
.png)


_logo%201.svg)


AI Summary
By the end of this article, you'll be aware of all the must-consider criteria for a data labeling solution.
In a rush? We've got you. Refer to the table below and find an abstract!
Learn More
Download our free excel template on how to choose your data labeling platform, and get instant access to the features checklist that will help to accelerate your data labeling.
How to Choose the (right) Data Labeling Platform
Why Does Data Labeling Matter?
Let's cut it to the chase: machine learning models are only as good as the data used to train them. The only thing your company actually needs to drive AI success is a large amount of high-quality, well-labeled training data.
Poorly-labeled and low-quality training data will lead to the classic "garbage-in-garbage-out" caveat. According to Gartner, a well-known research firm, "organizations believe poor data quality to be responsible for an average of $15 million per year in losses."
According to Cognilytica, companies spend more time on data labeling than on any other phase of the data science lifecycle. Even though, at first glance, data labeling looks like a trivial task, don't get fooled: this process is more challenging than it seems. And if done incorrectly, it's a recipe for disaster.
There are many ways you could choose to label your training datasets. And each one of these has its own challenges, from potential security and compliance risks, high operation costs, and low model accuracy or bias that might render your model useless. This article will walk you through the criteria to consider when choosing your data labeling platform to fit your organization's needs.
Budget and Organizational Requirements
Let's face it: budget is likely one of the critical criteria you'll consider before signing up.
When searching for software, buyers often tend to have apparent views on their feature requirements vs. any non-functional requirements. Spending time to evaluate your needs will help you to get the best possible offer when discussing with vendors. Our advice for you is to sum up, your needs on the following:
- usage;
- team;
- security and compliance.
Usage
Many software licensing fees are based on usage. If you are already using a labeling solution, make sure to prepare a precise summary of your past and current usage. If you are new to the game, your estimated usage can be pretty hard to assess. Here are some data points worth collecting:
- number of people involved in the labeling activities regularly;
- need to scale up and down your workforce frequently;
- the volume of documents to be labeled;
- storage space required to host files;
- an average number of annotations per document.
If it's too hard to estimate your usage, try to favor solutions offering maximum flexibility and simulate the worst-case scenario.
Team
Machine Learning teams have diverse profiles. Our recommendation is to gather people involved, state what their roles will be, and then outline their responsibilities in the process. When looking at solutions, always try to understand how your team collaboration would work with it.
Security & Compliance
Dealing with data is a sensitive topic triggering many requirements regarding security, the regulations we must comply with, and privacy concerns. New regulations and constraints always impact those one can't afford to overlook.
Every organization has its own set of industry-specific regulations (e.g., HIPAA) and a more general-purpose set of rules and standards to comply with (e.g., GDPR). Also, some businesses are more sensitive than others (e.g., the Defense industry).
Security
Security is a broad topic, but here's our shortlist of points to keep in mind:
- Where is the solution hosted (for Cloud solutions)? Is it okay for you to host data there?
- How safe are data access procedures? Will my data be isolated from the data belonging to other customers? What authentication methods are used? Multi-factor auth? Enterprise SSO? Some proprietary solution, maybe? Is the data app capable of encrypting my data?
- What certification does the vendor have to prove a given level of security? (e.g. SOC-2, ISO 27001)
- How can you audit the system?
Compliance
Each industry comes with its own set of legal and compliance requirements. If you are regulated, evaluate possible issues with data labeling activities and check that the data labeling solution you consider is helping you stay compliant. For instance, if you are a U.S.-based company working on medical data containing personal information, the vendor must comply with HIPAA. If you are working for the Defense industry, chances are that you can't use a cloud-hosted solution and have to look for one that can be deployed on your premises.
Data Labeling Core Features
Let's deep-dive into the type of features you need:
- type of data and labeling interface;
- workflows;
- efficiency tools;
- reporting and project supervision.
Type of data and Labeling interface
Data
Labeling solutions are focused on unstructured data. This can mean a wide variety of asset types to handle. What's more, many subcategories related to your specific use case may exist for each of these types. Let's take a more detailed example: images can be straightforward, but if you work with satellite images, multiple additions may come into play, like geocoding, high-resolution imagery, handling tiles, the need for multispectral images, and many more.
It's essential to have an understanding of not only the raw data at hand but also the expected output. For instance, TIFF images cannot be displayed in a web browser, but this doesn't mean they cannot be converted to be labeled by a remote team. Share your use case and data specifications with vendors.
