
.png)


_logo%201.svg)


AI Summary
This article is based on our recent webinar "Building Geospatial Datasets at Scale: Challenges and Best Practices," featuring a collaboration between Kili Technology and Enabled Intelligence. The webinar explored critical challenges organizations face when scaling annotation projects while maintaining quality standards in geospatial AI applications.
Enabled Intelligence brings proven expertise in geospatial data labeling across defense, space, climate research, logistics, and mining industries, working with customers including Maxar, Black Sky, Capella Space, Pixxel, SKYFI, ICEYE, URSA Space, the National Geospatial-Intelligence Agency (NGA), and NOAA. With an extensive portfolio of pre-labeled geospatial datasets and expertise in coordinating expert teams, Enabled Intelligence has established itself as a leader in building highly accurate training data for mission-critical geospatial AI systems.
It's precisely this depth of experience that made Enabled Intelligence a natural partner for exploring the technical challenges of geospatial AI data preparation. Geospatial AI applications demand training datasets that account for unique complexities not found in standard computer vision tasks. Unlike conventional image classification or object detection, geospatial data labeling requires navigating the intersection of geographic information systems and machine learning—two domains with fundamentally different data representations and workflows.
Grab the replay and materials.
Core Technical Challenges in Geospatial AI Data Preparation
Geospace vs. Pixel Space Paradigm
The most fundamental challenge in geospatial AI lies in the conceptual divide between geospace and pixel space. GIS professionals work naturally in geospace, where data includes rich metadata such as coordinate reference systems, ground sample distances, and geographic projections. This geospatial context provides essential information for accurate labeling—annotators can leverage coordinate data, measure real-world distances, and understand spatial relationships between objects.
Computer vision models, however, operate exclusively in pixel space. They process images as arrays of pixel values without inherent understanding of geographic coordinates or real-world measurements. This creates a critical conversion challenge: training data must be prepared in pixel space while preserving the geographic accuracy that geospace provides.
Data pipelines must account for these format transformations. Native geospatial formats like GeoTIFF and KML files contain the metadata necessary for accurate labeling, but must ultimately be converted to standard image formats (PNG, JPEG) for model training. Pre-processing and post-processing techniques become essential to maintain spatial accuracy throughout this conversion process.
Data Variation Impacts

Geospatial imagery introduces multiple sources of variation that directly impact AI model performance and computational costs:
Resolution and Ground Sample Distance: Satellite imagery can range from sub-meter to several meters per pixel. Models trained on high-resolution data may fail when applied to lower-resolution sources, and vice versa. This variation affects both labeling precision and model generalization.
Sensor and Provider Differences: Different satellite sensors capture imagery with varying spectral characteristics, color profiles, and geometric properties. Data from commercial providers like Maxar or Planet Labs may require different preprocessing approaches compared to government satellite systems.
Nadir and Look Angles: Satellite captures taken at different angles relative to Earth's surface introduce geometric distortions that affect object appearance. Objects may appear stretched or foreshortened depending on the viewing angle, requiring training data that represents this variation.
Environmental and Biome Variations: The same object type appears differently across desert, urban, forested, or arctic environments. Models must be trained on sufficient examples across these environmental contexts to achieve robust performance.
Satellite and Geospatial Imagery Types
Understanding the characteristics of different imagery types is essential for developing appropriate labeling strategies:
Electro Optical: Standard visible spectrum satellite imagery similar to conventional photography. Provides natural color representation but is limited by weather conditions and daylight availability.
SAR (Synthetic Aperture Radar): Radar-based imaging that penetrates clouds and operates in all weather conditions. SAR imagery appears grayscale and requires specialized interpretation skills, as objects are characterized by their radar reflection properties rather than visual appearance.
Hyperspectral: Multi-band imagery capturing dozens or hundreds of spectral channels beyond visible light. Enables material identification and classification based on spectral signatures, particularly valuable for vegetation analysis and mineral detection.
