
.png)


_logo%201.svg)


AI Summary
What is Named Entity Recognition?
Named Entity Recognition (NER) is a process in data science that involves identifying and labeling entities in textual data for further analysis. For instance, NER could recognize the term "Netflix" in a document and classify it as a "company." With its versatility, NER can identify various entities such as people, places, companies, and time periods in text data.
NER utilizes natural language processing (NLP) to tag entities based on predefined parameters. Entity extraction is employed to extract and tag significant entities within a document, facilitating the identification of crucial information. For example, NER can be applied to invoices to automate the identification of account IDs, shipping and billing addresses, and invoice amounts. This integration can streamline the payment process, even if the initial invoice is in paper format.
By implementing NER, businesses can enhance their document processing and payment systems, improving efficiency and accuracy. Learn more about Named Entity Recognition and how it can transform information management in your organization.
Categorization in Named Entity Recognition (NER)
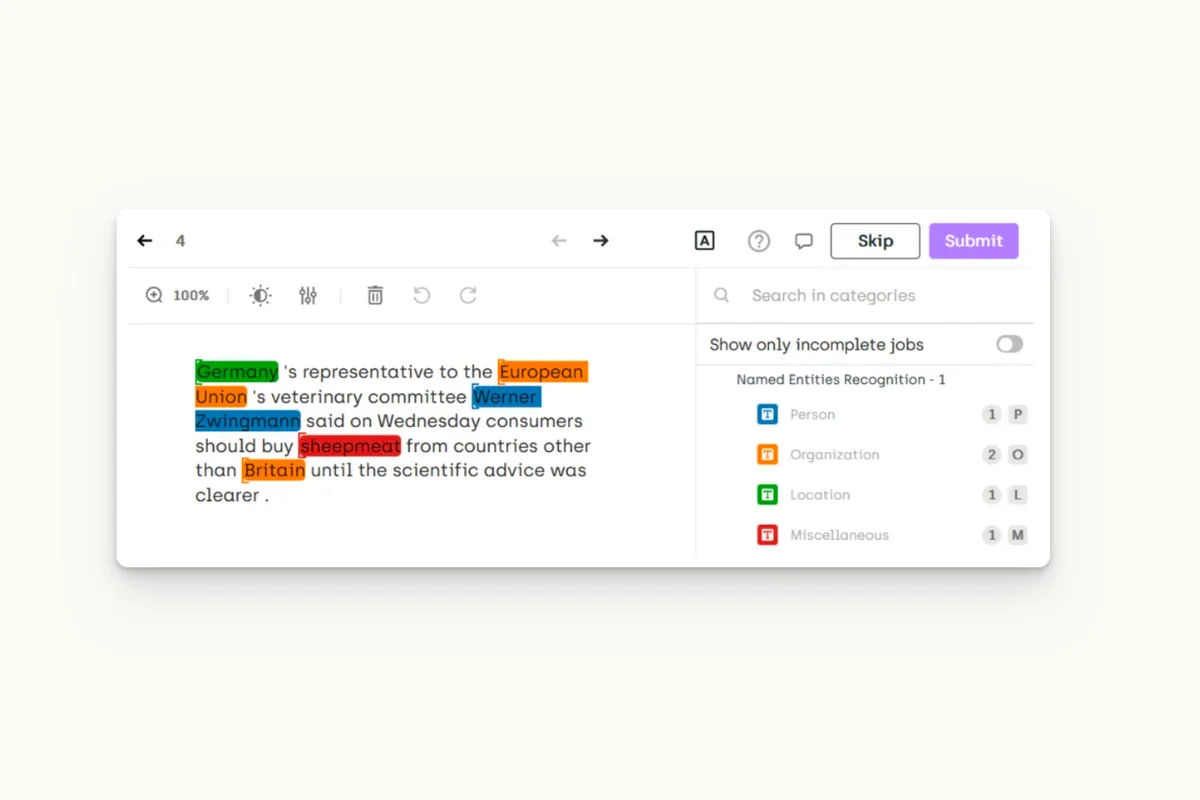
Categorization in NER is a vital process that involves classifying identified entities into specific categories or classes. This process allows for a more structured and meaningful analysis of the text, enabling various applications and extracting insights therein. Here's a detailed look at the categorization in NER:
Predefined Categories
- Organization: Entities that represent companies, institutions, or agencies, such as 'Netflix,' 'NASA,' or 'United Nations.'
