
.png)


_logo%201.svg)


AI Summary
Getting AI to work across a variety of hardware devices is hard. Currently, two major problems hold back progress:
- the strategic mission is to construct the most compact yet high-performing datasets
- the challenge of simplifying deployment and scalability to the maximum when integrating software into hardware
What helps organizations succeed in edge AI projects is better data combined with better processes that build repeatability and trust. Kili and Latent AI have partnered to make edge AI more accessible to implement from data to deployment. By optimizing these components, we can forge a path toward AI solutions that not only overcome current deployment and scalability hurdles but also lay a solid foundation for future AI development and implementation.
This is the beginning of a two-part series highlighting how Kili and Latent AI can move your models to market faster. This first post will detail why building high-quality datasets is essential for ML teams and why it remains a challenging task today. We will also go through Latent AI’s LEIP portfolio, which helps organizations rapidly prototype models for different hardware and deliver lightweight, highly efficient AI optimized for size, memory, and computing.
The second post will detail how Kili and Latent AI can be combined in a workflow designed to smooth edge model design and deployment.
Building Datasets of the Highest Quality with Kili Technology
Why is Data Quality Important?
Machine learning and artificial intelligence cannot overstate the importance of data labeling accuracy. Research has consistently demonstrated that a 10% decrease in labeling accuracy can have a substantial ripple effect, resulting in a 2 to 5% decrease in model performance. 2 to 5% in model performance is a massive gap: it is like a self-driving car driving over 5 pedestrians out of 100. ML teams usually inject more data into the dataset to mitigate this drop in performance, leading to larger datasets and, subsequently, higher labeling costs. This does not solve the issue: more data does not automatically mean better performance when the data is poorly labeled. Therefore, investing in data quality from the get-go is an intelligent way to manage performance and resources: label less data, meaning smaller datasets and lower infrastructure costs, to generate as high a model performance as possible. Beyond its financial and performance implications, putting label quality as a number 1 focus also greatly impacts limiting biases within datasets.
Biases related to factors such as race, gender, and xenophobia can propagate through machine learning models and impact the performance and adoption of the final product. Therefore, ensuring high-quality labels is not merely a matter of technical proficiency; it is a fundamental step toward building ethical and unbiased AI systems.
Build your own high-quality datasets for machine learning
Machine learning outcomes depend on the quality of training datasets. Build the best dataset for your ML project with our platform today.
Why Is Achieving Data Quality Difficult?
Creating precise and efficient AI models extends beyond writing great code. Today, we see the emergence of data as the source, shifting from the revolution of the 2000s, where code was the core of all digital interfaces. This paradigm shift emphasizes the importance of managing datasets. While writing good, clean, and precise code remains crucial, it's becoming evident that improving the dataset rather than the algorithms will make significant performance enhancements when building AI models. Consequently, the core focus of machine learning teams is transitioning from model development to cultivating high-performance datasets. However, achieving data quality is a difficult task. Today, it is estimated that 3,4% of the data in public datasets has erroneous labels. Quickdraw (a dataset by Google) records an error rate of 10%, while ImageNET is at 6%. Why is that? Well, even seemingly straightforward labeling tasks present complexities. Let’s take the example of detecting a kite surfer in an image. Should the bounding box include the surfer, the sail, or both? Establishing clear and precise labeling guidelines at the project's outset and ensuring consistent adherence throughout are essential. Classification tasks, even binary ones like 'yes' or 'no,' introduce complexity: should an Easter chocolate bunny qualify as a 'bunny'? Is a buttered toast qualified as bread? Or is it transformed bread? Should the melted butter on the surface be labeled as butter?
Moreover, a well-balanced dataset distribution is crucial, as imbalances often prevail. For instance, in the automotive industry, imbalances may manifest as a lack of data for scenarios like vehicles with blinkers on, yellow traffic lights, or unique vehicles such as sidecars and quads. Similarly, addressing rare edge cases, such as zigzag road lines or clusters of ten traffic lights, becomes paramount, especially when training models for self-driving cars. In essence, saying that data quality is paramount to ML model performance is fine, but achieving data quality excellence is a complex task that the industry has not yet perfected.