Infrared/Thermal: Captures heat signatures and thermal emissions. Useful for detecting temperature variations, active machinery, or environmental monitoring applications.
Full Motion Video: Continuous video streams from aerial platforms providing temporal context and movement patterns. Requires different labeling approaches compared to static imagery.
Off Nadir: Satellite imagery captured at non-vertical angles, providing oblique views that can reveal building heights and 3D structure information not visible in nadir (straight-down) imagery.
Ground Based: Terrestrial perspective imagery that complements satellite views, often used for validation or detailed object characterization.
AI Model Architecture Considerations
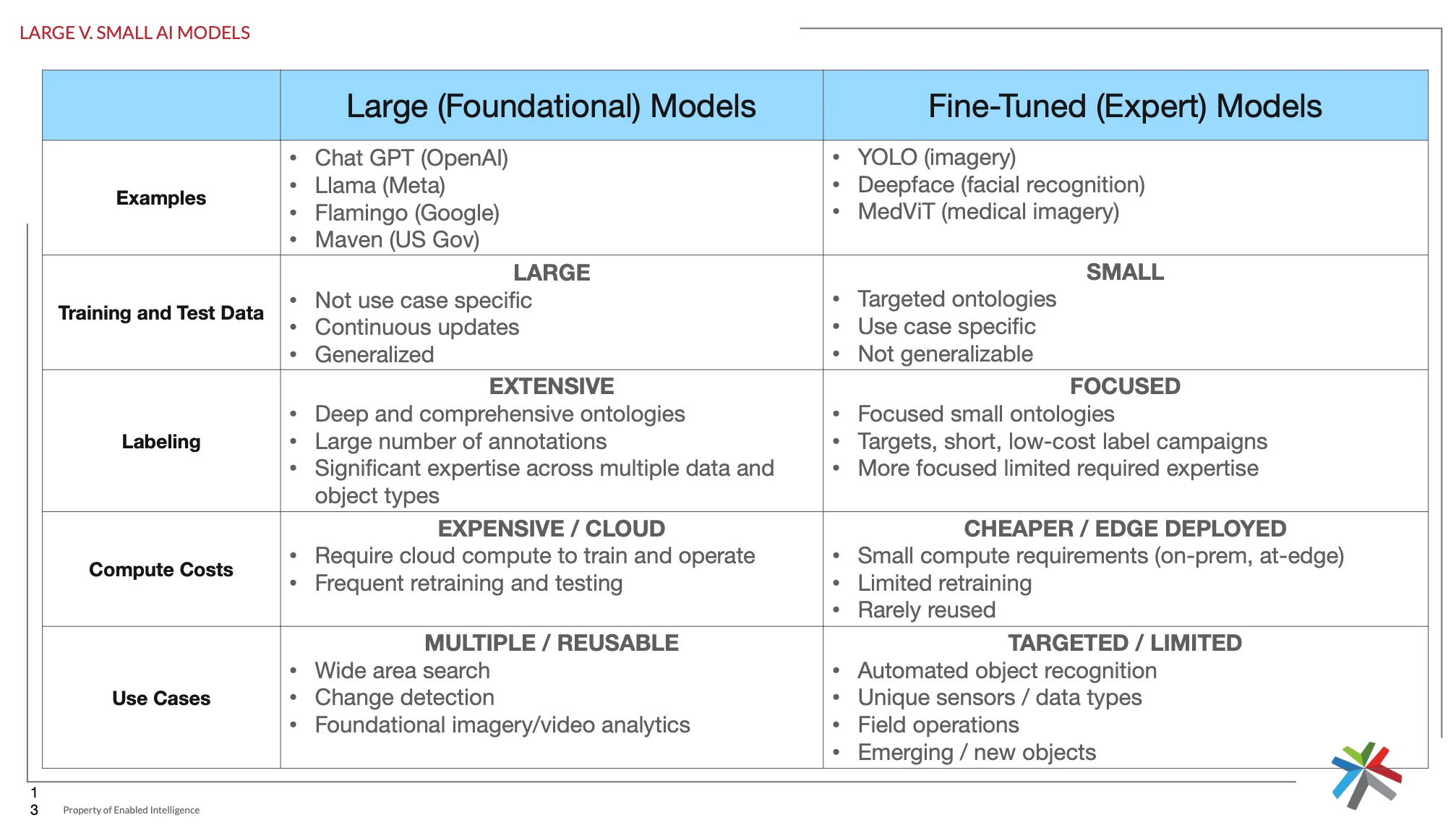
The choice between large foundational models and fine-tuned expert models significantly impacts training data requirements:
Large Foundational Models require extensive, diverse datasets with comprehensive ontologies covering multiple object types and scenarios. These models demand significant computational resources but offer broad applicability across use cases like wide-area search and change detection.