Interface
To add annotations to your raw data, you must create a labeling UI with jobs matching your expected output.
To choose a labeling solution, knowing what output you expect is crucial. This way, you'll be in an excellent position to evaluate if you can build the proper labeling UI to support your labeling projects.
Workflow
Workflows are one of the most salient parts of a data annotation project. And if powerful enough, they can significantly improve your labeling accuracy.
For this reason, our advice is for you to search for a tool that allows you to:
- prioritize assets in the labeling queue;
- assign assets to specific labelers;
- do targeted reviews based on quality indicators, or add validation rules.
1: Prioritize assets in the labeling queue
Efficiency tools
Since labeling can be a time-consuming and costly operation, efficiency is probably your core concern. Naturally, your data labeling solution should be capable of providing you with features that would foster this needed efficiency.
To speed up the process without compromising quality, we recommend you to focus on capabilities such as smart tools (interactive segmentation, tracking) and automation (active learning and AutoML, model-in-the-loop for pre-labeling, and then review instead of creating your annotations from scratch).
Faster segmentation with our interactive tool
Automatic tracking of objects across multiple frames
Reporting & Project Supervision
You can't improve what you can't track. That's why your research of a data labeling tool should also consider the reporting and analytics features.
Analytics can help you identify productivity issues within your team and build reporting on labeling expenses.
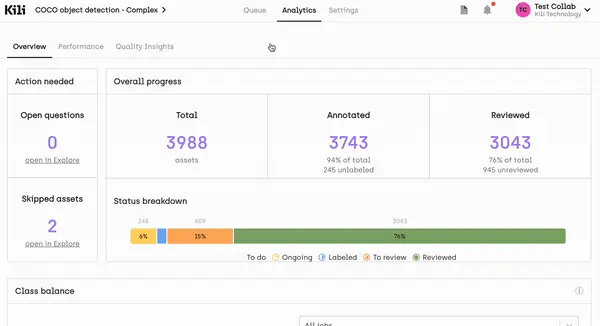
Leverage project analytics to supervise productivity and inspect completed work
Data Quality Features
Review
To make your review more meaningful and cost-effective, your data labeling solution should help you focus your review on data slices with the lowest quality metrics. Since it is often impossible to review everything, the challenge is to review the right thing.
Additionally, it would be best if you searched for features likely to help you to find and fix errors in your ML datasets. Here, you should look for two capabilities:
- quality supervision and monitoring of quality improvements;
- identifying the data that matters the most to improve your model's performance.
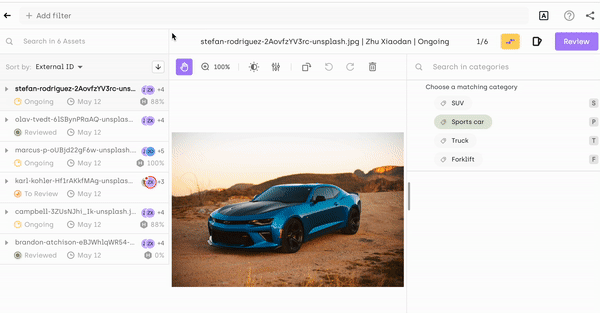
Locate and review specific labels using the Explore UI
Quality Metrics
Quality management is arguably one of the most important aspects of a data labeling project. There is always room for error when performing data annotation, as it is a task that calls for a lot of precision and scrutiny. Labeling mistakes can often stay unnoticed, which is why the data labeling solution of your choice must have quality management tools built into it.
At the annotation level, we recommend tracking consensus and honeypot. Consensus by class will let you know if your ontology needs to be reshuffled. Honeypot measures the accuracy of annotations. At the project level, we'd advise keeping a close eye on class balance.
