
.png)

_logo%201.svg)


AI Summary
The Impact of GenAI on Industries
Generative artificial intelligence (GenAI) has revolutionized various sectors by significantly boosting productivity and efficiency. Generative AI uses artificial neural networks to predict and generate new content in response to prompts.
Source: Google's "The Economic Impact of Generative AI" report

As highlighted in a recent study from Google, generative AI models like large language models have benefited several sectors.
- It enabled call center employees to resolve more issues per hour with higher customer satisfaction and lower turnover rates.
- Management consultants have seen a 25% increase in task completion speed with 40% higher quality outputs.
- Coders benefit from AI pair programmers that enhance their programming speed by 56%, while professional writers complete their tasks 37% faster with improved quality thanks to AI chatbots.
- Even in the medical field, physicians can complete daily patient notes 83% faster through automated transcription and summarization.
Generative AI tools and applications vary across sectors and have been used as chatbots, financial data analyzers, and even assistants for content creation and drug discovery platforms. These tools increase productivity, reduce costs, and improve customer satisfaction.
These advancements underscore the transformative potential of GenAI across different occupations, driving substantial productivity gains and improved performance.
And while the impact of generative AI models on individual productivity and efficiency is undeniable, its role in enhancing data processes is equally significant. Central to the success of any GenAI application is the quality of the data on which it is trained.
This brings us to the crucial relationship between GenAI and data labeling. Understanding how generative AI models aid in building, evaluating, and refining datasets reveals the broader implications of its integration into data-centric workflows.
Master LLM Alignment with Kili Technology.
At Kili Technology, we specialise in LLM alignment to ensure your models deliver precise and reliable results. Our expert workforce and advanced project managers streamline the alignment process, providing you with the highest quality datasets tailored to your specific needs.

Start a POC
Generative AI and Data
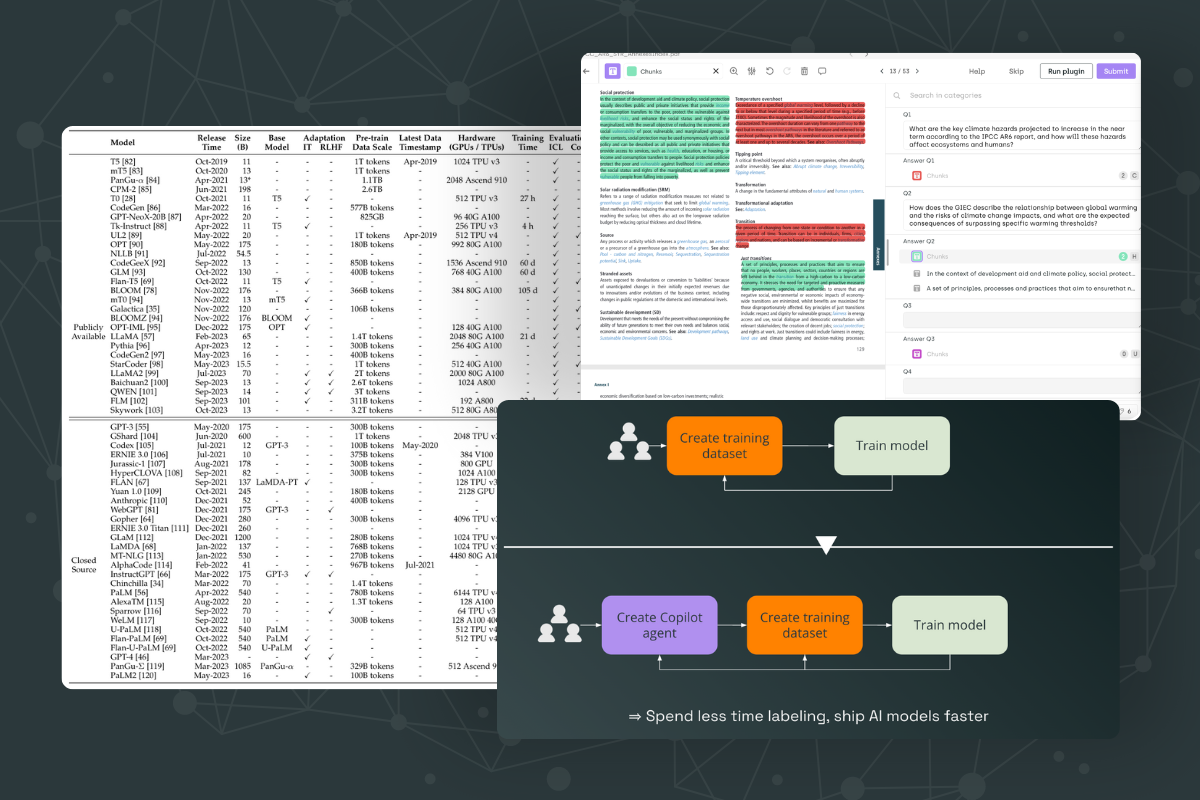
Dataset scale in different large language models. Source: A Survey of Large Language Models
The Synergistic Relationship
The relationship between generative models and data is symbiotic and foundational. Generative AI models, which include some of the most sophisticated machine learning models like GPT (Generative Pre-trained Transformers), are built upon advanced neural network architecture and thrive on vast amounts of high-quality data. This training data serves as the fuel that powers their learning and generative capabilities.