Fine-Tuned Expert Models focus on specific object types or use cases with targeted ontologies. They require smaller, more focused datasets but offer advantages in edge deployment scenarios and specialized applications like automated object recognition for unique sensors.
Technical Tools and Methodologies

Image Processing Approaches
Full Image Labeling: Annotating complete satellite images preserves spatial context and relationships between objects, which proves critical for accurate identification of many geospatial objects. However, large file sizes create challenges for data management and may slow annotation workflows.
Human labelers face additional difficulties when working with full images: navigating large files requires constant zooming between detail and overview levels, leading to slower annotation speeds and potential eye strain. High-resolution satellite images can exceed several gigabytes, causing performance issues in annotation software and requiring significant computational resources on labeler workstations.
Image Chipping: Dividing large images into smaller tiles enables faster per-image labeling and more focused attention on individual objects. However, the loss of spatial context creates significant challenges for human annotators.
Objects that rely on surrounding features for identification—such as distinguishing between similar infrastructure types or identifying partially obscured objects—become much more difficult to label accurately. Large objects spanning multiple chips may be inconsistently labeled across boundaries, and relationships between objects (like aircraft positioned relative to runways) are lost. Annotators may also create "empty" labels for chips containing only portions of objects, leading to fragmented or incomplete annotations.
Human labelers working with chipped imagery often struggle with context-dependent classification decisions. For example, a small building might be correctly identified as a storage facility when viewed alongside nearby industrial infrastructure, but appears ambiguous when isolated in a chip. Similarly, vehicle identification may depend on understanding whether objects are located in civilian or military contexts, information that becomes unavailable in tight crops.
The choice between approaches depends on object density, image size, and the importance of spatial relationships in the target application, balanced against labeler efficiency and the availability of computational resources for handling large files.
Advanced Labeling Techniques

Mensuration: Precise measurement capabilities enable better object characterization by providing real-world dimensions. This technique proves particularly valuable for applications requiring size-based classification or detailed object analysis, such as cargo analysis, defense applications, and infrastructure monitoring.
For example, aircraft identification often relies heavily on dimensional analysis. To the human eye, different aircraft types within the same category—such as large transport aircraft or fighter jets—may appear remarkably similar in satellite imagery, sharing comparable wing configurations, engine placements, and overall profiles.
However, mensuration reveals critical distinguishing characteristics through precise length, wingspan, and width measurements. These dimensional differences, accurately captured through mensuration tools, enable definitive classification that would be impossible through visual assessment alone, particularly when images are captured at varying resolutions or angles where subtle visual features become indistinguishable.
