
.png)


_logo%201.svg)


AI Summary
Image classification is more prevalent in modern technologies than the public may imagine. While humans can perceive and decide the nature of an object in split seconds, such capabilities were once unimaginable for computer systems. The emergence of image classification, coupled with machine learning models, brought substantial change.
Today, image classification systems enable industries, including healthcare, ecommerce, and security, to interpret visual data accurately, make informed decisions, and improve operational processes. For example, medical professionals use machine learning-powered imaging solutions to provide accurate diagnoses in lesser time.
In this article, we’ll explore image classification in depth, discussing techniques, use cases, and challenges organizations face when adopting the technology.
Understanding Image Classification in Computer Vision
Image classification refers to the act of determining the most appropriate label for an entire image from a collection of pre-determined labels. It is an essential process for developing computer vision applications.
For example, a computer vision system is required to fit an image of a dog into categories of dogs, cats, and wolves. Through complex calculations, the system concludes that the image is a dog and not a cat or wolf.
Computer systems cannot perceive objects as human does. For computers, objects are digital data made up of pixelated image representation. On its own, such systems cannot deduce the species, gender, or type of an animal. In fact, the system is unlikely to detect any object from the raw data without using a machine learning algorithm.
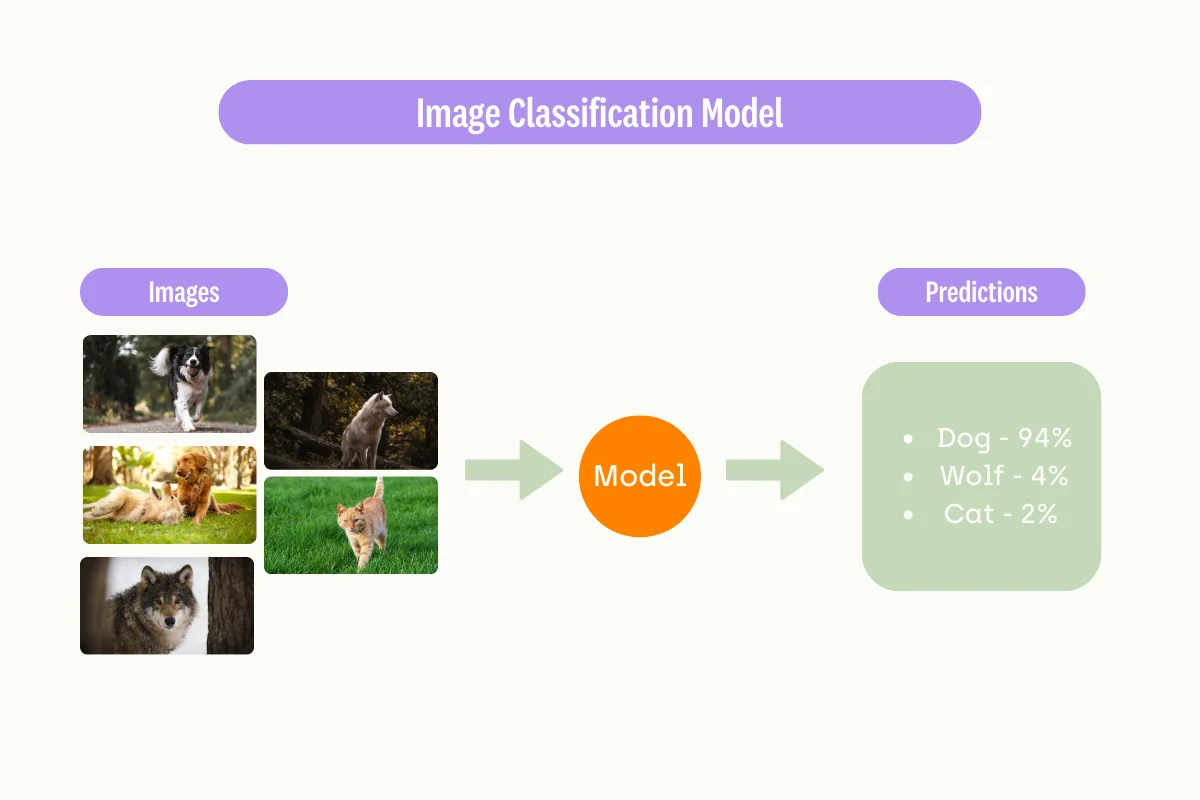
To enable image classification, machine learning engineers train the underlying model with datasets containing various representations of the objects. In our example, the model learns by training with numerous dog images to predict occurrences of the same animal with strong confidence.