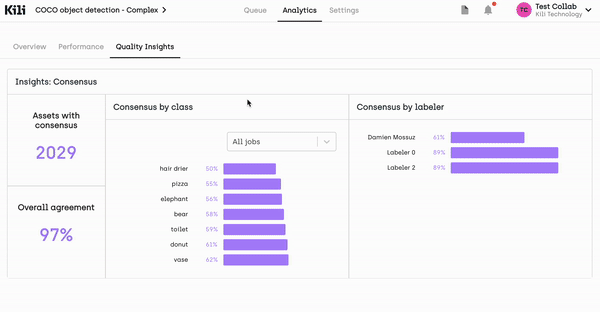
With consensus enabled, you can focus your review on assets with low consensus scores
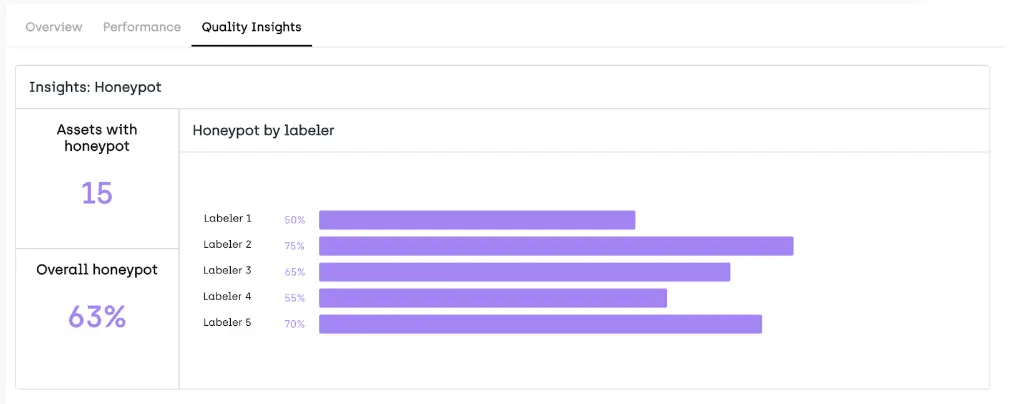
Check each labeler accuracy using honeypot
Labeling Ops
Labeling Ops can be seen as a subdomain of MLOps. Where MLOps focuses on designing and running machine learning systems, Labeling Ops orchestrates the labeling solution in your flow.
Importing data
Moving data in and out is often seen as a process of little value. It's important logistics, but it's still a supporting activity for tasks of higher value.
When looking for a solution, evaluate how you can move data in. Given the volume of data you need to process and the frequency, not all solutions are equally important.
At Kili Technology, for example, we offer 3 ways to import data:
- Drag and drop to upload directly from the UI.
- Upload through API using our SDK. This is suitable for large volumes of data to upload and useful when automating the process (if you have to do it regularly).
- Direct integrations with cloud storage vendors, such as Amazon S3 or Azure Blob Storage, to avoid moving data and enable accessing it remotely.
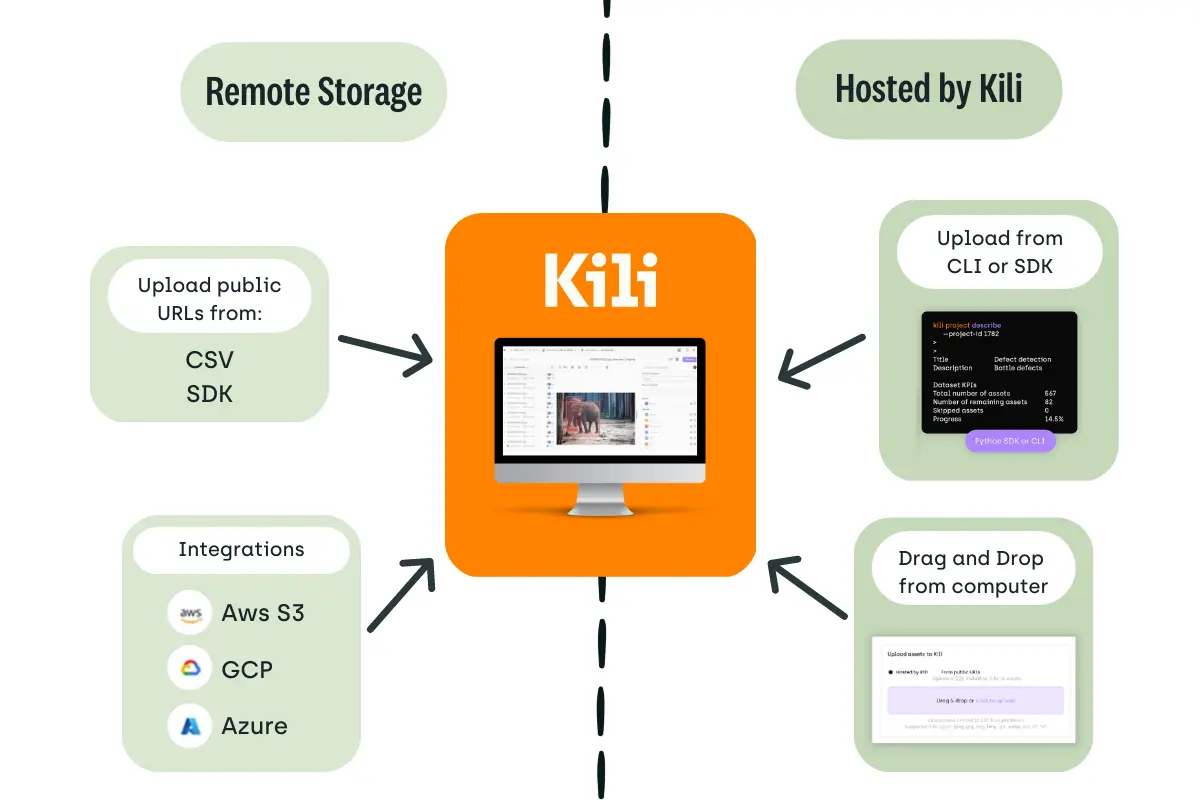
Where your data is hosted depending on your storage mode when using the Kili Technology Platform
Exporting data
Exporting data is as essential as importing it. The main output of a data labeling solution is the annotations. We advise you to look at the output format and ensure it is not locking you to a specific vendor. There is no established standard, so they all have their own ways of formatting it. Just ensure that your exported data can be easily parsed in case you lose access to the tool that generated it.
You may also be interested in having support for standard formats to avoid extra processing on your side. At Kili Technology Technology, we support popular object detection models such as YOLO or PascalVOC. Though not a must, having this support can be pretty convenient.
Automation
If you already have an ML stack and you create labeling batches regularly, automation will save you tons of time setting up projects each time you do that.
At Kili Technology, we offer a very comprehensive SDK so you can deeply integrate our app into your systems using something as basic as a Jupyter notebook or a more complex solution with orchestration.