Accelerated Training Data Building
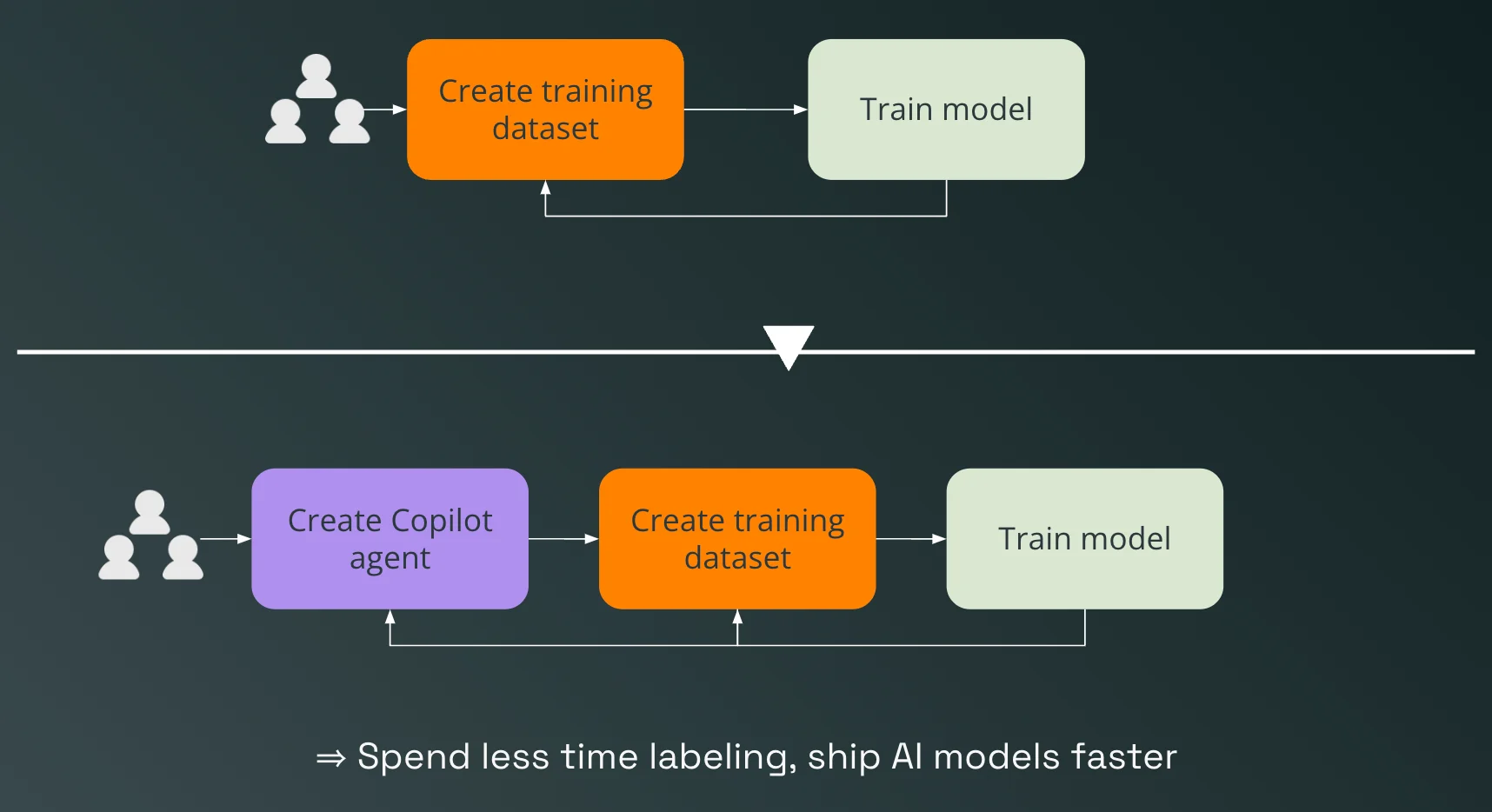
GenAI can significantly expedite the process of building datasets. Traditionally, creating a high-quality dataset involves extensive manual effort where human annotators label large volumes of data. This process is not only time-consuming but also prone to inconsistencies and errors. With GenAI, the dataset creation process can be automated to a large extent.