- Person: Names of individuals, including fictional characters.
- Location: Geographical locations like countries, cities, mountains, or rivers.
- Time: Dates, days, months, years, or any time-related expressions.
- Monetary Values: Financial amounts, currencies, and related symbols.
Custom Categories
Depending on the specific needs and domain of application, NER can also define custom categories. For example:
- Healthcare Terms: Medical conditions, treatments, medications, etc.
- Legal Terms: Legal documents, court names,
Example of Categorization in NER
Consider the following sentence:
"Steve Jobs founded Apple in Cupertino on April 1, 1976, and the company's current CEO is Tim Cook."
When this sentence is processed using NER, the entities are identified and categorized as follows:
- Person: "Steve Jobs" and "Tim Cook" are recognized as individual names and categorized under the 'Person' category.
- Organization: "Apple" is identified as a company name and falls under the 'Organization' category.
- Location: "Cupertino" is recognized as a geographical location and is categorized under the 'Location' category.
- Time: "April 1, 1976" is identified as a date and is placed under the 'Time' category.
The categorization of these entities allows for a structured understanding of the sentence. It enables various applications such as:
- Search Optimization: If this text is part of a larger document, search engines can use these categorized entities to provide more relevant search results.
- Data Analysis: Businesses can analyze this categorized information to gain insights into historical events, key individuals, and locations related to the company.
- Automation: Customer support systems can use this categorized information to automatically respond to queries about the company's history, founders, or current leadership.
Methods of Named Entity Recognition (NER) and examples
Named Entity Recognition (NER) employs various methods to identify and categorize named entities within a text. These methods range from simple rule-based approaches to sophisticated deep learning techniques. Here's a detailed look at the different methods:
1. Dictionary-based
This method utilizes a predefined dictionary containing a list of entities for basic string-matching. It's one of the earliest and simplest techniques.
- Pros: Easy to implement and understand.
- Cons: Limited to the entities in the dictionary, requires constant updates, and may miss variations or misspellings.
- Use Case: Suitable for domains with well-defined and stable terminologies, such as medical or legal texts.
2. Rule-based
Rule-based NER employs predefined rules for information extraction, including pattern-based and context-based rules.
- Pattern-based: Utilizes regular expressions and patterns to identify entities.
- Context-based: Considers the surrounding words and context to identify entities.
- Pros: More flexible than dictionary-based, can capture variations.
- Cons: Requires expert knowledge to define rules, may become complex.
- Use Case: Effective in extracting specific formats like dates, phone numbers, or email addresses.
3. Machine Learning-based
Machine Learning-based NER uses statistical models to recognize entities, even with small spelling variations. For example: A retail company wants to analyze customer reviews to extract product names and prices. They decide to use a machine learning-based approach, specifically employing a Support Vector Machines (SVM) algorithm.
By training the system on labeled text data, containing examples of product names and prices, and considering features like word shape, part-of-speech tags, and surrounding words, the model is tailored to recognize these specific entities.
Once trained on label data, the model can be applied to new, unseen customer reviews, successfully recognizing and categorizing product names and prices, providing valuable insights for the company's marketing and sales strategies.
- Algorithms: Common algorithms include Decision Trees, Random Forest, SVM, etc.
- Feature Engineering: Utilizes features like word shape, part-of-speech tags, and surrounding words.
- Pros: Adaptable to different domains, can learn from examples.
- Cons: Requires labeled training data, may struggle with rare entities.
- Use Case: Suitable for domains with available training data and diverse entity types.
4. Deep Learning-based
Deep Learning-based NER understands the semantic and syntactic relationships between words, providing more accurate recognition. A multinational news agency aims to identify and categorize entities such as people, locations, and organizations in news articles across multiple languages. They opt for a deep learning-based approach, utilizing a pre-trained BERT model.