The Strengths of Kili Technology, the High-Quality Training Data Platform
So, when choosing a tool to label your data from beginning to end, looking for the right tools to make data quality excellence possible is essential.
Kili Technology is a versatile tool designed to streamline data labeling, boost productivity, and maximize label quality, all fully integrated into your existing ML stack. Recognizing that labeling can be a laborious task, Kili Technology prioritizes user experience, offering labelers a comfortable and efficient platform with productivity-enhancing features such as keyboard shortcuts and ML automated labeling functions (model-in-the-loop, GPT-automated text labeling, automated object detection based on the highly efficient SAM model, etc). This user-centric approach aims to minimize the time and effort expended, making it conducive for labelers to work for extended durations with solid attention to detail.
Furthermore, Kili Technology places a strong emphasis on quality defense strategies. Acknowledging the inherent complexity and repetition in labeling, it acknowledges that even the most skilled labelers can make mistakes. As a remedy, Kili Technology empowers users to fortify quality through different quality strategies:
Review
Use reviewer permission levels to go over the labels created by the labeling team, add comments, raise issues, validate or send back assets that are erroneous. Keep a tight grip on quality through monitoring.
Watch video
Quality Metrics
Generate quality metrics such as consensus or honeypot to get a global view of the label agreement between labelers or a labeling score based on ground truth.
Watch video
Plugins & Programmatic QA
Automate QA steps with custom plugins, i.e. custom code modules that will automatically detect errors and flag them for your reviewers’ attention.
Watch video
Orchestration of All of the Above
Run all quality strategies consecutively or in parallel, and automate each step of the way as you see fit.
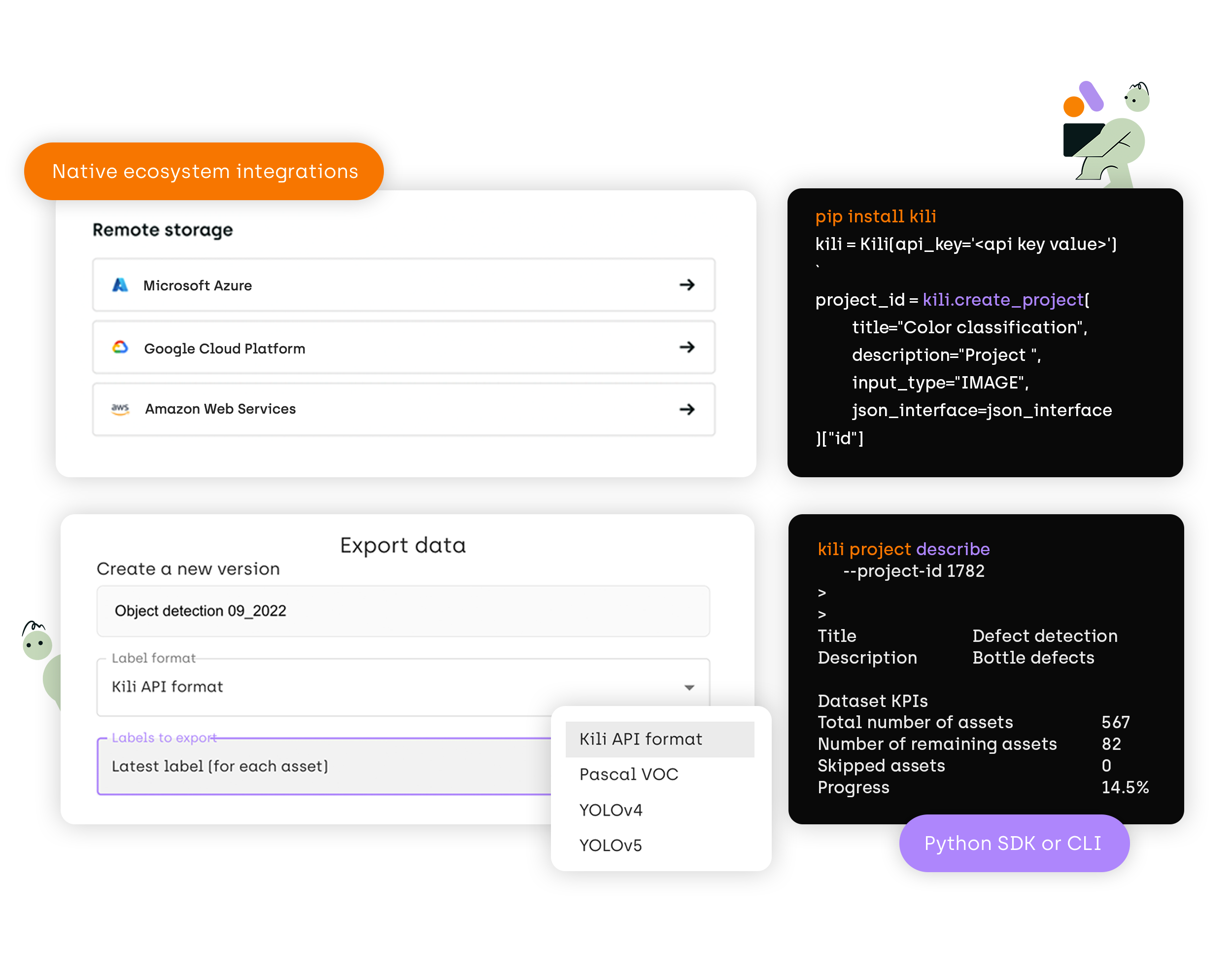
In addition to its commitment to label accuracy, Kili Technology recognizes that labeling is an ongoing process marked by the need to label new assets as the dataset moves and expands, refine existing labels, and extend applications to new use cases. Efficiency and label quality hinge on establishing a robust iteration loop to address issues promptly. Kili Technology facilitates this iterative approach with effortless integration features, including Single Sign-On (SSO) for user convenience, seamless cloud storage integration, simplified and customizable data export capabilities, and automation tools for efficient project pipeline management such as subsequent iterations being pre-labeled with pre-trained models. In essence, Kili Technology is a comprehensive solution that simplifies labeling operations, enhances productivity, and upholds stringent quality standards.