For instance, a labeling copilot powered by a large language model can pre-label data to build a training dataset for a natural language processing model faster. This preliminary layer of annotation can then be refined by human experts. This collaboration between humans and AI drastically reduces the time required to build comprehensive datasets, ensuring quicker turnarounds and more efficient data management. We'll discuss more in the later part of this article.
High-Quality Datasets for GenAI Training, Evaluation, and Fine-Tuning
The quality of the datasets used for post-training and evaluation is also vital in maximizing the effectiveness of GenAI models. High-quality datasets enable accurate performance assessment and fine-tuning of models to meet specific needs. During the evaluation phase, a separate GenAI model can assist human experts in identifying and correcting mislabeled data, thereby enhancing the overall benchmark dataset quality. This continuous feedback loop helps maintain the integrity and reliability of the data, which is crucial for the consistent performance of GenAI applications.
Challenges in the Age of GenAI
Integrating Generative AI into various industries has undoubtedly brought significant advancements. However, the arrival of GenAI comes with challenges that must be addressed to harness its potential fully. These challenges span across developing benchmarks, discovering the optimal data mix, and allocating resources effectively.
Developing Sophisticated Benchmarks for Generative AI Models
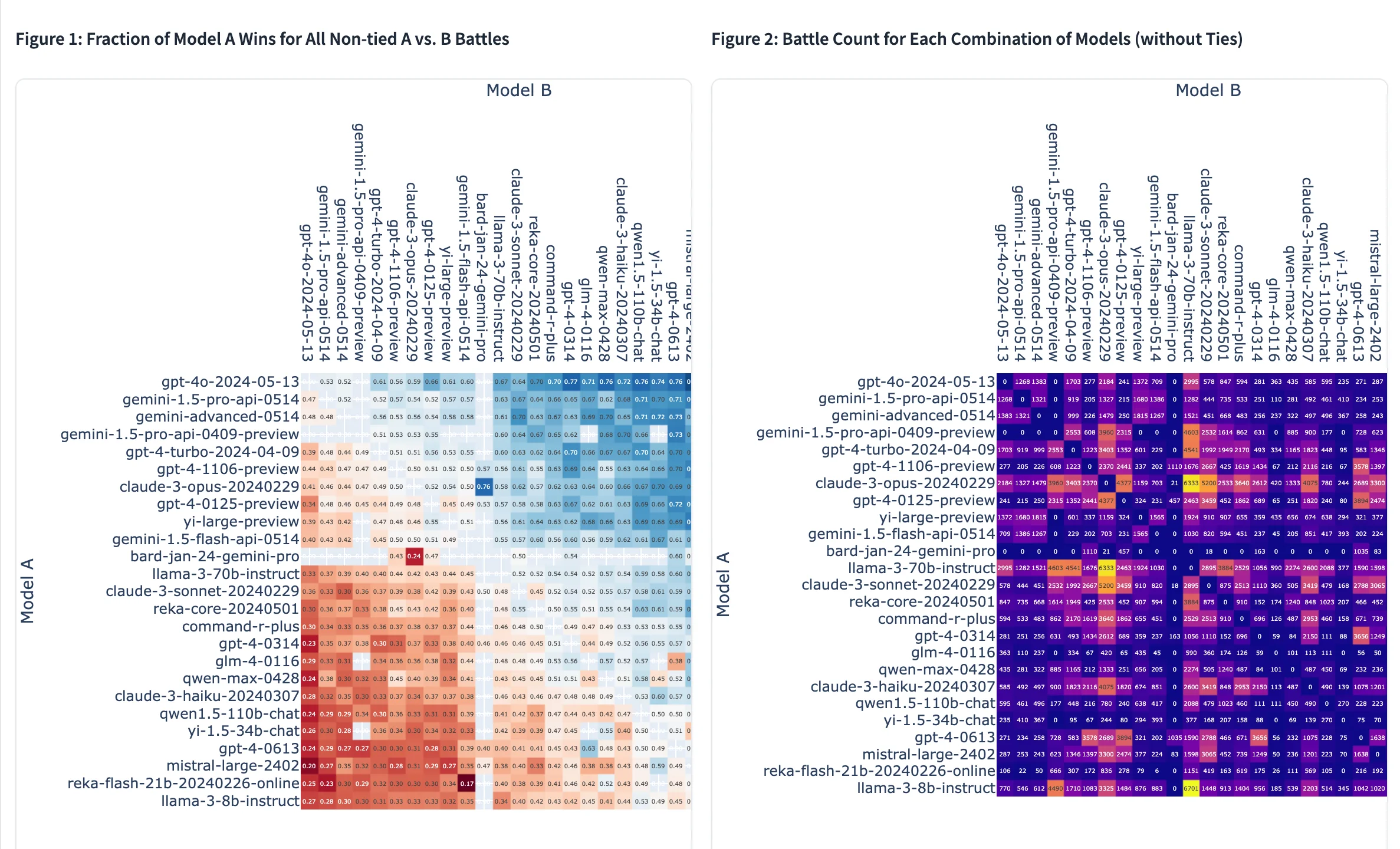
LMSys Chatbot Arena comparisons. Source: LMSys Chatbot Arena
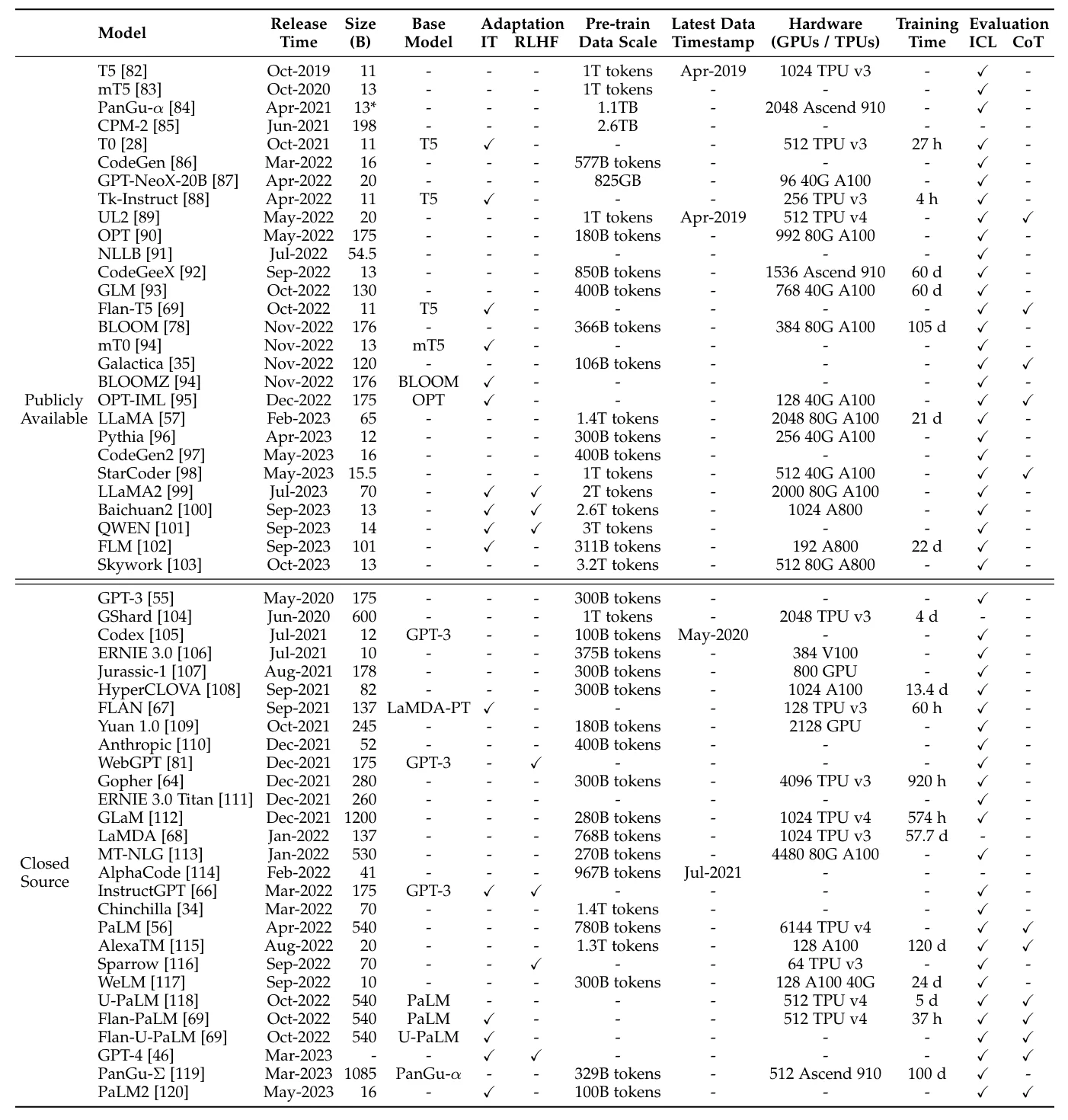