Automation can be used for basic logistic tasks such as creating projects and moving data in and out, but we strongly encourage you to try it out with more complex cases, like running QA scripts on labels, creating issues for targeted review, using your model-in-the-loop to create pre-annotations, or evaluating the impact of new labels on the model's performance. Each one of these may prove a game-changer for building top-quality datasets.
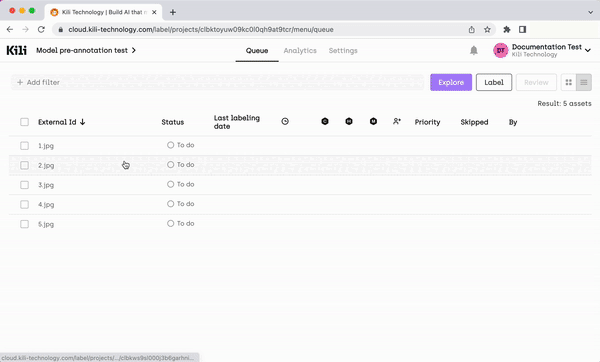
Upload pre-labels generated by your model and review them
Platform Ecosystem & Services
Qualified Workforce
Among all the bottlenecks our customers encounter, the workforce is the most recurring and critical one. Indeed, a good workforce is complex and critical to find. Internally, it's usually very challenging for an ML team to crowdsource its annotations from the rest of the company. It's also very challenging for internal subject matter experts to find the bandwidth needed to share their expertise with the various stakeholders involved in a data labeling project.
Sure, outsourcing (totally or partly) the annotation process sounds like a fit (and is usually what most companies search to do). But the process is trickier than it seems.
In a worst-case scenario, the data labeling platform of your choice won't support you in this research. In a best-case scenario, it will partner with labeling companies that ensure proper privacy and security levels.
At Kili Technology, our network of trusted partners complies with a comprehensive set of requirements and actively participates in our customers' successes. Feel free to email us if this could help.
Customer Care & Support
We get it: Customer Care and Support are usually considered a solution's "nice to have" perks. Nonetheless, our advice would be to make sure your vendor provides you with the following:
Documentation and custom onboarding will help your team become self-sufficient in the long term.
Of course, if you want your team to focus entirely on the objective, our advice for you is to search for a solution capable of providing you with advanced, dedicated support. In fact, most of the solutions available on the market provide such support, but the real gem to search for when it comes to support is ML consultancy. As illustrated by the success story of Luko, ML consultancy is definitely worth investing in.
