
.png)
AI Summary
Meta’s Segment Anything Model 2 (SAM 2) represents a significant leap forward in visual segmentation technology, combining architectural innovations with groundbreaking approaches to dataset creation. SAM 2 was trained on the largest video segmentation dataset, emphasizing its scale and significance in advancing video object segmentation. Let’s dive into their paper and discover the model’s capabilities, training methodology, and practical applications through Kili Technology’s implementation.
Introduction to SAM 2
Source: SAM 2: Segment Anything in Images and Videos
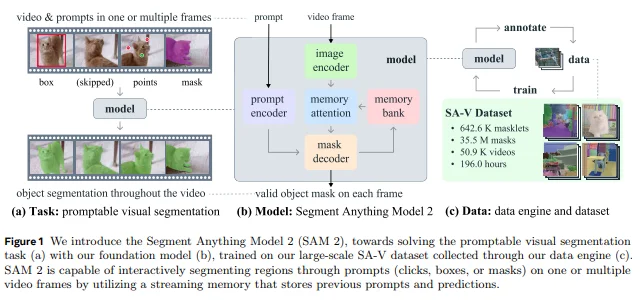
SAM 2 is a unified model for real-time, promptable object segmentation in images and videos. Building on the foundation of the original Segment Anything Model (SAM), SAM 2 extends its capabilities into the video domain, making it a versatile tool for various applications. This foundation model is designed to handle both static images and dynamic video content, providing advanced segmentation and tracking functionalities. With SAM 2, users can achieve efficient and accurate object segmentation in both images and videos, making it an invaluable asset for tasks that require precise visual analysis.
Architectural Innovation for Enhanced Performance
SAM 2 introduces a unified approach to video and image segmentation through its innovative streaming architecture. At its core, the model employs a sophisticated memory-equipped transformer design that processes video frames sequentially while maintaining contextual information about the target object. While SAM 2 processes each object individually, incorporating inter-object communication could enhance efficiency by integrating contextual information between objects. The architecture consists of several key components:
Memory-Centric Design
- A memory bank that retains information about past predictions using a FIFO queue of up to N recent frames
- Storage of prompted frame information in a separate queue of up to M frames
- Object pointers that maintain high-level semantic information as lightweight vectors
- Temporal position information embedded into recent frame memories for short-term motion representation
Streaming Processing Pipeline
- An image encoder based on MAE pre-trained Hiera for real-time processing
- Memory attention operations that condition current frame features on past frame features and predictions
- A prompt encoder accepting clicks, boxes, or masks to define object extent
- A mask decoder that can predict multiple valid masks when faced with ambiguity
The architecture achieves superior accuracy while requiring up to 3x fewer user interactions compared to previous approaches. For instance, when processing video content, the memory bank enables consistent object tracking even through challenging scenarios like occlusions or rapid movements.
The Data Engine: A Three-Phase Evolution
Meta’s development of the SAM 2 Data Engine represents a significant methodological advancement in video segmentation data collection. Through systematic iteration and rigorous evaluation, the research team evolved their approach across three distinct phases, each marked by substantial improvements in annotation efficiency and data quality.
The advancements in the SAM 2 Data Engine have significantly improved the handling of complex video data for annotation and segmentation tasks.
Phase 1: Establishing Baseline Performance Through Manual Annotation
The initial phase focused on establishing fundamental performance benchmarks through a meticulous frame-by-frame annotation process. Utilizing the interactive SAM model, annotators employed precision tools including brush and eraser functions to generate high-fidelity mask definitions. This labor-intensive approach required an average of 37.8 seconds per frame but proved instrumental in creating a high-quality ground truth dataset comprising 16K masklets across 1.4K videos.
The significance of Phase 1 extended beyond its immediate output. The manually annotated data, characterized by its exceptional precision, served as the foundation for validation and test sets. This methodological decision proved crucial for maintaining robust evaluation standards throughout subsequent development phases.
Example of masklets from the SAM 2 paper.

Phase 2: Architectural Advancement Through Temporal Propagation
Building on insights from Phase 1, the second phase introduced a significant architectural innovation through SAM 2 Mask capabilities. This advancement represented a hybrid approach, combining sophisticated temporal propagation mechanisms with retained manual refinement capabilities. Challenges such as object motion, deformation, occlusion, and lighting changes were addressed through these architectural advancements. The technical implementation achieved several key improvements:
- Reduction in annotation time to 7.4 seconds per frame (5.1× efficiency gain)
- Collection of 63.5K masklets
- Implementation of multiple retraining cycles
- Integration of continuous feedback loops for model improvement
The iterative retraining methodology proved particularly valuable, as each cycle incorporated new insights derived from the growing dataset, leading to progressive improvements in model performance.
