
.png)
AI Summary
The DBRX model is a groundbreaking advancement in large language models (LLMs). Developed by Databricks and Mosaic ML, DBRX is a transformer-based, decoder-only LLM using next-token prediction. It features a mixture-of-experts (MoE) architecture with 132 billion total parameters, making it highly efficient and versatile.
The large language model trained on 12 trillion tokens of text and code data using tools like Apache Spark™, Databricks notebooks, and Unity Catalog, DBRX's MoE architecture significantly outperforms similar models, with 16 experts selecting 4 for each task. Key features include rotary position encodings (RoPE), gated linear units (GLU), and grouped query attention (GQA).
The training data was carefully curated with Databricks' tools, enhancing its quality and effectiveness. DBRX excels in both text and code generation, offering state-of-the-art efficiency and inference speeds up to twice as fast as comparable models.
Hosted on Mosaic AI Model Serving, DBRX generates text at speeds up to 150 tokens per second per user, making it a powerful tool for enterprises and the open community.
This article will explore DBRX's training process, focusing on data and evaluation methods, and extract insights on LLM data quality and evaluation from Databricks' and Mosaic's work.
Training Data for DBRX
Screenshot from Introducing DBRX Open LLM - Data Engineering San Diego (May 2024) video.

High-quality training data is a cornerstone of effective machine learning models, especially for large language models (LLMs) like DBRX. The quality, diversity, and volume of training data directly impact a model's performance and accuracy. DBRX's training data has been carefully curated and processed to ensure optimal model performance.
Sources of Training Data for DBRX
DBRX was pre-trained on publicly available online data sources. Importantly, no customer data was used in the training process. The model was trained on a staggering 12 trillion tokens of curated text and code data, allowing it to develop a deep and nuanced understanding of various language patterns and structures. This data set was processed to a maximum context length of 32,000 tokens, which is essential for handling extensive and complex inputs effectively.
The choice of data sources is critical. Publicly available online data was selected to ensure a broad and representative sample of language use. This approach helps the model generalize better across different domains and applications. Moreover, the data was meticulously curated to enhance its quality. This curation process involved cleaning, filtering, and augmenting the data to remove noise and irrelevant information, resulting in a higher signal-to-noise ratio.
Align your models with precision
We ensure your large language models (LLMs) are aligned with your specific needs through our comprehensive alignment solutions. We provide expert data annotation and curation, a global workforce skilled in handling diverse and complex datasets and advanced project management tools to streamline alignment processes.
Start a POC
Importance of High-Quality Training Data in Machine Learning
The quality of training data significantly influences a model's ability to learn and make accurate predictions. For DBRX, the training data is estimated to be at least 30% better token-for-token than the data used to pretrain the MPT family of models. This improvement is partly due to the careful curation and the inclusion of diverse and representative samples from a wide range of sources.
High-quality data contributes to several key aspects of model performance:
- Accuracy: Well-curated data ensures that the model learns from relevant and correct information, leading to more accurate predictions.
- Generalization: Diverse training data enables the model to generalize better to new and unseen data, improving its versatility and applicability across different tasks.
- Robustness: High-quality data helps the model become more robust, reducing its susceptibility to errors and biases that can arise from noisy or unrepresentative data.
Impact on Model Performance and Accuracy
Screenshot from Introducing DBRX Open LLM - Data Engineering San Diego (May 2024) video.

The impact of high-quality training data on DBRX's performance is evident from its results on various benchmarks. For instance, improving pre-training data alone has led to significant improvements in model quality. DBRX, with its superior training data, achieves higher scores on performance metrics compared to models trained on less curated data. This enhancement is reflected in its Gauntlet scores, where DBRX Dense-A with 1 trillion tokens of curated data scored 39.0%, outperforming the MPT-7B model, which scored 30.9%.
The combination of a large volume of high-quality data and sophisticated data processing techniques ensures that DBRX not only performs well on standard benchmarks but also excels in specific tasks such as code generation and language understanding. This meticulous attention to data quality and preprocessing underscores the importance of training data in developing state-of-the-art machine learning models.