A trained model can return the prediction with their respective probabilities. For example:
- Dog - 94%
- Wolf - 4%
- Cat - 2%
By interpreting the score, the computer vision models can confidently assume that the image contains dogs.
The Evolution of Image Classification
Image classification is a computer vision discipline that spans several decades. The early works of Lawrence Roberts in 1963 were believed to be the starting point of modern image classifiers in neural networks, where he described the processes of visualizing 3D structures from 2D images. In 1966, MIT researchers experimented with feature extraction and segmentation but bore little results.
The 1980s witnessed a British neuroscientist, David Marr, introducing a framework that represents high-level visual data as breakdowns of basic shapes. During these years, a Japanese researcher presented a pioneering convolutional network, Neocognitron, capable of detecting patterns amidst positional variations. But such efforts went through significant changes decades later.
Previous presumptions in image classification developments were discarded in the late 1990s. Rather than attempting to reconstruct 3D images, researchers pivoted to building image recognition systems focusing on specific immutable features in the object. Since then, image recognition algorithms continued in this direction, with several major breakthroughs along the way.
- In 2007, Imagenet was created as an initiative to provide well-labeled, high-quality visual datasets to train image classification models.
- In 2012, Alexnet became the first convolutional neural network to achieve an impressive 15.3% error rate in the Imagenet challenge.
- By 2015, Alexnet’s error rate decreases to 5%, marking another milestone in the evolution of modern image-learning models.
Convolutional neural networks are now widely used in many image classification systems. Works improving the model for computer vision tasks are still in progress. In 2021, Meta revealed ConVit, a deep learning model combining the convolutional neural network and transformer, which works more flexibly on real world data.
Types of Image Classification Techniques
When developing image classification systems, machine learning engineers use these methods to train or optimize the foundational model.
Supervised Learning
Supervised learning trains the machine learning model to identify visual patterns from a suit of labeled image datasets. During the process, the model learns to associate images with the labels assigned to them. For example, you train a model to classify faces by exposing the model to thousands of labeled pictures showing human faces.
During the training, ML engineers monitor the model’s accuracy when predicting the images. Then, they make the necessary adjustment to ensure the model commits lesser mistakes in subsequent iterations. Once trained, the model uses the stored knowledge to classify new images it has never seen before.
Over the years, several algorithms that support supervised classification have been developed.
- Logistic regression uses probabilistic computations to determine whether an image belongs to a category.
- Support vector machines draw a hyperplane between the nearest training data point with the largest distance. Then, the support vector machine places the image into either category, separated by the hyperplane.
- Decision trees classify an image by evaluating each distinguishable feature to form a firm conclusion.
Unsupervised Learning
Unsupervised learning, as the name implies, trains the machine learning model without using labeled training data. Instead, the model freely analyzes the image datasets to form useful deductions. Because the training data were not labeled, models trained with this method cannot assign tags to images.
However, unsupervised learning can enable a model to recognize similar patterns as it trains with more data. We call this feature clustering, where the model groups common data points together. Clustering helps support unsupervised classification by providing automatically-generated image features.
These are some clustering algorithms commonly used in unsupervised learning.
- K-means creates data clusters around a centroid by repetitively adding and recalculating new data points until it finds the optimal cluster alignment.
- Gaussian Mixture Models populate data clusters with varying representations generated by Gaussian distributions. Compared to K-means, GMM can train a model to identify complex image patterns but requires more computing resources.
Semi-Supervised Learning
Semi-supervised learning combines both supervised and unsupervised methods to train image classification algorithms. In practical applications, training a model with large annotated datasets consumes significant resources. Rather than annotating the entire datasets, ML teams only label a small fraction of them. Then, they feed the model-labeled samples to a supervised algorithm, which learns and assign the remaining images with the correct labels.
The result is a large pool of image datasets, where an unsupervised model labels the majority of them. Data engineers use the entire dataset to train the classifier model in supervised mode. Kili Technology supports semi-supervised learning, which enables organizations to improve labeling performance by up to 50%.
Deep Learning
Deep learning uses artificial neural networks that mimic the human brain’s structure. An artificial neural network consists of multiple hidden layers which hold artificial neurons. When analyzing images, the deep learning model extracts features from the raw data and passes them through the interconnected nodes.
Deep learning models train the same way as basic machine learning models do. They learn to associate images with labels through supervised, unsupervised, or semi-supervised training. What differs is the deep learning model’s ability to extract, analyze and understand complex relationships and representations of image data in a much larger magnitude.
Despite being far more powerful, deep learning models have more parameters, are less interpretable, and take longer to train. This underscores the importance efficient annotation process, which influences the model’s training time and performance.