Learn more!
The on-demand replay of our webinar "Data labeling: what are my options" will deepen your understanding of the
Choosing a Data Labeling Solution: in a Nutshell
A well-labeled training dataset is vital to the success of your ML project, but labeling a dataset is not as easy as it seems; to the contrary: it may pose many challenges.
A variety of labeling solutions available on the market aim to address these issues, but not all of them will match your organization's requirements. We hope this article has helped you in the process of selecting the best one.
If you're still on the fence about which solution to choose, here's a helpful checklist (you can use it each time you're in doubt):
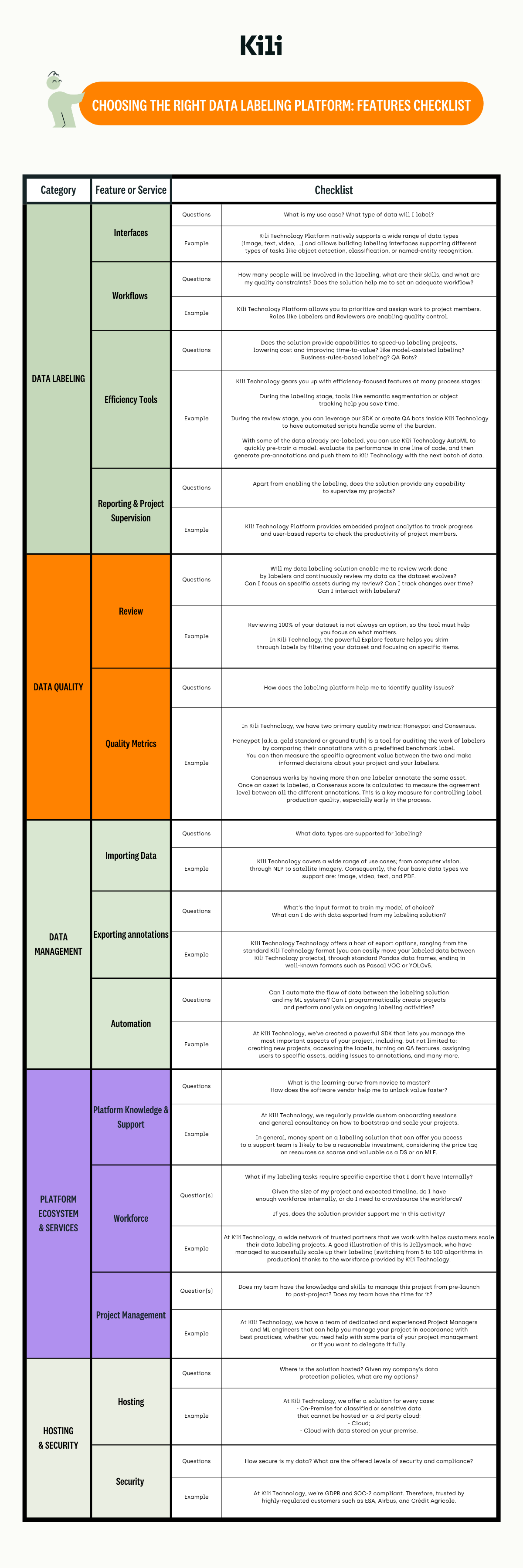
Data Labeling
Interfaces
Questions
What is my use case? What type of data will I label?
Example
Kili Technology natively supports a wide range of data types and enables building labeling interfaces that support different types of tasks like object detection, classification, or named-entity recognition.
Workflows
Questions
How many people will be involved in the labeling, what are their skills, and what are my quality constraints? Does the platform help me set a good workflow?
Example
At the most basic level, you can assign project members specific roles in the Kili Technology platform, like "labeler" or "reviewer." These roles define the types of tasks and the scope of responsibilities of your team members. Additionally, Kili Technology lets you prioritize work and then assign it to specific project members.
Efficiency Tools
Questions
Does the solution provide mechanisms to speed up labeling projects, lower cost, and improve time-to-value like model-assisted labeling, business rules-based labeling, or QA bots?
Example
Kili Technology gears you up with efficiency-focused features at many process stages.
- During the labeling stage, tools like semantic segmentation or object tracking help you save time.