In summary, the sources and quality of training data play a pivotal role in the success of the DBRX model. By leveraging publicly available online data and employing rigorous data curation processes, Databricks has ensured that DBRX is equipped with the high-quality data necessary to achieve superior performance and accuracy in a wide range of applications.
Training Process of DBRX
DBRX's training was based on next-token prediction, a widely used technique in language modeling. Next-token prediction is a fundamental technique in language modeling where the model is trained to predict the next word (or token) in a given sequence of text. Here’s how it works:
- Input Sequence: The model receives a sequence of tokens (words, subwords, characters, etc.).
- Prediction: It predicts the next token in the sequence.
- Training: The model is trained using a large corpus of text. It learns to predict the next token based on the context provided by the previous tokens in the sequence.
This technique allows the model to learn the patterns, structures, and dependencies in the language, making it capable of generating coherent and contextually appropriate text.
The model employed rotary position encodings (RoPE), gated linear units (GLU), and grouped query attention (GQA), all chosen based on exhaustive evaluation and scaling experiments.
RoPE explained
Rotary Position Encodings (RoPE) are a technique used in transformer models to encode positional information directly into the self-attention mechanism. This allows the model to understand the order and relative positions of tokens within a sequence.
This method provides several advantages:
- Flexibility: RoPE can handle sequences of varying lengths without requiring changes to the model architecture.
- Efficiency: It decays inter-token dependency with increasing relative distances, making it suitable for long-context tasks.
- Implementation: RoPE rotates the query and key vectors based on their positions in the sequence, which helps maintain positional relationships effectively.
What is GLU?
Gated Linear Units (GLU) are a type of neural network unit that includes a gating mechanism to control the flow of information. GLUs work as follows:
- Linear Transformation: Two separate linear transformations are applied to the input.
- Gating Mechanism: One transformation generates the gate values, and the other transformation generates the candidate values.
- Element-wise Multiplication: The gate values are used to modulate the candidate values through element-wise multiplication.
This gating mechanism helps the model to learn which information to retain and which to discard, improving the model’s ability to capture complex patterns and dependencies.
GQA in brief
Grouped Query Attention (GQA) is an advanced concept in artificial intelligence, particularly relevant in attention mechanisms used in models like transformers. In NLP tasks like machine translation and text summarization, GQA helps models to allocate attention resources effectively, improving the accuracy and contextual understanding of the input queries. GQA modifies the traditional attention mechanism to reduce the computational burden while maintaining performance.
Curriculum learning
The training process also involved the use of curriculum learning. Curriculum learning is a training strategy in machine learning and artificial intelligence that mimics the way humans learn by gradually increasing the complexity of the tasks or data presented to the model. The main idea is to start with simpler tasks or data and progressively introduce more complex ones. This approach helps the model to build a solid foundation and improve its performance more effectively.
Key Concepts of Curriculum Learning
- Starting Simple:
- The training begins with simpler tasks or data that are easier for the model to learn. These tasks typically involve fewer features, lower noise, or more straightforward patterns.
- Gradual Increase in Complexity:
- As training progresses, the complexity of the tasks or data is gradually increased. This can involve introducing more features, increasing the noise, or presenting more complex patterns.
- Improved Learning Efficiency:
- By starting with simple tasks, the model can quickly learn basic patterns and relationships. Gradually increasing complexity allows the model to build on this foundation and learn more intricate patterns without becoming overwhelmed.
- Better Generalization:
- Curriculum learning often leads to better generalization, meaning the model can perform well on new, unseen data. This is because the model learns to handle varying levels of complexity in the training process.
Implementation of Curriculum Learning
- Defining a Curriculum:
- The curriculum is a predefined sequence of training tasks or data. It is designed to gradually increase in complexity. This sequence can be determined based on domain knowledge, data analysis, or automated methods.