One of the primary challenges in the GenAI landscape is the need for more sophisticated benchmarks. Traditional benchmarks may not adequately measure the performance of GenAI models, especially when these models are assigned to specific tasks and domains. Developing benchmarks tailored to GenAI's unique capabilities and applications is crucial. These benchmarks must consider the nuances of generative tasks, such as creativity, coherence, and context relevance, which are often difficult to quantify.
Furthermore, benchmarks should be dynamic and evolve alongside advancements in GenAI. This requires continuous research and collaboration among AI practitioners to establish standards that accurately reflect the performance and reliability of GenAI systems in real-world scenarios.
In response to this challenge, new methods for evaluating large language models have emerged, such as the LMSys Chatbot Arena.
Discovering the Right Data Mix
A Data Optimal Regime approach. Source: Microsoft Phi-3 Technical Paper

Another significant challenge is discovering the right data mix to build new GenAI models or fine-tune existing ones. Today, LLM builders are researching new approaches to curate the data they feed to LLMs to unlock more value efficiently.
The quality, diversity, and relevance of the data are critical factors determining the effectiveness of GenAI models. Identifying the optimal data mix involves carefully balancing various types of data, including structured, unstructured, labeled, and unlabeled data.
Moreover, different tasks and domains may require different data compositions. For instance, a GenAI model designed for medical applications will need a vastly different dataset than a model intended for creative writing. This necessitates a deep understanding of each domain's specific requirements and the ability to curate datasets that meet these needs. The challenge lies in gathering diverse and high-quality data and ensuring that the data is representative and free from biases.