By fine-tuning the model on a training dataset containing labeled entities and leveraging BERT's word embeddings that capture semantic meanings and relationships between words, the system gains the ability to accurately recognize entities in news articles.
The deep learning model's understanding of complex relationships and context enables it to function across various languages, enhancing the agency's global news analysis capabilities.
- Models: Utilizes models like RNN, LSTM, BERT, etc.
- Word Embeddings: Represents words as vectors, capturing semantic meanings.
- Pros: Highly accurate, can capture complex relationships.
- Cons: Computationally intensive, requires large training datasets.
- Use Case: Ideal for complex and large-scale applications, such as social media analysis or multilingual processing.
5. Hybrid Methods
Some NER systems combine different methods to leverage their strengths and mitigate weaknesses. For example, a healthcare provider faces the challenge of extracting diverse information such as patient details, medical conditions, treatments, and medications from medical records. They choose a hybrid approach that combines rule-based methods with deep learning. The rule-based component, utilizing regular expressions and patterns, identifies specific formats like dates and patient IDs. Simultaneously, a deep learning component using an LSTM model recognizes more complex medical terms by learning from the context and relationships between words.
By integrating the results from both components, the hybrid system accurately extracts and categorizes various types of information from medical records. This combination of hybrid systems leverages the strengths of both rule-based and deep learning methods, providing a comprehensive solution for the healthcare provider's information extraction needs.
- Combination: May combine rule-based with machine learning or deep learning.
- Pros: Enhanced accuracy, flexibility, and robustness.
- Cons: Complexity in integration and tuning.
- Use Case: Suitable for applications requiring high precision and adaptability.
What is Text Classification?
Text classification, distinct from Named Entity Recognition (NER), a machine learning algorithm that serves the purpose of categorizing entire texts or documents into predefined classes or groups. Unlike NER, which focuses on identifying specific entities within the text, text classification takes a holistic view of the content to make judgments about its overall characteristics. This includes determining the sentiment, language, or topic of the text, and it's applied in various domains such as customer feedback analysis, content recommendation, and automated support systems.
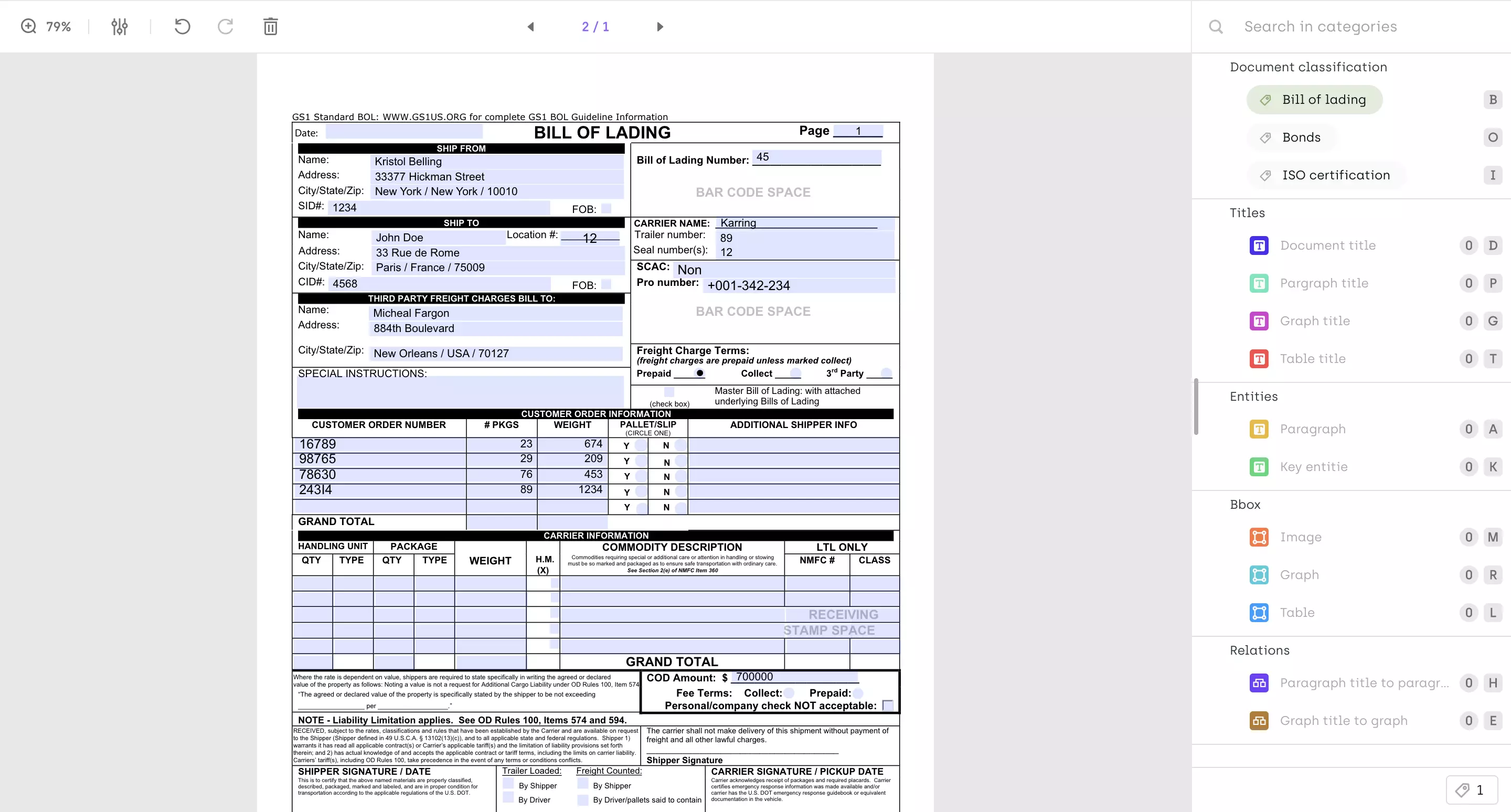
Sentiment Analysis
