
.png)

_logo%201.svg)


AI Summary
Introduction
Unlike traditional software development where your code quality determines the output of a program, in data analysis and artificial intelligence, the quality of the model depends on how you label the data.
If your data is properly labeled, it results in good quality output, while improperly labeled data results in bad output.
It is important to put proper data labeling into consideration while labeling data, a mistake or misunderstanding in data annotation can lead to a re-annotate of all data, and given the stress involved in data annotation, I believe this isn't something you will love to go through.
If the project isn't understood by the annotator before embarking on it or there isn't enough supervision to spot mistakes during annotation, this can cost a lot of hours in re-annotating the data, hence the importance of this topic.
What may go wrong while labeling data differs for different data types, knowing these pitfalls and making a conscious effort to avoid them can help you to produce high-quality data. The following concrete examples will be illustrated with image annotations.
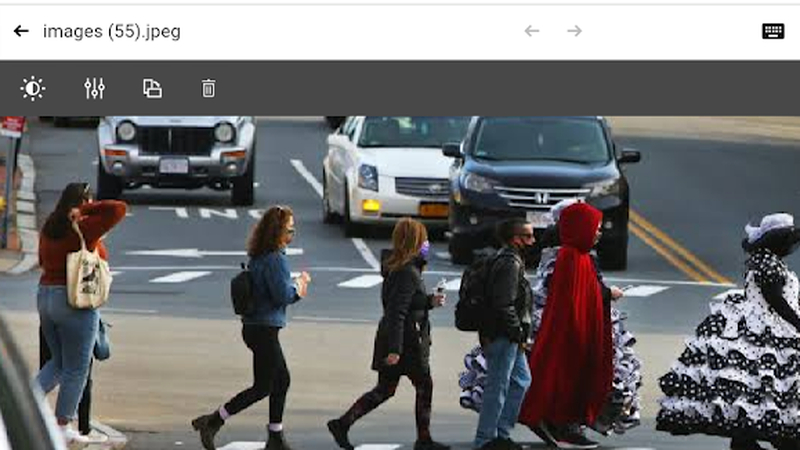
An example is if we are to build a model using Kili Technology, and we are to draw a bounding box around every pedestrian in a traffic, the following can go wrong:
Kili Technology Image annotation tool in action
Misinterpretation of instruction
Instead of drawing a bounding box around a pedestrian, the annotator may draw it around multiple pedestrians.
Annotating multiple objects
To avoid this error, It is the job of the annotation project manager to spend time thinking about clear and exhaustive instructions. This is thinking that has to be done upstream of the annotation phase not to have bad surprises.
It is also recommended that the annotator double-checks the instruction to have a good understanding of their duty, in most cases, the instruction is to annotate a single object, this is because multiple bounding cannot produce an effective model.
Occlusion Error
Instead of annotating only the visible part of a pedestrian, the annotator may place a bounding box around the expected size of a pedestrian.
Labelling unseen parts
Occlusion error occurs due to the annotator expectations, an annotator might decide to bound the expected size of a pedestrian, based on general knowledge.
Another reason why this error can occur is if the object is not clear to vision, an annotator can easily miss the unseen parts and go ahead to bound it.
To avoid this error, the project manager must establish a clear communication method between the team, this ensures that annotators have a clear understanding of how the project must be handled.
Kili platform provides you with several methods to collaborate with your team and ensures quality, this includes the integration of consensus, honeypot or gold standard, instructions, questions and issues, etc which aids active participation, and therefore, occlusion error can be avoided.
An annotator should also confirm that every part of an object is visible before bounding it, every partially-visible object should be discarded.
Missing a label
The annotator may fail to place a label around one or more pedestrians.
This error usually occurs if the annotator isn't observant enough, or they are in a hurry, they can miss vital details such as a useful object, this error should be avoided as well as every other error because they can be tedious to rectify, in most cases, the process of data-labeling needs to be restarted.
This error can equally be avoided through effective communication and collaboration methods, the project manager can also set up a review process whereby the annotator needs to peer-review their works for quality before final submission, if this is implemented, they can easily spot an error in the data-set. The project review option is available to Kili Platform users.