Resource Allocation for High-Quality Datasets
Building larger and higher-quality datasets is an essential yet resource-intensive process. Creating such datasets demands significant time, effort, and financial investment. Organizations must allocate sufficient resources to data collection, cleaning, annotation, and validation processes to maintain high standards.
Additionally, the iterative nature of GenAI development means that datasets need to be continuously updated and expanded. This ongoing requirement can strain resources, particularly for smaller organizations or those with limited budgets. Efficient resource allocation strategies, such as leveraging automated tools and outsourcing certain tasks, can help mitigate some of these challenges. However, ensuring consistent data quality and relevance remains a formidable task.
Addressing Challenges with GenAI and Data Labeling Solutions
Organizations must overcome several significant challenges as they strive to maximize the benefits of Generative AI (GenAI). These include developing sophisticated benchmarks, discovering the optimal data mix for building and fine-tuning models, and allocating resources effectively to build larger and higher-quality datasets. A comprehensive data labeling company's solutions can address these challenges, leveraging GenAI and advanced tools to streamline processes and ensure high standards of data quality.
Leveraging GenAI for Faster Dataset Creation
GenAI can be integrated as a labeling copilot to build evaluation and fine-tuning datasets more efficiently. However, the right interface for the tool must be built as well. This approach involves iterating on the prompt of a labeling copilot, comparing performance on a benchmark dataset, and then scaling to label the rest of the dataset.