- Adjusting Data Mix:
- During training, the mix of data or tasks presented to the model is adjusted according to the curriculum. Initially, the model might only see the simplest examples, and more complex examples are introduced over time.
- Measuring Model Performance:
- The model's performance is monitored continuously. If the model struggles with the current complexity, the curriculum can be adjusted to provide more intermediate steps or additional simpler examples.
Evaluating the DBRX Model
To ensure the high quality and performance of the DBRX model, Databricks used a comprehensive evaluation process involving two major sets of benchmarks: the Hugging Face Open LLM Leaderboard and the Databricks LLM Gauntlet. Additionally, the DBRX model was found to perform well in AI2's Wild Bench.
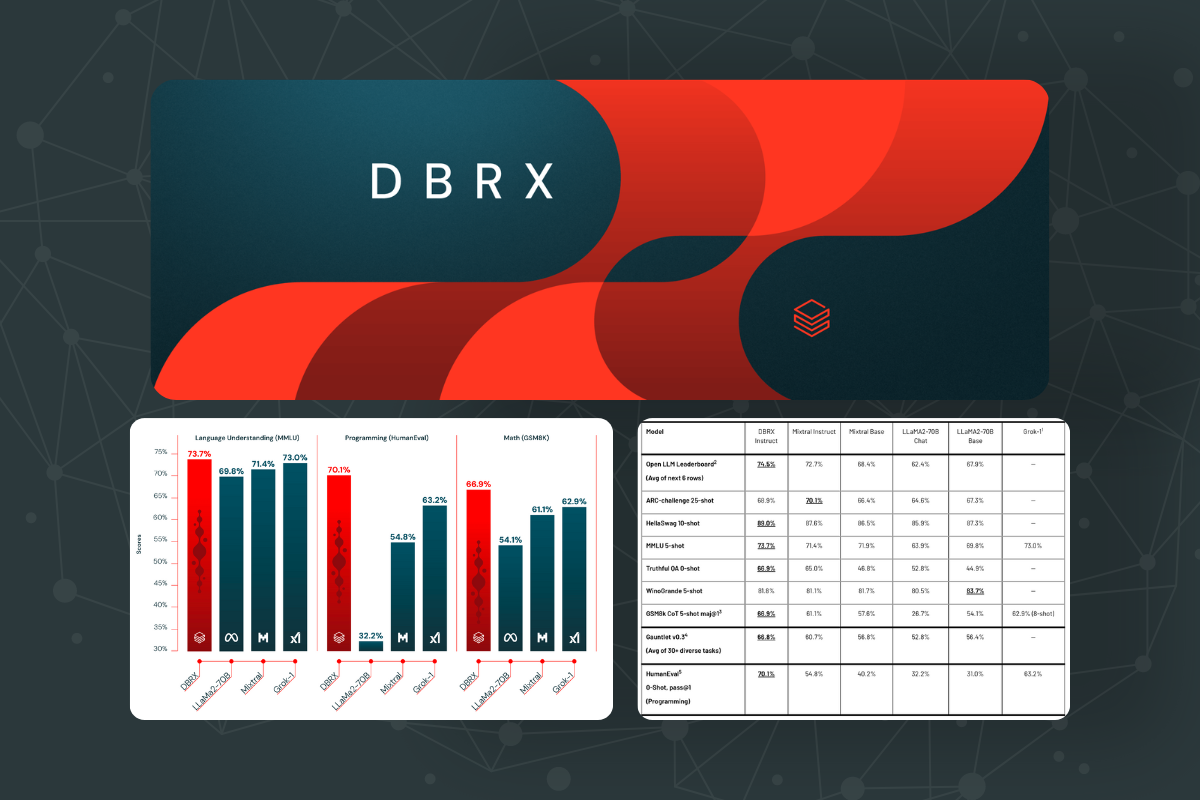
Hugging Face Open LLM Leaderboard
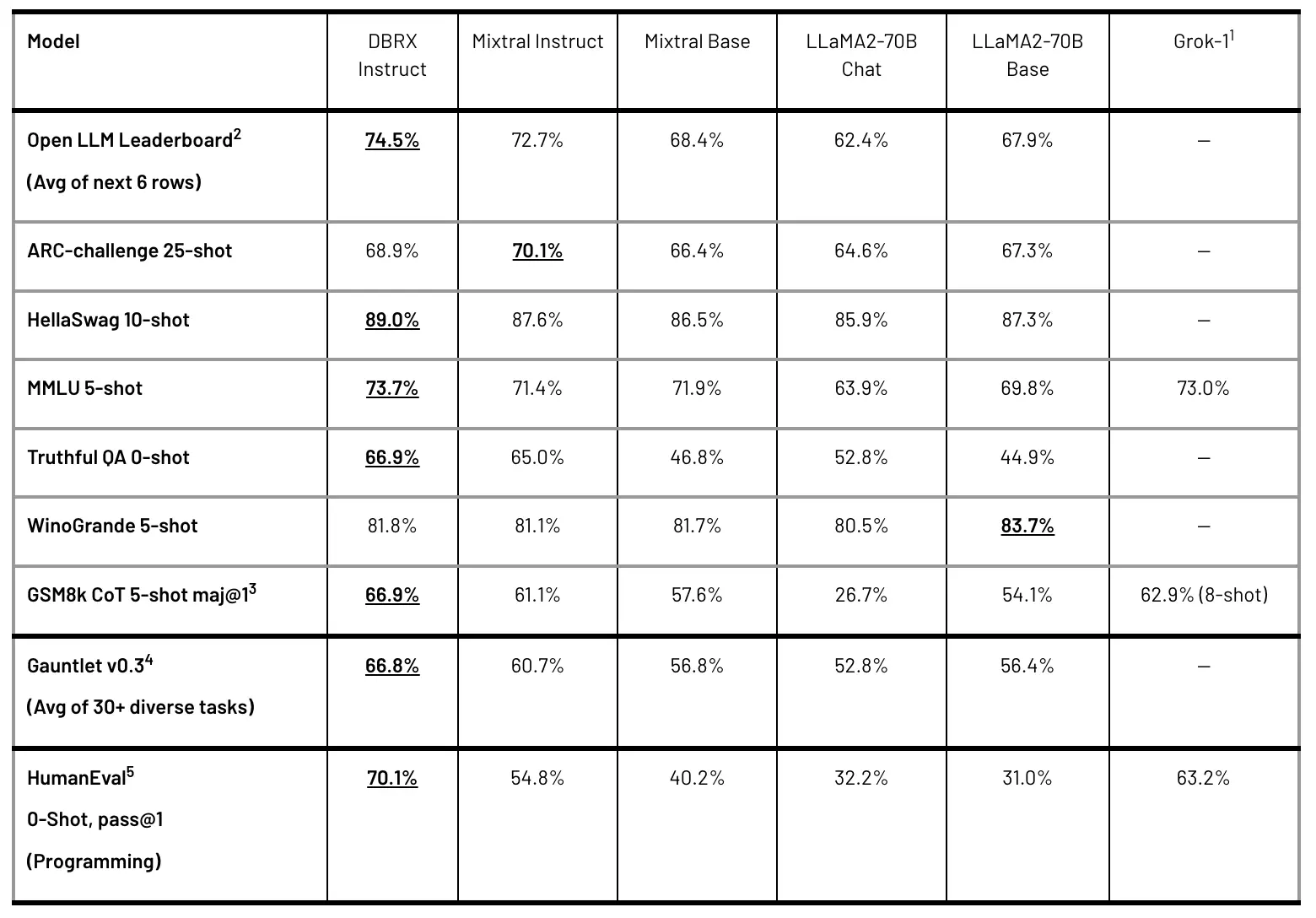
The Hugging Face Open LLM Leaderboard is a composite benchmark designed to evaluate the performance of open-source models across a range of tasks. For the evaluation of DBRX, the following benchmarks were included:
- ARC-Challenge: Assesses the model's ability to answer complex reasoning questions.