Binary Classification vs. Multi label classification
Binary classification applies logical comparison to an image and classifies unknown data points into one of two categories. For example, a visual inspection system in a manufacturing plant classifies products as either defective or market-ready after analyzing real-time snapshots. Meanwhile, multi-label classification enables software to append multiple number of classes to a single image. For example, image processing systems powering autonomous vehicles label pedestrians, cars, roads, and buildings on the same visual data.
Image Classification vs. Object Detection
Image classification tags the entire image if a specific object the system needs to identify is present. For example, an image containing cats and dogs will be labeled as cats, regardless of how many and where they are present. On the other hand, object detection is a more granular approach to locating a specific entity in the image. When training a model to detect objects, labelers use tools like bounding boxes, polygons, and keypoints to help the model highlight the boundaries of the respective objects.
Challenges in Image Classification
Engineers must grapple with data uncertainties that might impact performance when training models to classify images. Regardless of how thoroughly you train an image recognition model, there are cases where the model fails to classify the objects correctly. We attribute most discrepancies to these factors.

Intra-class variation
An object might appear different, naturally or by intention, and yet belong to the same class. For example, Siamese and Persian cats have stereotypically different appearances but are cats nonetheless. A more complex intra-class variation example is the challenge of finding similarities when categorizing a 12-seater dining table and a small, round coffee table.
Scale variation
Objects captured in real-life footage might vary in size. For example, a building snapshot taken far away occupies fewer pixels than one taken closer. Hence, the image classification algorithm must be able to interpret both objects precisely despite the varying level of data present in the images.
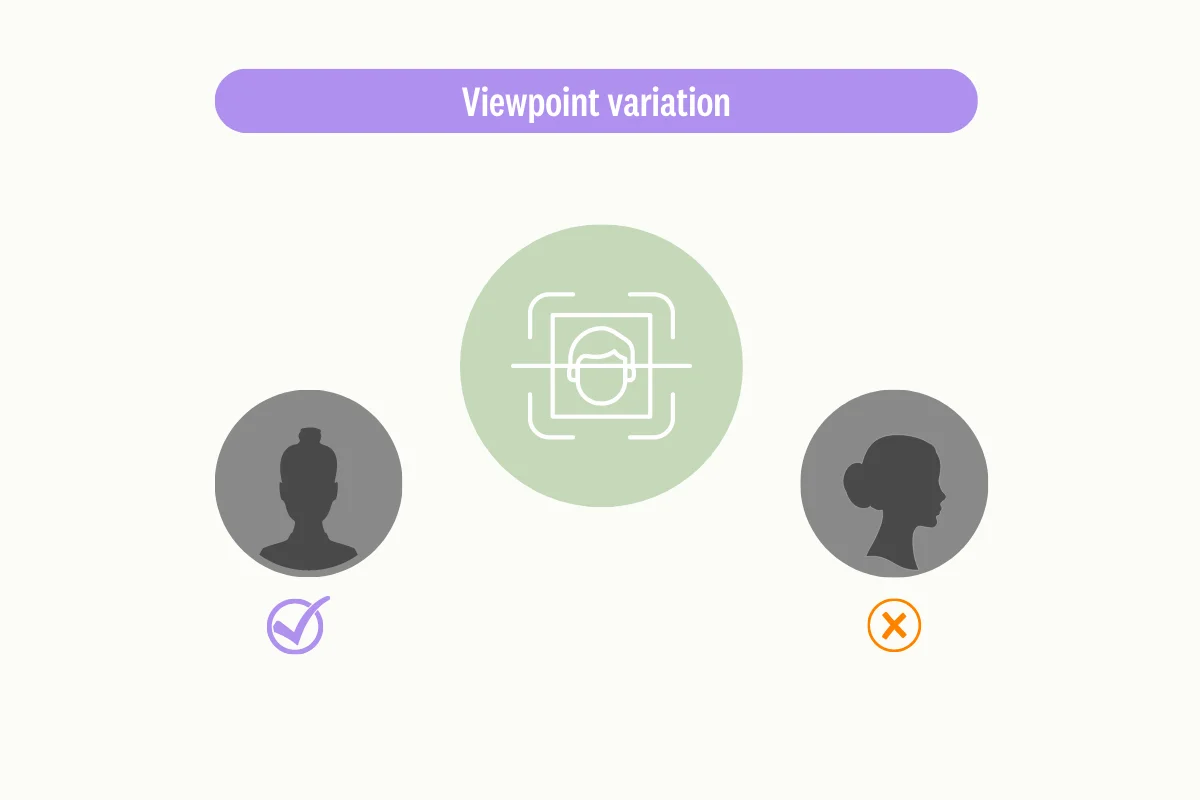
Viewpoint variation
Image classification software might have trouble identifying objects when they’re captured from different angles. For example, it’s challenging to determine the facial feature of an individual if the picture is taken horizontally or at odd angles.