Automate Labeling with a Copilot:
Subject Matter Experts (SMEs) collaborate with GenAI to create a training set using an LLM agent. They can edit copilot prompts, review the performance, and iterate on prompts to refine the dataset.
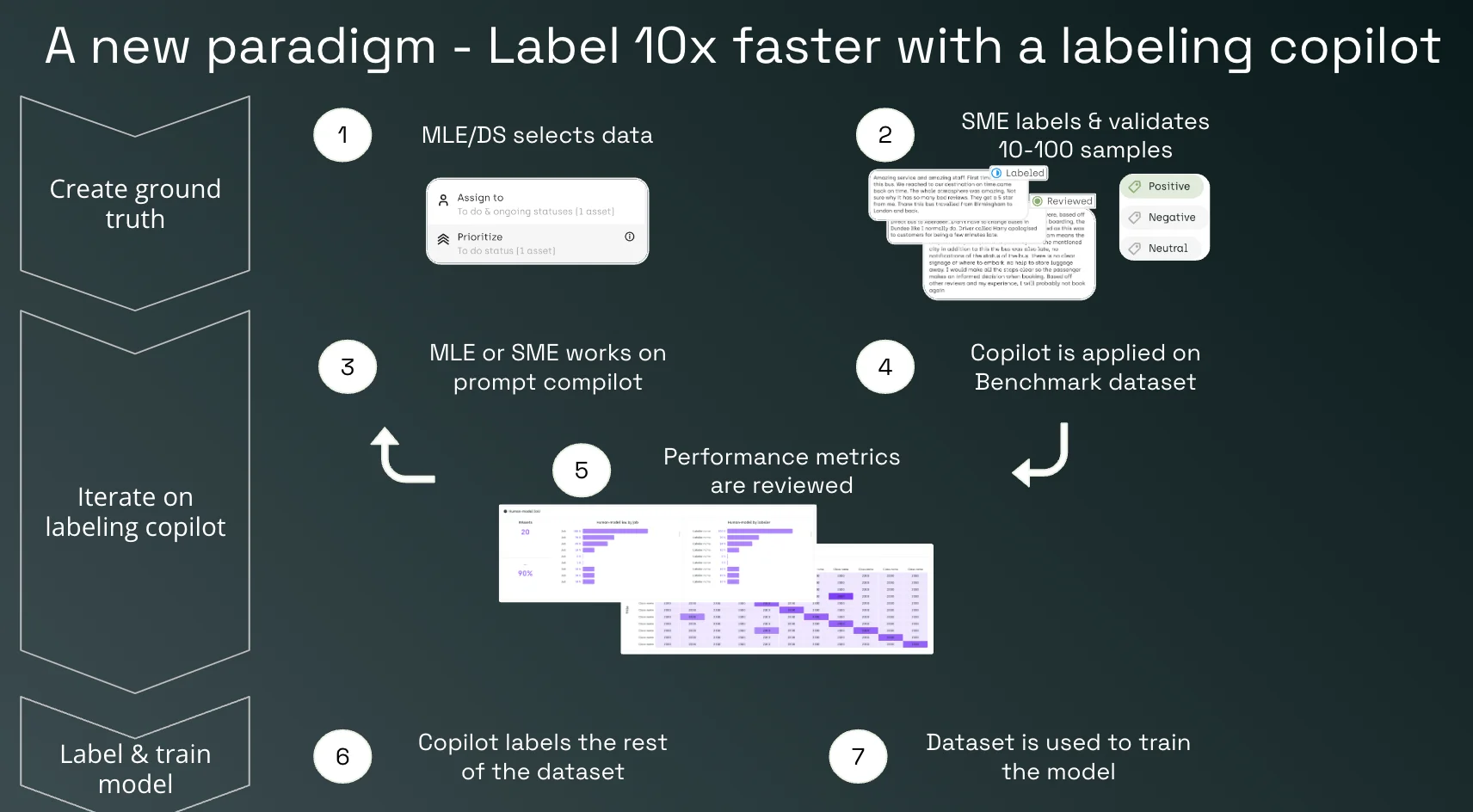
This method significantly reduces the time and effort required for manual labeling, allowing for quicker and more accurate dataset creation.