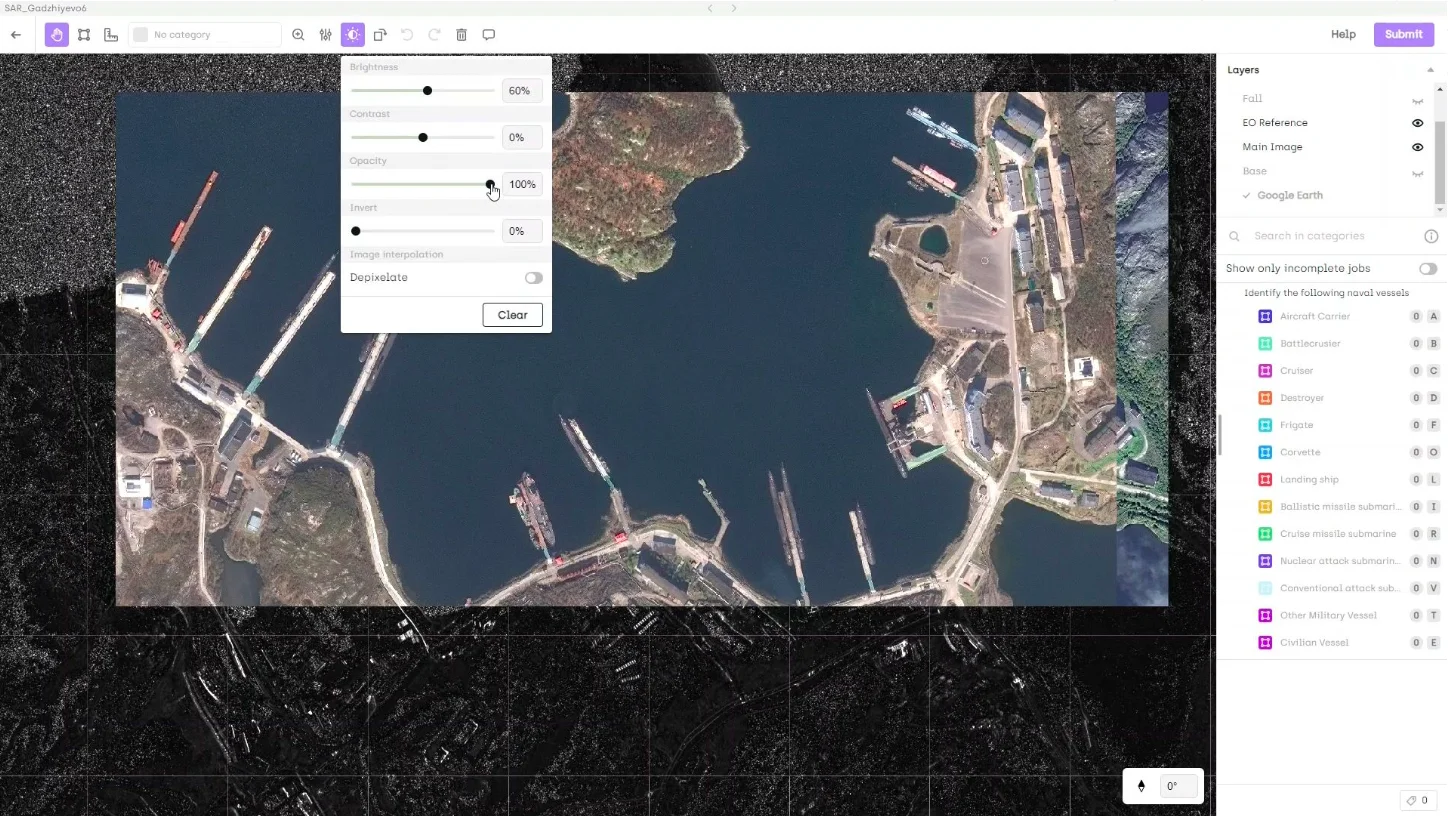
Multi-layer and Multispectral Analysis: Modern annotation platforms like Kili Technology support overlay of multiple data layers—including different spectral bands, reference imagery, and ancillary geographic data—while multispectral integration combines multiple spectral bands to reveal objects or features not visible in standard RGB imagery. For pixel space labeling, this integration provides enhanced discrimination capabilities while maintaining compatibility with computer vision models.