Sentiment analysis goes beyond merely identifying whether a text is positive or negative. It involves a nuanced understanding of the emotions and opinions expressed within the text. By analyzing the language, tone, and context, sentiment analysis can categorize sentiments into more specific classes, such as happy, angry, or neutral. This is widely used in social media monitoring, brand reputation management, and customer experience enhancement.
Applications
- Customer Feedback Analysis: Businesses can analyze customer reviews to gauge satisfaction levels and identify areas for improvement.
- Social Media Monitoring: Brands can track social media posts to understand public sentiment towards their products or services.
- Market Research: By analyzing sentiments in news articles, forums, and social media, companies can gain insights into market trends and consumer preferences.
Language Classification
Language classification is not just about detecting the language of a text. It plays a crucial role in global businesses by automatically routing support queries to the appropriate language-speaking representatives or offering real-time translation services. It can also be used in content localization, ensuring that users receive information in their preferred language, enhancing accessibility and user engagement.
Applications
- Customer Support Routing: Multinational companies can automatically route customer queries to the appropriate language-speaking support team.
- Content Localization: E-commerce platforms can detect the user's language preference and display content in that language, enhancing user experience.
- Translation Services: Translation tools like Google Translate use language classification to detect the source language before translating it into the target language.
Topic Classification
Topic classification extends beyond identifying the nature of a support query. It involves the automatic categorization of texts into predefined topics or themes. By analyzing keywords, phrases, and context, topic classification can determine whether a text relates to finance, technology, healthcare, or any other subject. This facilitates content organization, recommendation, and targeted marketing, in addition to routing support queries to the right department.
Applications
- Content Recommendation: Streaming services like Netflix or Spotify can classify content into genres or topics to provide personalized recommendations.
- Automated Support Systems: Businesses can classify customer support queries by topic (e.g., billing, technical support) to route them to the appropriate department.
- Academic Research: Libraries and research institutions can classify research papers and articles into specific fields or subjects, facilitating easier search and discovery.
Learn more!
Discover how training data can make or break your AI projects, and how to implement the Data Centric AI philosophy in your ML projects.
How does NER and Text Classification work together in Natural Language Processing (NLP)?
