
.png)

_logo%201.svg)


AI Summary
Introduction
Most performant named entity recognition (NER) models require lots of labeled entity examples to be trained on and perform well. However, annotation is a painful process that involves a lot of human effort and often demands domain expertise that is hard to obtain. To reduce this pain, pre-annotation can be used to accelerate the annotation process. Pre-annotation consists in using rule-based or Machine Learning models to automatically label datasets that are then reviewed by human annotators. In this way, by simply correcting and verifying the pre-annotations, labelers' work can be much simpler and faster.
Pre-annotation NER models still need task-specific labeled data to work but these models are needed as soon as possible in the annotation project when manually annotated data is scarce. When labeled data is rare, traditional fine-tuning methods do not work, and more ingenious methods are needed to squeeze as much information as possible from the few annotated examples. In recent years, few-shot learning methods have been developed. While they are clearly not as good as traditional methods trained on many examples, they can be helpful in pre-annotation since they are a good tradeoff between accuracy and the number of labeled samples.
In this post, we will, first, see why traditional methods do not work in the few-shot setting. Then, we will explore several few-shot learning methods starting with prototypical methods. Then, we will see how label semantics information can be introduced in the model and end with meta-learning.
Limitations of transfer learning
Transfer learning consists in adapting a pre-trained model that has been trained on lots of data to a specific new task. This is very common in NLP. Large language models like BERT or GPT are trained on simple tasks like mask filling that allow the model to get a good understanding of language, with little annotation effort. When adapting to a specific task, the pre-trained model is reused. The last layers of the model are changed so that the output corresponds to the specific task, while the backbone is kept and initialized with the weights of the pretrained model. Then, this model is trained on the available training data of the specific task.
Nevertheless, the fine-tuning of the model still requires hundreds or thousands of examples per class to perform well. Simple training of the model on a few labeled examples is not enough to get a good generalization. As shown in figure 1, the model overfits if it only has 1-5 examples per class.
Figure 1: Average f1-score of a NER model trained on subsamples of CoNLL according to the number of elements in the subsample
Therefore, few-shot methods need a more explicit objective that regularizes the learning and avoids overfitting. One way of doing that is to induce a bias in the method. For instance, as objective the vector of an entity must be close to the average representation of their entity class and others should be far from each other. This is the base of prototypical methods.
Prototypes
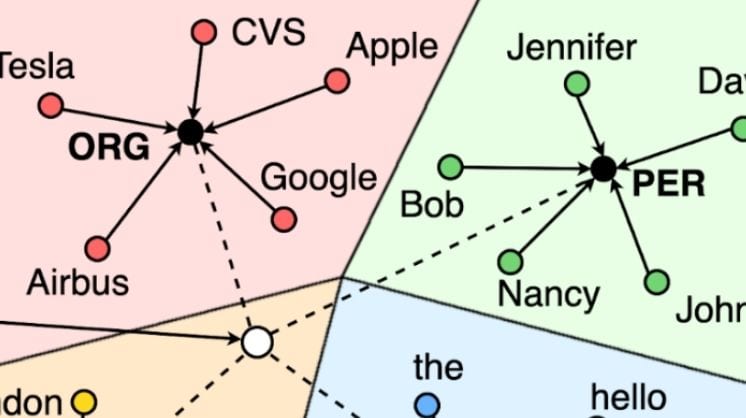
Prototypical Networks were introduced by [Snell et al.] and [Fritzler et al.] adapted the idea to NER. These networks learn a token embedding such that each class is represented by a centroid vector, which is the average representation of the labeled entities of the class, and entities that are close to one of these centroids are classified as the same entity.
Figure 2. Example of entity classification using prototype representation in a vector space (inspired by Snell et al.’s figure)
Concretely, each token token x is embedded with a pretrained language model f. Then the prototype of class ci is computed as:
for xk belonging to class ci and with K the number of such tokens
For a given token, the model outputs its confidence on it belonging to class ci by using the Euclidian distance and the softmax function as follows:
The fine-tuning of parameters is done by maximizing the log-likelihood.
Learn more!
Discover how training data can make or break your AI projects, and how to implement the Data Centric AI philosophy in your ML projects.
Take advantage of label semantics
One simple idea is to leverage the information contained in the label name semantics to guide the model towards good prototypes, i.e good representations of each class. The representation of each token is compared to the vector representation of each label name. If the two vectors are similar, the token can be classified as an entity of this label. This idea was integrated into a model by [Jie Ma et al.].
Figure 3. Model architecture leveraging label semantics (by Jie Ma et al.)
As you can see in figure 3, each token class is represented by a small span indicating the kind of class and the position of the entity. These label names and the input tokens can be encoded by a BERT encoder. Then, for each contextualized embedding of a token, a dot product is computed with each label embedding and a softmax layer is applied to have the output scores. The training is done by backpropagating a classic cross-entropy loss.
While the idea seems interesting and results promised in the paper look good, we were not able to reproduce them.
Use some rules to correct predictions
A post-processing step can be added to improve performance. This step is not always reported in papers but can have a big impact on performance. The most common method is to use a Conditional Random Field (CRF) to estimate the transition probability from one label to another. If we suppose that yt is the class of token t and x is the input sentence of the model. Then we denote p(yt|x) as the output probability vector of word t and p(yt|yt-1) the probability given by the CRF of having label yt after yt-1. Then, the class of token t is given by solving the following problem:
This can be found using the Viterbi decoder algorithm. This gave the idea of StructShot, a simple and effective few-shot learning idea for NER that compares the representation of each entity to the k nearest neighbors to get the probabilities p(yt|x) and adds this CRF to improve results.
Meta-learning: the ultimate solution?
Meta-learning refers to a series of methods whose purpose is learning to learn. Concretely, in NER, this means that models are given several small NER tasks with different classes to train on such that, when they receive a new small dataset, they can train on it and get the best possible performance. One of the most commonly used algorithms in meta-learning is Model agnostic Meta-learning (MAML for short). MAML supposes that you have several small tasks, this means that you have a dataset D that is a set of several support and query dataset couples, D={(Si, Qi)|i[1, N]}. Each couple has its own set of classes. Then, the algorithm is as follows:
Starting from a model ,
- For each iteration,
- for each batch of size B of couples (Si, Qi),
- For each couple
- , we will do n steps of gradient descent on Si and get B new models i.
- the new model parameters will be:
- for each batch of size B of couples (Si, Qi),
Figure 3. One step of MAML
MAML was adapted to NER and tested on the main benchmark for few-shot NER, which is the FewNERD dataset. As of today, the state-of-the-art method for few-shot named entity recognition on this dataset was introduced by [Ma et al.] and is called Decomposed Metal-Learning for NER. The idea of this method is to separate the NER task into two subtasks which are span prediction and entity classification. The goal of the first one is to detect the beginning, inside, and ending entity tokens and the second focuses on classifying each detected span. For each subtask, a model is trained following the MAML principle.
The problem with this method is that it is quite long and we have to keep many copies of the parameters which can be memory-heavy in training. A labeled dataset with many different entity recognition tasks like FewNERD is also needed, which is quite hard to get and also adds some bias to the model. If the new task you want to train on has a very different text from the training data, generalization won’t be very good.
Conclusion
In recent years, several few-shot learning methods have been adapted to NER with some promising results. We are still far from what humans can do and few-shot learning methods don’t generalize as well as traditional methods finetuned on many examples. Nevertheless, these methods are particularly well suited for pre-annotation because, in this setting, labeled data is scarce and reviewers can correct wrong labels.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