Phase 3: Comprehensive Integration of Memory-Based Architecture
The final phase marked a paradigm shift in annotation methodology through the full deployment of SAM 2 with memory-enabled refinement capabilities. Key technical innovations included:
- Click-based refinement protocols replacing full mask annotations
- Memory-based temporal propagation
- Integrated quality verification systems
- Real-time performance feedback
This comprehensive architectural advancement yielded remarkable improvements:
- Further reduction to 4.5 seconds per frame (8.4× total efficiency gain)
- Collection of 197.0K masklets
- Implementation of five strategic retraining iterations
- Enhanced consistency in temporal tracking
Quality Assurance Infrastructure
Annotation protocol from SAM 2's paper.

Central to the Data Engine's success was its robust quality assurance framework, comprising multiple integrated components:
- Multi-Stage Verification Protocol:
- Initial automated quality checks
- Expert annotation specialist review
- Temporal consistency validation
- Boundary precision assessment
- Refinement Workflow:
- Automated detection of substandard masklets
- Mandatory refinement protocols
- Iterative quality improvement cycles
- Performance metric tracking
- Rejection Criteria:
- Clear boundary definition requirements
- Temporal coherence thresholds
- Minimum quality standards
- Object definition clarity
Final Training Data Distribution
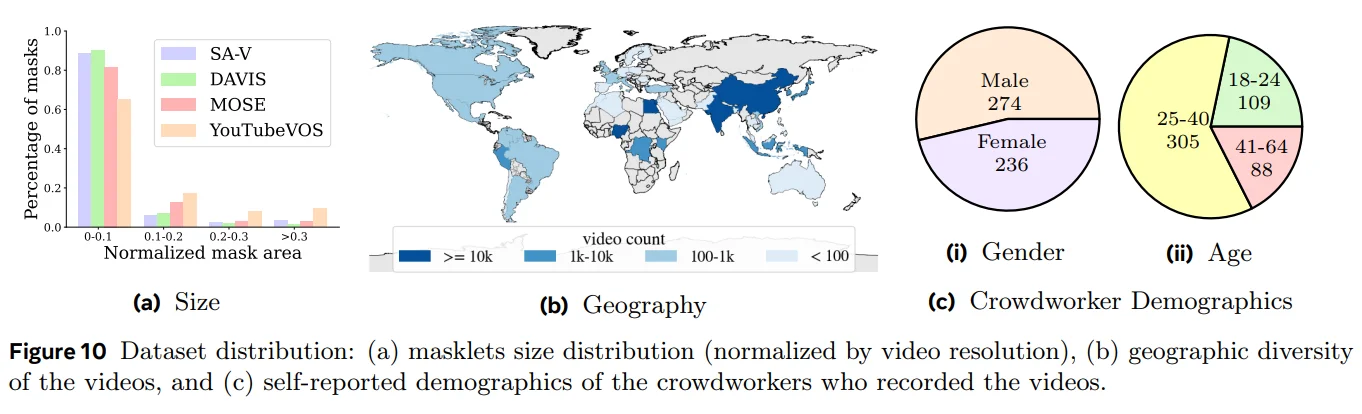
Dataset distribution and demographics of human annotators from SAM 2's paper.
The Data Engine's output culminated in the SA-V dataset, implementing a meticulously calibrated training data distribution across multiple sources. The core composition allocated approximately 70% to SA-V, 14.8% to an internal dataset, and 15.2% to SA-1B. This distribution was further refined when incorporating open-source datasets, shifting to approximately 49.5% SA-V, 15.1% internal data, 15.5% SA-1B, and dedicated allocations for specialized datasets (DAVIS at 1.3%, MOSE at 9.4%, and YouTubeVOS at 9.2%).
The SA-V Dataset Characteristics
At its core, the dataset comprises 50.9K videos spanning 196 hours of content, generating 642.6K masklets through a dual-stream annotation approach. This approach strategically balances manual precision (190.9K masklets) with automated coverage (451.7K masklets), enabling comprehensive object capture while maintaining annotation quality.