The synergy between NER and Text Classification is being leveraged across various industries, from finance and e-commerce to telecommunications, hospitality, human resources, and healthcare. By combining the detailed extraction capabilities of NER with the broader categorization functions of text classification, organizations can achieve more nuanced insights, personalized interactions with internal data, and efficient processes.
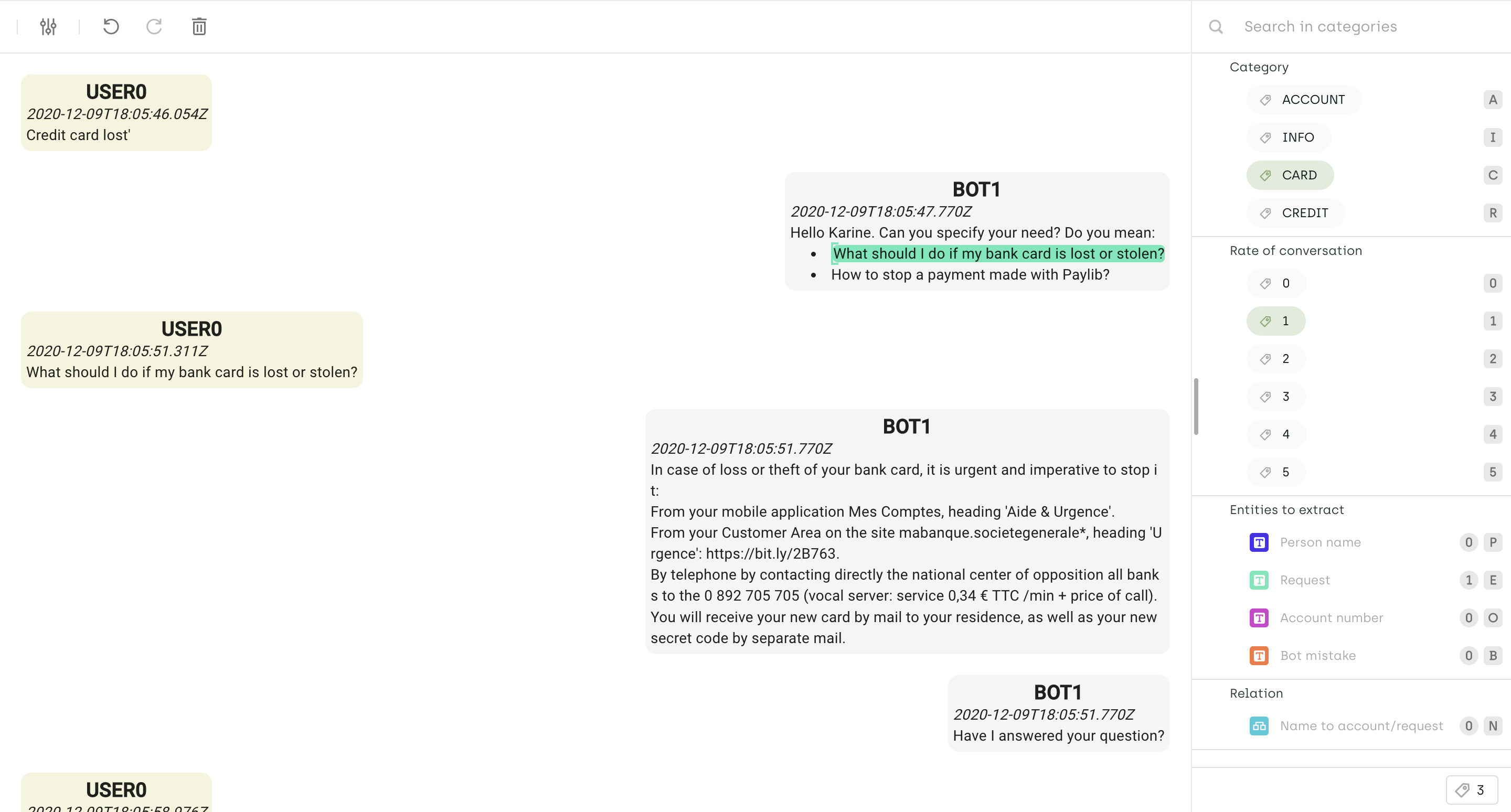
Enhancing Contextual Understanding in Financial Analysis
In the financial analysis industry, Named Entity Recognition (NER) and Text Classification work together to provide a comprehensive understanding of financial reports. NER identifies specific entities such as companies, stock symbols, and dates, while Text Classification categorizes the reports into types like quarterly earnings, mergers, or market analysis. Together, they enable financial analysts to quickly access specific information and understand the context of reports, aiding in investment decisions. This synergy enhances the efficiency of quantitative data-driven decision-making in the financial sector.