Occlusion
The target object might not appear fully visible in certain snapshots. For example, a dog hiding in a bush with its body and leg obscured. Here, the imaging algorithm might fail to recognize the dog despite its head appearing clearly in the viewpoint.
Illumination
Lighting conditions affect how imaging models interpret objects in the picture. Depending on the intensity, angle, and shadow, the objects project different visual information when extracted from the image. Such disparity in visibility affects the model’s ability to classify the objects as what they are.
Background clutter
Interfering environmental texture and color may affect the model’s performance in identifying the correct object from the image. For example, an imaging model might struggle to identify a red apple placed on a table with a similar color. Likewise, it’s challenging to focus on a specific car amid slow-moving traffic.
Deformation
Objects may take different shapes, pose, or orientation in real-life. For example, a piece of crumpled paper looks physically different from one in perfect condition. Yet, the classifier must label both as ‘paper’ despite one being deformed.
Image Classification and Deep Learning
Image classification has grown by leaps and bounds, particularly since the advancement of deep learning models. We’ve briefly covered how deep learning models differ from conventional models in architecture, performance, and capabilities. Such improvements allow ML teams to overcome or reduce the abovementioned challenges.
A convolutional neural network is one of the most popular deep learning models for image classification. The model, which consists of layers of convolutional filters, can extract important image features such as colors and edges to build a complete hierarchical representation of the object. Moreover, convolutional neural networks reduce the number of parameters it needs to train while maintaining accuracy with dimensionality reduction,
Examples of deep learning models for image classification
Data engineers continue to enhance deep learning models, allowing them to apply different image classification techniques. We share some popular models used for image classification below.
- EfficientNet was introduced in 2019 as an enhanced convolutional neural network capable of extracting and processing complex features while balancing speed and accuracy.
- ResNet50 overcomes the limitations of vanishing gradients in the convolutional network by allowing the model to bypass certain hidden layers. This characteristic, called residual mapping, allows the model to train the deeper layers more efficiently.
- VGG-16 is a highly-accurate convolutional neural network with about 138 million trainable parameters. Its convolutional layer uses a small 3x3 filter to process spatial image data and prevent overfitting.
- ViT stands for Vision Transformer, a deep learning model for image processing based on transformer architecture. Similar to transformers for NLP applications, VIT divides an image into a series of image patches. Then, it predicts the particular class the image belongs to.
- Contrastive Captioner (CoCa) is a modified encoder-decoder model trained with captioning and contrastive loss to enable high-accuracy zero-shot image recognition. CoCa removes cross-attention in the first half of the decoder layers to focus on encoding text representations. Then, it feeds the result into subsequent layers for multimodal image-text learning.
- YOLO is a powerful deep learning model for object detection, but equally capable in image classification tasks. The algorithm is largely popular because of its single-pass prediction.
Watch video
How to choose the best image classification model
Despite the available options, there is no perfect image classification model. Instead, it’s more prudent to question if the model meets your project’s requirements, such as speed, accuracy, and available resources.
A smaller machine learning model bearing fewer parameters is more appropriate for classifying simple, well-defined objects. However, choose a deep learning model like ViT or VGG-16 if you need to extract, detect, and categorize things with complex features.
Complex models require more time, computational power, and datasets to train. But they enable your team to build robust image classification solutions. Before you train a complex model from scratch, ask these questions.
- Is your organization equipped with such capabilities to train a deep learning model from scratch?
- Or do you need to deploy the models on machines with limited processing resources?
- Can a simpler model deliver equivalent performance?
Alternatively, consider using a pre-trained model, which you can fine-tune for specific downstream tasks. Machine learning hubs like TensorFlow, Keras, and PyTorch provide pre-trained models you can download to build image processing solutions. The tutorials, resources, and support they provide will also be helpful.
If you want to learn more about image annotation pricing, we have an article here.
Applications of Image Classification
Image classification technologies have revolutionized various industries. It augments human personnel, enables sophisticated technologies, and helps organizations reduce costs. These are examples of practical applications of image classification tasks in real-life scenarios.
Medical and Healthcare
Advanced medical classification techniques prove helpful in aiding medical professionals in diagnosing specific diseases. For example, doctors use computer-aided imaging systems to detect malignant tumors, fractures, and skin conditions. According to a study, deep learning imaging algorithms are comparable, or in some cases, outperform human dermatologists when classifying skin cancer.