- HellaSwag: Evaluates commonsense reasoning by having the model choose the most plausible continuation of a sentence.
- MMLU (Massive Multitask Language Understanding): Tests the model's knowledge across multiple subjects.
- TruthfulQA: Measures the model's capability to generate truthful responses.
- WinoGrande: Focuses on the model's ability to resolve ambiguous pronouns.
- GSM8k: Tests mathematical problem-solving skills.
These diverse benchmarks ensure that DBRX's performance is robust across different types of tasks, highlighting its versatility and comprehensive understanding.
Databricks LLM Gauntlet
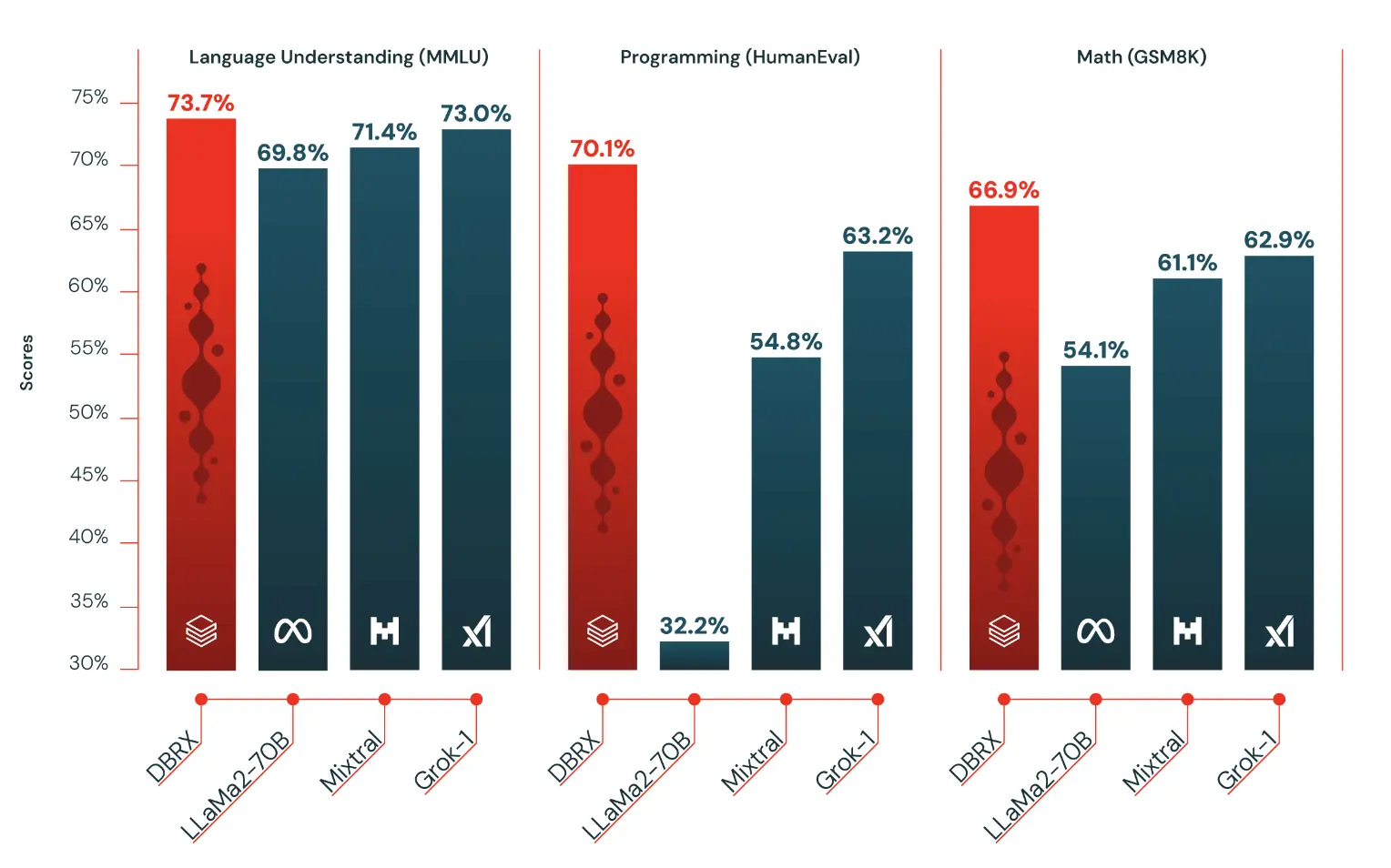
The Databricks LLM Gauntlet is an open-source benchmark developed by Databricks as part of the LLM Foundry. This benchmark suite combines 30 open-source benchmarks that span six key categories:
- World Knowledge: Evaluates the model's ability to recall facts and general knowledge.