Technical Parameters:
- Resolution diversity: 240p to 4K
- Mean dimensions: 1,401 × 1,037 pixels
- Duration range: 4 seconds to 2.3 minutes
The dataset's distribution characteristics reveal careful attention to ecological validity and real-world applicability. Environmental representation maintains a balanced distribution between indoor (54%) and outdoor (46%) scenarios, while geographic diversity spanning 47 countries ensures robust model performance across varied cultural and architectural contexts.
Distribution Metrics:
- Geographic coverage: 47 countries
- 88% of instances < 0.1 normalized area
- 42.5% disappearance rate in manual annotations
The dataset's emphasis on challenging cases is of particular significance, with 88% of instances exhibiting a normalized area less than 0.1. This deliberate focus on smaller objects addresses a critical gap in existing datasets while reflecting real-world object distribution patterns. The 42.5% disappearance rate in manual annotations provides robust coverage of occlusion scenarios, essential for developing models capable of handling complex real-world tracking challenges.
The automated component's three-tier sampling strategy represents a sophisticated approach to comprehensive object coverage:
- Base Layer: A 32 × 32 grid applied to the primary frame establishes foundational coverage
- Intermediate Layer: 16 × 16 grid across 4 zoomed regions enables medium-scale object capture
- Fine-grained Layer: 4 × 4 grid spanning 16 zoomed regions ensures precise detection of small objects
This hierarchical sampling approach ensures comprehensive object coverage while adapting to varying object sizes and positions within the frame. The multi-scale design particularly excels at capturing objects at different spatial scales, a crucial capability for real-world applications where object size can vary significantly.
Comprehensive Evaluation of SAM 2
The development of robust foundation models requires extensive validation across diverse scenarios to ensure real-world applicability. Meta’s Segment Anything Model 2 (SAM 2) underwent comprehensive evaluation across an unprecedented range of datasets, establishing new benchmarks for both video and image segmentation tasks. SAM 2 excels in solving promptable visual segmentation tasks, thanks to its advanced architecture and dataset enhancements.
Zero-Shot Performance Across Diverse Domains
Partial results of SAM 2. Full results can be found on their paper.
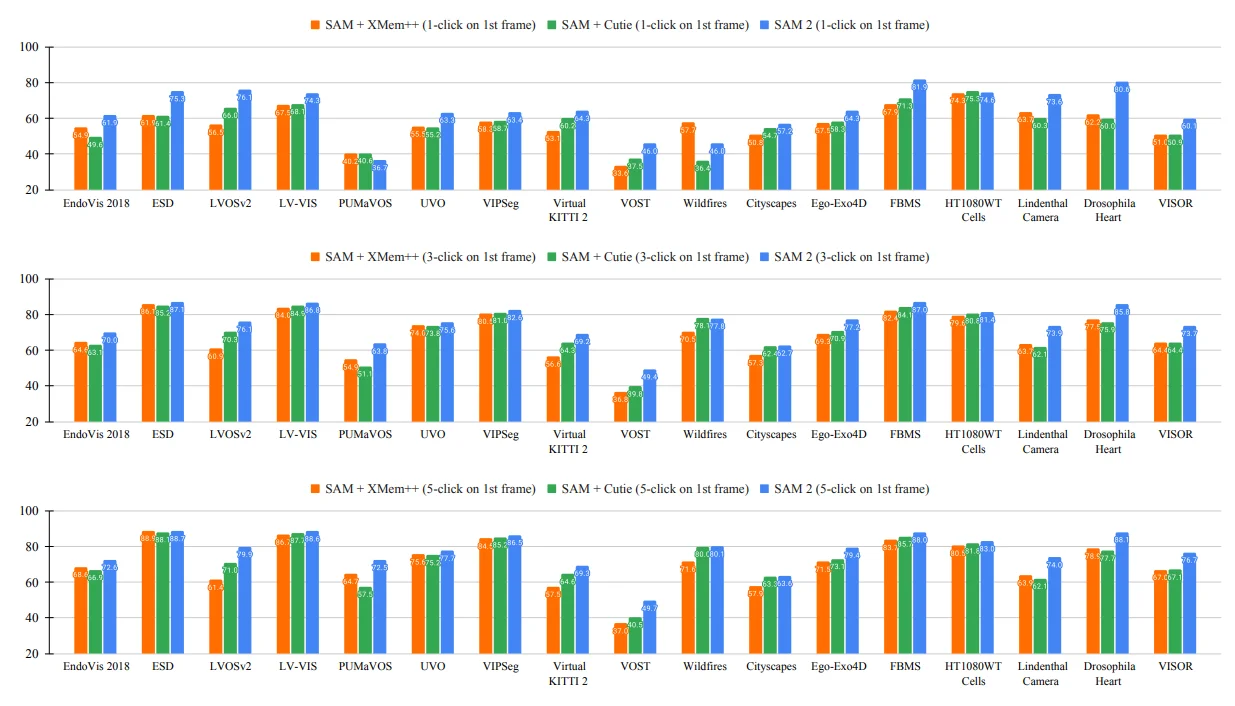
SAM 2's zero-shot capabilities were evaluated across 17 specialized video datasets, encompassing domains from medical imaging to autonomous driving. Notable evaluation datasets included:
- EndoVis 2018: Medical surgery videos featuring robotic instruments
- ESD: Robot manipulator camera footage with motion blur challenges
- LVOSv2: Long-term video object segmentation benchmark
- Virtual KITTI 2: Synthetic driving scene data
- VISOR: Egocentric videos in kitchen environments
- Drosophila Heart: Microscopy videos of fruit fly cardiac tissue
The model demonstrated remarkable adaptability, achieving superior performance with significantly reduced interaction requirements. Specifically, SAM 2 generated higher quality segmentations while requiring more than 3× fewer user interactions compared to established baselines like SAM+XMem++ and SAM+Cutie.
Video Segmentation Performance
In the semi-supervised video object segmentation (VOS) setting, SAM 2 established new state-of-the-art results across multiple benchmarks:
- MOSE val: 77.9% J&F score (6.2% improvement over previous best)
- DAVIS 2017 val: 90.7% J&F score (2.6% improvement)
- YTVOS 2019 val: 89.3% G score (1.8% improvement)
- SA-V test: 78.4% J&F score (15.6% improvement)
SAM 2 can efficiently track multiple objects simultaneously, even in challenging environments such as crowded scenes.
These improvements were achieved while maintaining real-time processing speeds of 43.8 FPS for the Hiera-B+ variant and 30.2 FPS for the Hiera-L variant on a single A100 GPU.
Image Segmentation Capabilities
On image segmentation tasks, SAM 2 demonstrated enhanced efficiency without compromising accuracy:
- 58.9% 1-click mIoU on SA-23 benchmark (improving upon SAM's 58.1%)
- 6× faster inference compared to the original SAM
- Consistent performance improvements across both image and video domains
The model's superior performance across diverse datasets, combined with significant efficiency improvements, demonstrates the importance of thorough evaluation in developing practical AI solutions. As visual segmentation technology continues to evolve, maintaining high standards in evaluation datasets and methodologies will remain crucial for bridging the gap between research innovations and real-world implementation.
Processing Video Frames with SAM 2
Processing video frames with SAM 2 involves a series of sophisticated steps. Initially, the video frames are loaded into the model, where the target object is identified. SAM 2 then leverages its advanced segmentation and tracking functionalities to segment the object in each frame. While SAM 2 can track multiple objects in a video simultaneously, it processes each object separately, utilizing only shared per-frame embeddings without inter-object communication. This simpler approach allows for effective tracking, though incorporating shared object-level contextual information could aid in improving efficiency. Additionally, SAM 2 supports promptable visual segmentation, allowing users to define the extent of the object in a given frame using intuitive inputs like clicks, bounding boxes, or masks. This flexibility makes SAM 2 a powerful tool for interactive video segmentation, ensuring precise and efficient object tracking.
Limitations and Future Work
While SAM 2 is a powerful tool for image and video segmentation, it does have some limitations. One of the primary challenges is tracking objects across shot changes and handling occlusions, which can disrupt the continuity of segmentation. SAM 2 may also struggle with segmenting objects that have thin or fine details, especially when these objects are moving quickly. In challenging scenarios, the model may struggle when there are nearby objects with similar appearance. The model may also fail to segment objects across shot changes and can lose track of or confuse objects in crowded scenes, particularly after long occlusions or in extended videos. While the model can track multiple objects in a video simultaneously, SAM 2 processes each object separately, utilizing only shared per-frame embeddings without inter-object communication. Future work on SAM 2 will focus on addressing these limitations, enhancing its performance on various video segmentation tasks. Researchers are also exploring the application of SAM 2 in diverse domains such as robotics, healthcare, and autonomous vehicles, aiming to broaden its impact and utility in solving complex visual segmentation challenges.