This multi-layer approach proves particularly valuable for human labelers and domain experts who can leverage their specialized knowledge to interpret complex spectral signatures.
For example, vegetation analysis experts can distinguish between healthy and stressed crops by examining near-infrared bands, while geologists can identify mineral compositions through specific spectral responses.
Military analysts can detect camouflaged or partially concealed objects by switching between visible and infrared layers, revealing heat signatures or material properties invisible to standard photography.
Human annotators benefit significantly from the ability to toggle between different spectral combinations in real-time.
Objects that appear ambiguous or entirely absent in RGB imagery—such as underground infrastructure, recently disturbed soil, or synthetic materials—often become clearly defined when viewed in infrared or other spectral bands.
This capability reduces annotation uncertainty and enables more confident labeling decisions, particularly when experts can apply domain-specific knowledge about how different materials and objects appear across the electromagnetic spectrum.
Quality Assurance in Geospatial Labeling
Geospatial applications often require accuracy levels exceeding 95%, making quality assurance workflows critical. Effective QA processes track multiple accuracy metrics:
- False positive and false negative rates specific to each object class
- Misclassification errors between similar object types
- Label alignment accuracy ensuring precise boundary delineation
- Spatial consistency across different imagery types and resolutions
Multi-Stage Review Workflow

A robust multi-stage review workflow demonstrates how these quality standards can be achieved systematically. The process begins with parallel annotation, where multiple annotators independently label the same imagery. This parallel approach immediately identifies areas of uncertainty or disagreement that require further review.
First Review Stage - Automated Consistency Checking: The first review stage employs automated consistency checking through computational comparison of annotations. Key metrics evaluated include Intersection over Union (IoU) measurements to assess boundary alignment precision, object count verification to identify missed or false detections, and object classification agreement rates between annotators. This automated analysis efficiently flags discrepancies without requiring immediate human intervention.
Second Review Stage - Expert Human Analysis: The second review stage involves expert human analysis, where qualified QC analysts examine flagged discrepancies and resolve conflicts between annotators. These analysts bring domain expertise to ambiguous cases and make definitive classification decisions based on established guidelines and contextual knowledge.
Final Review Stage - Quality Validation: The final review stage implements randomized quality validation, where a statistical sample of completed annotations undergoes independent verification. This final check ensures that the overall dataset meets specified accuracy thresholds and identifies any systematic errors that may have propagated through earlier review stages.
These multi-stage processes must balance throughput requirements with accuracy standards while maintaining cost efficiency, requiring careful optimization of review sampling rates and automation thresholds.
Implementation Considerations
Successfully implementing geospatial AI training pipelines requires coordination between domain experts with different specializations. GIS professionals bring essential knowledge of coordinate systems, projection handling, and spatial analysis techniques. Machine learning engineers contribute expertise in model architectures, training procedures, and deployment optimization.
Cross-domain teams benefit from establishing clear protocols for data format conversions, quality metrics, and validation procedures. The complexity of geospatial data demands careful attention to metadata preservation, coordinate system consistency, and spatial accuracy throughout the entire pipeline.
Effective geospatial AI systems require training data that accurately represents the operational environment while meeting the technical constraints of machine learning models. This balance between geographic fidelity and computational efficiency ultimately determines the success of geospatial AI applications across defense, environmental monitoring, infrastructure analysis, and commercial remote sensing applications.
Partner with Kili Technology for Advanced Geospatial Annotation
The challenges and solutions outlined above represent real-world experiences from Enabled Intelligence's extensive geospatial labeling projects.
Kili Technology's geospatial annotation platform has been instrumental in helping Enabled Intelligence build highly accurate geospatial datasets that meet the demanding requirements of their diverse client base across defense, environmental research, and commercial sectors. (Learn about Enabled Intelligence's recent $708 NGA contract win here.)
Ready to elevate your geospatial AI projects? We offer a free 2-week evaluation so you can test our tool at its full capacity with your own dataset. Contact our team today.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

