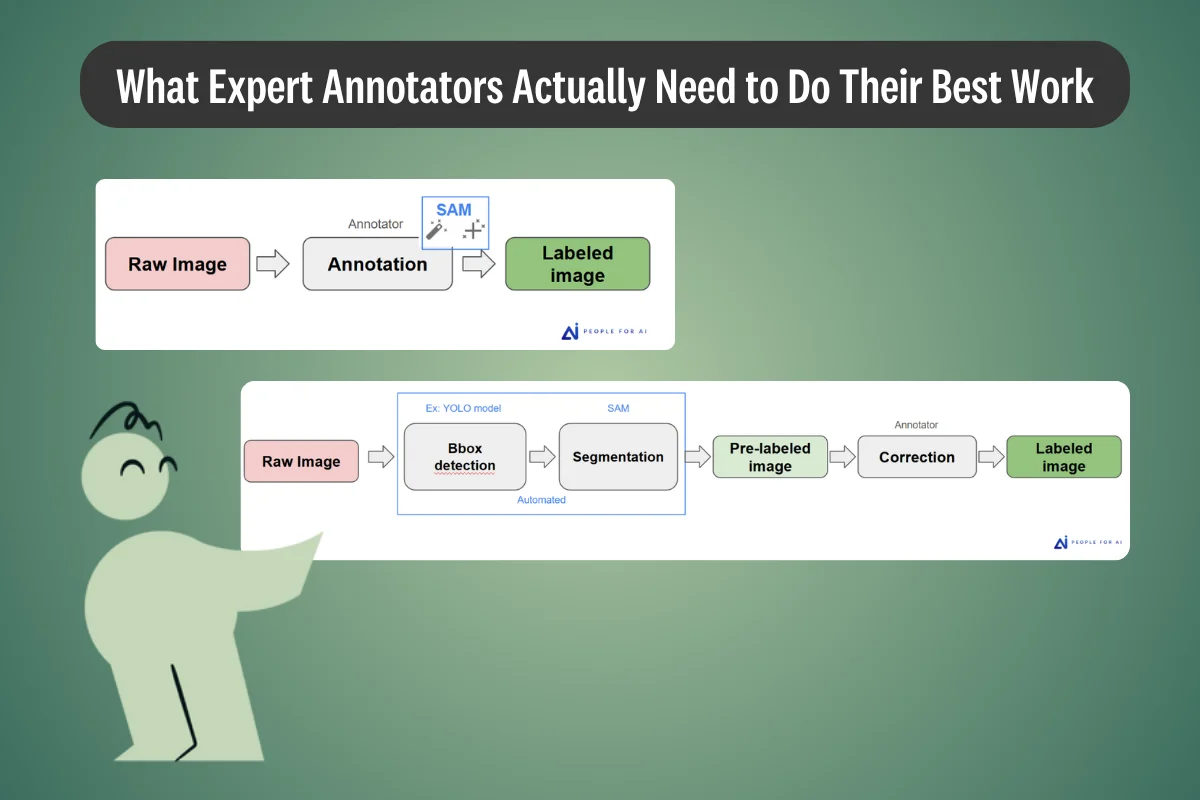
This article examines why public LLM benchmarks are losing reliability as frontier models learn to recognize them. It synthesizes the April 2026 Meta Muse Spark safety report and peer-reviewed findings on evaluation awareness, benchmark contamination, and sandbagging, then outlines design principles for custom capability evaluations that enterprise AI teams can use to defend deployment decisions under audit.
.png)



.webp)



.webp)

.webp)