Building Sophisticated UIs and Tools for Benchmarking and Fine-Tuning
Fine-tuning and evaluating large language models to meet specific requirements necessitates a fully customizable labeling UI. This allows for a more efficient and targeted dataset creation process tailored to each project's unique needs. Depending on the purpose and methodology chosen, a customizable UI can significantly enhance the fine-tuning and evaluation workflow.

Pairing customizable UIs with smarter automation:

Incorporating automation into the data labeling process can significantly enhance efficiency and accuracy. For example, one effective approach is to utilize models that automatically flag poor answers generated by Retrieval-Augmented Generation (RAG) and LLM stacks. These flagged responses are then forwarded to human experts for review and correction. This method ensures that only high-quality data is used for training and fine-tuning models without exhausting human effort.
Scaling High-Quality Dataset Creation with Expert Networks and Project Management
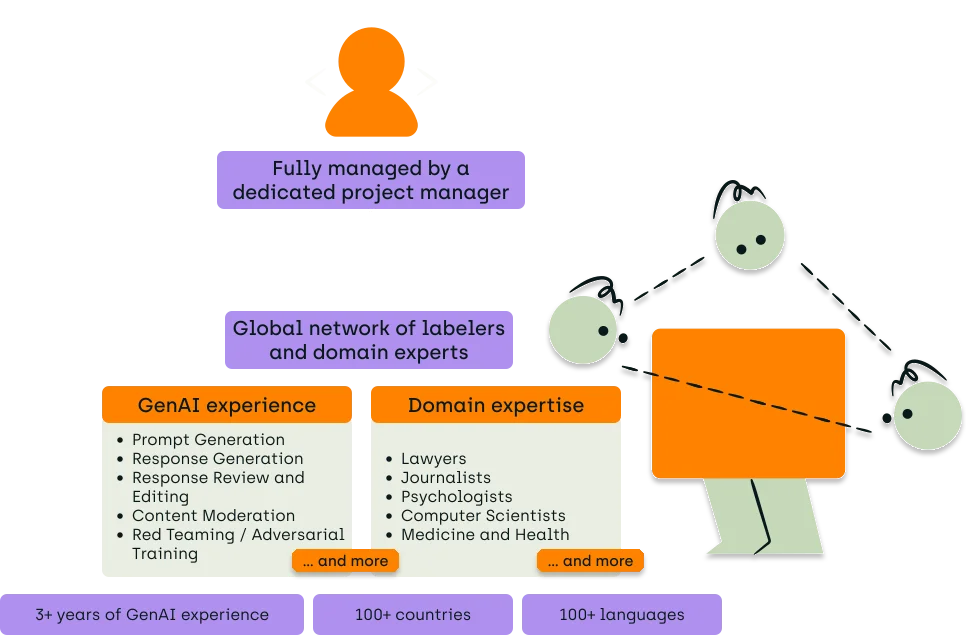
Generative AI (GenAI) requires massive datasets and frequent iterations of these datasets to be effective and valuable.
Automation and highly adaptable tools alone are insufficient to address this need.
A comprehensive approach that includes an easily accessible human alignment team is crucial for better quality assurance, faster scaling, and improved feedback quality. Additionally, expert orchestration of the entire process is essential to manage the complexities involved.
Elevate your AI with Kili Technology's LLM evaluation.
We offer comprehensive LLM evaluation services to help you assess and improve your models efficiently. Our expert workforce, combined with cutting-edge project management capabilities, ensures a thorough evaluation process, providing you with actionable insights to enhance your AI solutions.
Start a POC
Conclusion
In the article, we discuss the transformative impact of Generative AI (GenAI) across various industries, highlighting significant productivity and efficiency gains. We emphasize the critical role of high-quality datasets in training and fine-tuning GenAI models. We identify challenges such as developing sophisticated benchmarks, discovering the optimal data mix, and effective resource allocation as key obstacles in building and maintaining these datasets.
To address these challenges, we propose leveraging GenAI for faster dataset creation, integrating automation for flagging common mistakes, and employing a human alignment team for quality assurance and iterative improvements. Additionally, we outline the importance of scalable human expertise and expert orchestration to manage the complexities involved in data labeling processes.
If you're looking to overcome the challenges of building custom high-quality datasets for Generative AI, Kili Technology's expert team can help. Reach out to discuss how our solutions can streamline your data processes and enhance efficiency. Contact us today to learn more.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