- Language Understanding: Tests the model's comprehension and processing of language.
- Reading Comprehension: Assesses the model's ability to understand and interpret text.
- Commonsense Reasoning: Measures the model's practical reasoning skills.
- Symbolic Problem Solving: Evaluates the model's logical and mathematical problem-solving abilities.
- Programming: Tests the model's coding and software development skills.
By incorporating these comprehensive benchmarks, Databricks ensured that DBRX not only excels in specific tasks but also demonstrates strong general-purpose capabilities.
Real World Evaluation: AI2 Wildbench
Screenshot from Introducing DBRX Open LLM - Data Engineering San Diego (May 2024) video.

AI2's WildBench is a benchmark specifically designed to evaluate LLMs on challenging tasks presented by real users. This platform assesses models on a broad spectrum of natural language processing (NLP) tasks, including:
- Question Answering: Tests the model's ability to answer questions accurately.
- Text Classification: Evaluates the model's capability to categorize text correctly.
- Named Entity Recognition: Measures the model's ability to identify and classify entities within text.
- Coreference Resolution: This test measures the model's ability to determine which words refer to the same entities in a text.
WildBench provides a standardized evaluation framework, allowing researchers to compare different models' performance and identify areas for improvement. DBRX's performance on WildBench further validates its robustness and adaptability to real-world applications.
Evaluate your models with confidence
Effective evaluation is essential to ensure that your large language models (LLMs) perform at their best. Kili Technology offers comprehensive evaluation solutions to identify and rectify model weaknesses. We provide detailed performance analysis and custom reports, access to a global network of experts for thorough evaluation, project management capabilities to handle large-scale evaluations efficiently.

Start a POC
Conclusion: Insights from DBRX's Training and Evaluation
The creation of DBRX shows how important it is to have top-notch training data for large language models. DBRX is based on 12 trillion carefully chosen text and code tokens, proving that refining data can really improve a model. They've used advanced techniques like rotary position encodings, gated linear units, grouped query attention, and a mixture-of-experts architecture to make processing faster and improve accuracy and output quality.
DBRX has been put through tough benchmarks, like the Hugging Face Open LLM Leaderboard and the Databricks LLM Gauntlet, proving it's great at a wide range of tasks. Its comprehensive testing framework ensures it can handle real-world challenges, showing off its impressive flexibility and performance in areas like world knowledge, commonsense reasoning, language understanding, and programming.
Take the Next Step: Explore Advanced AI Solutions with Kili Technology
As we advance with AI, the lessons learned from training and evaluating models like DBRX are valuable. Whether you want to evaluate DBRX for leveraging or fine-tune it straight away, Kili Technology has you covered.
- Get Custom Reports: Dive deeper into DBRX and other models with Kili’s custom reports. Get to know model behaviors, strengths, and weaknesses.
- Build and Optimize Your Models: Use Kili Technology’s expertise, tools, and workforce to build, fine-tune and deploy models like DBRX. From scratch or on top of an existing model, Kili is with you every step of the way.
Start with Kili Technology now and build LLMs that are strong and tailored to your own AI systems.

_logo%201.svg)


.webp)