But high quality data is only half the battle. Models still need to be trained on that data quickly enough for the results to be useful. Part of the problem is the amount of time and effort it takes to test different model and hardware combinations to find the best match. The Latent AI Efficient Inference Platform (LEIP) LEIP is an MLOps Software Development Kit (SDK) that can optimize and secure neural network runtimes for specific hardware targets.
LEIP can accept high quality data from Kili, and then uses that to shorten training cycles even further.
Simplify your LabelingOps
Integrate labeling operations on Kili technology with your existing ML stack, datasets and LLMs. Let us show you how.
Delivering optimized edge models quickly with Latent AI
High-quality data is only half the battle. Models still need to be trained on that data quickly enough for the results to be useful. Part of the problem is the amount of time and effort it takes to test different model and hardware combinations to find the best match. Latent AI gives organizations what they’ve been missing – a simplified, repeatable and scalable path for producing and delivering optimized and secured edge models that reduces the time to completion and complexity of ML projects. By applying software development principles to edge models, Latent AI can build model trust with the same continuous cycles of testing and validation by adding edge MLOps capabilities to your current DevOps pipelines.
Latent AI helps you quickly find the best model to match your data and requirements while optimizing and securing it for specific hardware targets. With Latent AI, you gain the tools necessary for:
Rapid AI Prototyping:
Rapidly create and test models with different configurations (SWaP, accuracy, etc.) without configuring for different hardware, compilers, and development frameworks. Accelerate your time to market by 10x by reducing this process to a few hours.
Wide Model/Hardware Support:
Deploy deep learning models across a variety of hardware (drones, wearables, IOT devices, etc.) without the need to integrate new tooling and workflows.
Performance:
Reduce model sizes by up to 84% while also improving performance in inference speed and maintaining accuracy.
Secured Runtime:
Build security into the model itself with integrity checks to prevent tampering and improper access.
Latent AI speeds production of AI for the edge with software that optimize models for compute, memory, and power while simplifying their development and deployment at scale. For more information about how Latent AI can help you move your models to market faster, visit their page at Latent AI.
Now that we've deep dived into the core of both labeling and deploying on the edge, we can continue to the implementation phase. To continue this series and implement a powerful workflow with Kili Technology & LatentAI, read the part 2 of this article on LatentAI's page!
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