From Research to Reality: SAM 2's Implementation in Professional Annotation Tools
Meta's meticulous approach to dataset curation and quality control has proven instrumental in SAM 2's practical success. The comprehensive three-phase data collection strategy, coupled with rigorous verification protocols, enabled the development of a model that excels in real-world applications. This foundation of quality has made SAM 2 particularly valuable for professional annotation platforms, as demonstrated by its integration into Kili Technology's annotation ecosystem.
Kili Technology's Implementation Framework
Kili Technology has leveraged SAM 2's capabilities through a carefully designed implementation that preserves the model's core strengths while optimizing for specific industry needs. The platform offers two specialized deployment models:
- Rapid Model: Optimized for projects requiring quick turnaround without compromising essential accuracy
- High-res Model: Enhanced for maximum precision in detailed annotation tasks
This dual-model approach ensures that organizations can balance speed and accuracy according to their specific requirements while maintaining the high standards established by Meta's original implementation.
Advanced Geospatial Analysis Capabilities
The integration of SAM 2 has transformed how teams work with geospatial imagery. Kili's enhanced toolkit introduces interactive Point and Bounding Box tools that provide unprecedented control over segmentation precision. The platform addresses traditional constraints in large-scale geospatial data processing through:
- Unified Processing Architecture
- Seamless handling of both tiled and non-tiled images
- Adaptive zoom-level precision
- Efficient processing of large-scale geographical data
- Industry Applications The system has enabled significant efficiency gains across multiple sectors:
- Urban planning teams complete infrastructure mapping projects in a fraction of the traditional time
- Environmental researchers track subtle changes in land use patterns with unprecedented precision
- Government agencies streamline their geospatial data processing workflows for improved resource management
Revolutionary Video Annotation System
Kili’s implementation of SAM 2’s Smart Tracking feature fundamentally transforms the video annotation workflow. The system combines sophisticated tracking capabilities with intuitive user controls:
SAM 2's capabilities significantly enhance the handling of complex video data for annotation tasks, improving workflows across various applications.
Technical Implementation
The video annotation process builds on SAM 2's memory-based architecture through:
- Single-click initialization capability on any frame
- Automatic propagation across 50 subsequent frames
- Intelligent pause/resume functionality via 'Esc' key
- Optimized single-target tracking for maximum precision
Industry-Specific Applications
The platform's video annotation capabilities benefit several key sectors, as demonstrated through Kili Technology's implementation:
Security and Surveillance
- Track objects of interest through surveillance footage with minimal manual intervention
- Enable faster incident analysis
- Support monitoring tasks through efficient object tracking
Media and Entertainment
- Streamline visual effects workflows
- Support content moderation for streaming platforms
- Enable efficient object tracking for post-production
Research and Development
- Facilitate precise annotation of experimental footage
- Support consistent subject tracking in research contexts
- Reduce time investment in data preparation phases
This implementation follows SAM 2's core capabilities of requiring 3× fewer interactions than prior approaches while maintaining segmentation accuracy. The platform's ability to handle click-based refinements and mask propagation makes it particularly valuable for professional annotation workflows.
Quality Assurance and Workflow Integration
Kili's implementation maintains rigorous quality standards through:
- Real-time quality feedback during annotation
- Integrated review workflows for team collaboration
- Performance metrics tracking for quality assessment
This systematic approach to quality assurance ensures that the high standards established during SAM 2's development carry through to practical applications, while the streamlined interface makes these capabilities accessible to diverse technical teams.
The successful integration of SAM 2 into Kili Technology's platform demonstrates how careful attention to dataset quality and model architecture during research and development can translate into practical, industry-ready solutions. The combination of Meta's foundational work and Kili's focused implementation creates a powerful tool that advances the state of professional annotation capabilities across multiple industries.
Discover the Power of SAM 2 in Your Projects
Are you ready to revolutionize your geospatial and video annotation workflows with the cutting-edge capabilities of SAM 2 integrated into Kili Technology's platform? Our team is here to help you harness the full potential of this advanced technology. Let us show you how our tools can transform your annotation processes and improve your model. Reach out now!

_logo%201.svg)




