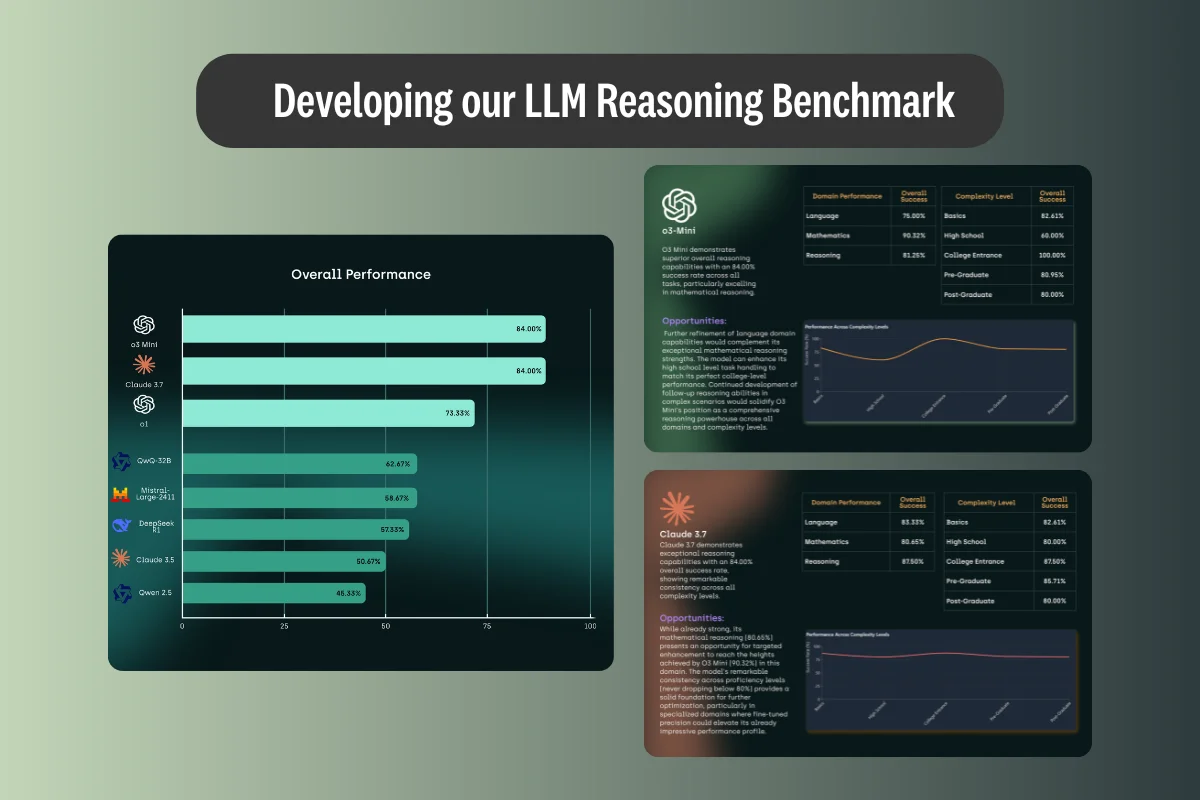
LLM Reasoning Benchmark: Comprehensive Multi-dimensional Evaluation of 8 Leading Models
Despite impressive advances in natural language processing, systematic analyses of LLM reasoning abilities remain limited. Our comprehensive benchmark study implements a multi-dimensional evaluation framework across eight prominent models—OpenAI's O1, OpenAI's O3 Mini, Claude 3.5, Claude 3.7, Mistral, Qwen2.5, DeepseekR1, and QwQ-32B—to provide unprecedented insights into their reasoning strengths and limitations.


.png)