Manufacturing
Image classification solutions allow manufacturers to improve product quality by automatically detecting defects. A case in point is a global manufacturing company that partnered with Kili Technology to train an AI model for defect detection. This model, trained with accurately labeled images, was able to detect thin cracks and scratches that were often missed during manual inspections. The implementation of this AI-driven defect detection system resulted in a 25% cost saving due to preventive defect detection, doubled the speed of building AI training datasets through online learning, and required 30% fewer data to achieve high accuracy.
Security
Security and law enforcement officers have turned to facial analysis to provide real-time identifications for a person of interest. With deep learning models, they can accurately predict a person’s gender, age, and profile to mitigate potential security threats. When applied in an airport, facial recognitions with advanced image classification algorithms reduce passenger boarding time by 75% without compromising security.
Agriculture
Agricultural practices also receive a boost from image processing systems. With convolutional neural networks, such systems can monitor crop growth, detect pest infestation, and irrigate farms strategically. NatureSweet analyzes aerial-captured farm images with a suitable classification technique for signs of infestations, increasing its yield by 2% to 4%.
Autonomous vehicles
Image classification technologies are vital in the development of self-driving cars. Autonomous vehicle manufacturers train deep learning models to identify objects from the network of cameras, classify them in real time, and enable the vehicle to steer clear of obstacles. Tesla, the leader in this market segment, took 70,000 GPU hours to train a combination of 48 neural networks.
Future Trends in Image Classification and Computer Vision
Computer vision technologies, driven by the continuous enhancement of deep learning models, will propel image classification usage in more diverse applications. According to Gartner, the world has passed its peak of inflated expectations for emerging technologies like AI. This means that industries will ramp up the pace in adopting machine learning algorithms for more practical downstream use cases.
Major cloud infrastructure providers will broaden their services to enable organizations to deploy, integrate and scale machine learning models more effortlessly. Lightweight imaging models will power use cases in edge devices with limited computational powers. For example, mobile phones can run advanced mixed-reality apps with resource-friendly imaging models.
Deep learning models, like convolutional neural networks and transformers, will be pivotal in addressing business needs for image processing systems. Generative artificial intelligence, which surprises the business community, offers new possibilities to computer vision systems. Already, we’re seeing software capable of augmenting an original snapshot with relevant AI-generated background by using a suitable classification technique.
However, deep learning models are only as accurate as the data they were trained on. Without a properly-labeled dataset, your computer vision system might not perform to its capabilities. So, there is a growing awareness of data annotation tools like Kili Technology and their role in training deep learning algorithms.
Conclusion
Image classification is a critical computer vision task that forms the basis of complex AI-assisted imaging capabilities. While it operates with the simple principle of tagging an image with the correct label, the underlying algorithm has significantly evolved. Today, deep learning methods help machine learning engineers implement image classification for real-life applications and mitigate known challenges.
We’ve shared how image classification will continue transforming businesses in various sectors and why good-quality datasets are crucial to successful deployment.
Learn more about image classification programming with machine learning here.
Frequently asked questions:
What is the difference between image classification and image segmentation?
Image classification labels the entire image according to the detected category. Meanwhile, image segmentation labels each pixel that forms the particular object. For example, you categorize a picture as ‘animal’, but use segmentation tools to highlight pixels where the animal is located.
What are the state-of-the-art models that I can use for image classification?
YOLO, EfficientNet, and ViT are some of the most advanced models machine learning teams use to classify images.
How can I improve the accuracy of my image classification model?
There are several ways to make your own image classifier more efficient. Using a complex model with more layers might improve its ability to extract finer features. Techniques like regularization prevent overfitting from impacting model performance. Meanwhile, some teams use data augmentation to expand the training samples.
What are the factors that affect the accuracy of image classification models?
Image classification models might be affected by their complexity, the datasets they trained on, and how they are tuned. Using pre-trained models that are field-proven and applying proper evaluation also improves the classifier’s performance.
Does Kili Technology provide image classification tools?
Yes. Kili Technology provides several features that allow you to label images according to their classes. For example, you can use bounding boxes, semantic segmentation, and pose estimation tools to annotate images.
Can I use image classification models with Kili Technology?
Yes. Kili Technology allows you to create high-quality training datasets, which you can use to train image classification models. You can export the labeled data into formats supported by popular deep learning models, including JSON, YOLO, and PASCAL VOC.
Learn More
For an in-depth understanding of reliable AI, and the role Data-Centric AI has in it, download our ebook and access the 8 key benefits of a data-centric approach to AI

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