Improving Content Personalization and Recommendation in E-Commerce
E-commerce platforms leverage the combination of NER and Text Classification to enhance content personalization and recommendation. NER recognizes specific brands or products that a customer frequently purchases, while Text Classification identifies broader shopping categories like electronics, fashion, or groceries. By aligning both specific preferences and general shopping habits, e-commerce platforms can provide personalized recommendations, improving customer engagement and boosting sales.
Automating Customer Support in Telecommunications
In the telecommunications industry, automating customer support is achieved through the integration of NER and the Text Classification system. NER extracts specific details like account numbers, device models, or error codes from customer queries, while Text Classification determines if the query is about billing, technical issues, or new services. Telecom companies can automatically route customer queries to the right support agents, reducing wait times and improving customer satisfaction. This collaboration enhances the overall customer experience and operational efficiency.
Enhancing Sentiment Analysis in Hospitality and Tourism
The hospitality and tourism industry utilizes NER and Text Classification to enhance sentiment analysis. NER identifies specific hotels, destinations, or amenities mentioned in customer reviews, while the Text Classification model analyzes the overall sentiment of the review, such as satisfaction or dissatisfaction. Together, they enable hotel chains and travel agencies to understand customer sentiments towards specific aspects of their service, allowing for targeted improvements. This nuanced understanding of customer feedback is vital for maintaining and enhancing service quality in a highly competitive industry.
Facilitating Information Retrieval and Search in Healthcare
Healthcare providers employ NER and Text Classification tools to facilitate information retrieval and search within medical records. NER extracts specific medical terms, patient IDs, or medication names, while Text Classification categorizes documents into types like diagnoses, treatments, or lab results. The combination of these techniques allows healthcare professionals to quickly retrieve relevant patient information, enhancing diagnosis accuracy and treatment efficiency. This integration is crucial in a field where timely access to accurate information can have a direct impact on patient outcomes.
NER, Text Classification, and LLMs
Named entity recognition (NER) and text classification are vital natural language processing (NLP) tasks that have greatly benefitted from the development of large language models (LLMs).
LLMs are a type of artificial intelligence (AI) model trained on extensive datasets of text and code. This enables them to learn statistical relationships between words and phrases, facilitating various NLP tasks, including NER and text classification.
In the past, NER and text classification models were generally trained on small labeled datasets, limiting their generalization capabilities and leaving room for errors. However, LLMs can be trained on significantly larger datasets, enabling them to learn intricate patterns and make highly accurate predictions.
For instance, the renowned BERT model, an LLM, was trained on a dataset of 3.3 billion words. Consequently, BERT can recognize a broader range of named entities compared to traditional NER models.
Moreover, LLMs have unlocked text classification tasks that were previously challenging or impossible. The GPT-3 model, for example, can classify text into various categories such as news articles, product reviews, and customer support queries.
The utilization of LLMs has revolutionized NER and text classification, empowering NLP tasks with enriched precision and efficiency.
Conclusion
Named Entity Recognition (NER) and Text Classification are powerful natural language processing (NLP) techniques that have unlocked immense value in various industries. The combination of both tasks provides organizations with more nuanced insights, personalized interactions, and efficient processes.
Moreover, the development of large language models (LLMs) has dramatically improved NER and text classification. LLMs have enabled models to learn intricate patterns from vast datasets, leading to enhanced accuracy and generalization capabilities.
NER and Text Classification, when paired with the power of LLMs, are essential for driving innovation in all areas of business. Leveraging this powerful combination of AI tools organizations will be able to derive greater insights and create more meaningful interactions.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