It is recommended that the annotator have a good observation of the dataset before submitting the task, patience is also an important skill that a good annotator must possess, with patience they can always spot every error that may cause a waste of time.
Unfit labeling
This is another common error associated with image annotation, the bounding box may not properly fit a pedestrian.
Unfit annotation
This can occur if the annotator isn't careful while annotating, the box may be looser around the object or even tighter, this doesn't give a true representation of the object, therefore, it results in false data that can negatively impact the output.
This can be costly to the project manager because such data cannot be used, to prevent this, the project manager can assign the task to two or more annotators, then set up a consensus on what is the best annotation for each image, the annotations with 100% consensus can then be chosen and used to train the model.
Experience equally plays an important role in this issue, therefore, it is the duty of the project manager to select an experienced workforce type that can deliver the task based on experience to produce accurate data.
The annotator can also pay lots of attention while bounding, they should be careful not to make the bounding too loose or too tight.
Annotator bias
An annotator may be biased in labeling if he doesn't have a good knowledge of the data or if he has a different opinion, this can result in an ineffective result.
An example of such an occurrence is if the annotator, being English, is asked to annotate biscuits from a data set, to him, a biscuit is a buttery flaky baked bread, while to an American, it is a Cookie. If bread and cookies are contained in the data-set, the annotator may annotate only bread, ignoring cookies even though what is expected of him might be to annotate cookies.
Errors from biased opinions can be costly, data models are usually created to solve a problem or meet a need, but if the data used in building this model isn't properly labeled as a result of a biased view from the annotator, the result is as good as "Useless", and there is no other way to rectify this but to begin the data-labeling process over again.
To avoid this, it is recommended that an annotator has a clear knowledge of whatever data is being labeled, the supervisor can indicate which data type is right for the particular model and which isn't useful, this can help the annotator in deciding what data type to bind instead of relying on their knowledge.
A good approach is to use the instruction option provided by Kili.
Learn more!
Discover how training data can make or break your AI projects, and how to implement the Data Centric AI philosophy in your ML projects.
6. Adding New entity types during a Project
During annotation, an annotator may realize that some unanticipated tags are required in the label, realizing this, they will add those omitted tags, but this can cause Jeopardy.
For example, I was classifying vehicles, and after classifying some bicycles under the motorcycle tag, I realised I need a separate tag for bicycles.
Therefore, I added the bicycle tag.
The result: The previous annotated objects lack the new tag, and this results in inconsistency in the model output. To get a better result, I re-annotated the objects.
This error can be avoided if the project manager takes their time to prepare an exhaustive list of labels, the project manager should be an expert of the subject domain, and if they are not, they can consult a domain expert to help in curating labels. Collaboration with annotators is also a good approach.
7. Overwhelming tag lists
Having an overwhelming list of tags can easily slow down your annotator and leads to an overall poor result.
For example, having annotators choose from a long list of tags can result in a biased distribution of tags, this is because of the VDSM analysis, users will usually notice contents that are immediately before them.
To avoid this, it is recommended that you group your tags under broad topics as much as possible, this will reduce the time needed for your model to get to production, and save the cost of labeling.
8. Using the Wrong labeling platform
Every error that has been stated thus far occurs more often due to the quality and capacity of the platform being used for annotation.
Most data being processed today are big data, given the increasing complexity of data analysis. but most tools are built in the earlier days of data analysis and aren't effective for structuring big data, they also lack modern functions that are essential for data labeling.
Things to consider while choosing the right platform include platforms that guarantee privacy and the right access by the workforce, affordable and flexible back-end requirements and an attractive UI/UX.
Kili technology is a modern and powerful labeling platform that satisfies all the requirements previously listed and can handle any data-labeling project.
We have advanced tools directly integrated into our platform to make data labeling and annotation seamless for both the annotator and supervisor, you can check our Documentation to learn more about what we can offer.
Using such effective platforms can help prevent most of the pitfalls associated with data annotation and also save you so many costs.
Conclusion
Data annotation is an important step for data modeling, but mistakes in data annotation can not only destroy the expected output but also lead to a loss of time and revenue. We have stated some common errors while labeling images and how to rectify them by taking preventive measures and using smart tools.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