- During the review stage, you can leverage our SDK or create QA bots inside Kili Technology to have automated scripts handle some of the burdens.
- With some of the data already pre-labeled, you can use Kili Technology AutoML to quickly pre-train a model, evaluate its performance in one line of code, generate pre-annotations, and push them to Kili Technology with the next batch of data.
Reporting & Project Supervision
Question
Does the solution provide any capability to supervise my projects besides enabling the labeling?
Example
Kili Technology provides in-app project analytics to track progress and lets you generate user-based reports to check the productivity of specific project members.
Data Quality
Review
Questions
Will my data labeling solution enable me to review work done by labelers, and continuously review my data as the dataset evolves?
Can I focus on specific assets during my review? Can I track changes over time? Can I interact with labelers?
Example
Reviewing 100% of your dataset is not always an option, so the tool must help you focus on what matters. In Kili Technology, the powerful Explore feature helps you skim through labels by filtering your dataset and focusing on specific items.
Quality Metrics
Question
How does the labeling platform help me identify quality issues?
Example
The Kili Technology platform has two primary quality metrics: Honeypot and Consensus.
Honeypot (a.k.a. gold standard or ground truth) is a tool for auditing the work of labelers by comparing their annotations with a predefined benchmark label. You can then measure the specific agreement value between the two and make informed decisions about
Data Management
Importing Data
Questions
What dataconcentrateconcentratere supported for labeling?
Example
Kili Technology covers various use cases, from computer vision, through NLP to satellite imagery. Consequently, the four basic data types we support are image, video, text, and PDF.
Exporting annotations
Questions
What's the input format to train my model of choice? What can I do with data exported from my labeling solution?
Example
Kili Technology offers a host of export options, ranging from the standard Kili Technology format (you can easily move your labeled data between Kili Technology projects), through standard Pandas dataframes, ending in well-known formats such as Pascal VOC.
Automation
Questions
Can I automate the data flow between the labeling solution and my ML systems? Can I programmatically create projects and perform analysis on ongoing labeling activities?
Example
At Kili Technology, we've created a powerful SDK that lets you manage the most important aspects of your project, including, but not limited to, creating new projects, accessing the labels, turning on QA features, assigning users to specific assets, adding issues to annotations, and many more.
Platform Ecosystem & Services
Platform Knowledge and Support
Questions
What is the learning curve from novice to master? Will the software vendor help me unlock value faster?
Example
In general, money spent on a labeling solution that can offer you access to a support team is likely to be a critical investment, considering the price tag on resources as scarce and valuable as a DS or an MLE.
Workforce
Questions
What if my labeling tasks require specific expertise that I don't have internally? Given the size of my project and expected timeline, do I have enough workforce internally, or do I need to crowdsource the workforce? If yes, does the solution provider support me in this activity?
Example
At Kili Technology, a vast network of trusted partners that we work with helps customers scale their data labeling projects. A good illustration of this is Jellysmack, who managed to successfully scale up their labeling (switching from 5 to 100 algorithms) thanks to the workforce provided by Kili Technology.
Project Management
Questions
Does my team have the knowledge and skills to manage this project from pre-launch to post-project? Does my team have the time for it?
Example
At Kili Technology, we have a team of dedicated and experienced Project Managers and ML engineers that can help you manage your project in accordance with best practices, whether you need help on some parts of your project management or if you want to delegate it fully.
Hosting & Security
Hosting
Questions
Where is the solution hosted? Given my company's data protection policies, what are my options?
Example
At Kili Technology, we offer a solution for every case:
- On-Premise for classified or sensitive data that cannot be hosted on a 3rd party cloud
- Cloud
- Cloud with data stored on your premise
Security
Questions
How secure is my data? What are the offered levels of security and compliance?
Example
At Kili Technology, we're GDPR and SOC-2 compliant. Our focus on security has won us the trust of highly-regulated companies such as ESA, Airbus, and Crédit Agricole.
When comparing managed annotation providers alongside a platform choice, our reviewed guide to the best data labeling services in 2026 provides a current comparison of the leading options.
An article by
Natassha Shievanie Selvaraj, Data Scientist
Virginie Fulconis, Customer Care Manager @Kili Technology
Benjamin Fourio & Damien Mossuz, Product Managers @Kili Technology
Edouard d'Archimbaud, CTO and co-founder @Kili Technology
Przemislaw Czuba, Technical Copywriter @Kili Technology

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
