
.png)

_logo%201.svg)


AI Summary
What is video object detection? How does it work?
Video Object Detection is a computer vision task that involves identifying and tracking objects of interest within a video sequence. Video object detection tasks incorporate temporal information to keep track of the objects across different video sequence frames. The primary objective here is to capture objects' spatial and temporal attributes and analyze the movements of different objects across the video.
There are several steps involved in video object detection, as follows:
- Image Object Detection: Object detection is performed on individual video frames.
- Temporal Information Tracking: Next, to maintain temporal information, techniques such as optical flow and motion estimation are used to predict the positions of the objects in the following frames based on previous frames.
- Object Association: The next task is associating objects detected in the current frame with those in the previous frames using object association algorithms.
- Motion Tracking: Once all the objects are associated, tracking algorithms are used to update the positions and velocities of each object as the video progresses. These algorithms must be robust to object occlusion and abrupt motion changes.
The final output of the system comprises positions and class labels of the detected objects across the video, which is often obtained after several post-processing steps, such as refining the object boundaries and handling the false positive detections.
The importance of video object detection
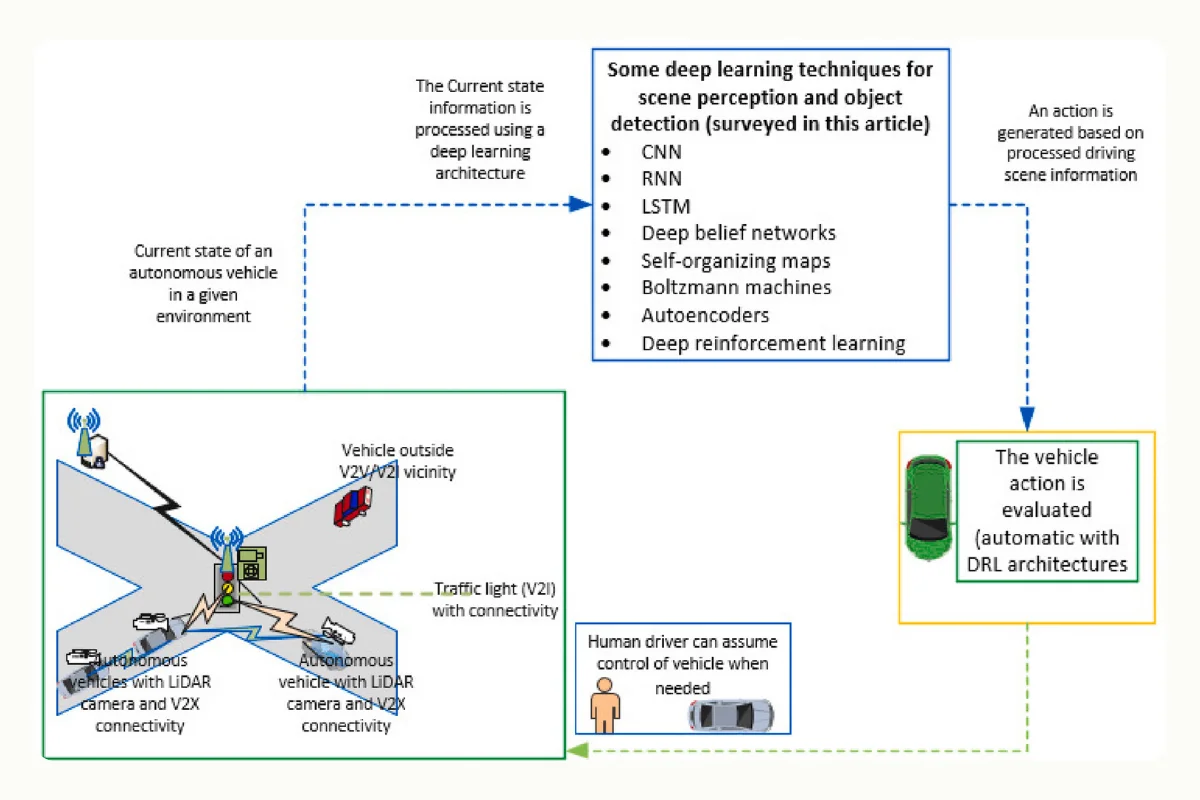
Deep learning applied to scene perception and object detection in self-driving cars. (Source)
The advancement of machine learning and AI research over the past few years has paved the way to build efficient video object detection algorithms that enable AI systems to comprehend and interpret the dynamic visual information in videos. The ability to capture temporal information is crucial for several applications.
- Firstly, in the surveillance domain, video object detection helps identify and track suspicious intruders and activities in real time.
- In autonomous vehicles, video object detection ensures safe navigation by recognizing and tracking vehicles, road signs, pedestrians, and other obstacles.
- Similarly, in robotics, video object detection facilitates the perception of the surrounding environment, enabling robots to interact intelligently within complex spaces.
- In healthcare, this technology assists in analyzing medical imaging data and identifying and tracking anomalies, tumors, and other critical features, thereby contributing to more accurate diagnostics and treatment planning.
- In retail, video object detection helps understand consumer behavior, enabling tracking of customer movements and preferences, leading to improved marketing strategies and personalized customer experiences.
Overall, video object detection algorithms significantly enhance the ability of machine learning and AI systems to interpret and respond to real-world visual information, thus empowering various industries with advanced capabilities for automation and decision-making.
Examples of video object detection models
Video object detection has witnessed a remarkable transformation over the years, primarily driven by advancements in algorithms and techniques. This evolution began with traditional methods such as background subtraction and optical flow, which laid the groundwork for understanding and interpreting video data. As technology progressed, deep learning methods like Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) emerged, offering more sophisticated and accurate ways to detect and track objects in videos. This section delves into the key algorithms and techniques that have shaped the landscape of video object detection, exploring their principles, applications, and the challenges they address.
Traditional video object detection algorithms
Background Subtraction
Background subtraction is a prevalent traditional method for performing video object detection. Its main objective is to focus on moving or non-stationary foreground objects by eliminating the stationary or slowly changing background. The main principle here is that the background of a scene remains relatively consistent over time, which makes it easy to distinguish objects of interest in the foreground.
The first step in the process is to construct a model that can accurately represent the background of the video using statistical methods such as averaging pixel values or using Gaussian mixture models. Next, each frame is analyzed against this model to check the pixel deviations between each frame and the background. Significantly differing pixels represent potentially moving objects; hence, they can be classified as foreground.
Several challenges, such as different lighting conditions, shadows, occlusions, noisy backgrounds, or abrupt changing of background, can make this technique difficult to implement. To address these and other issues, it is always a good idea to use adaptive modeling and some post-processing techniques to segregate the foreground better. However, it is difficult to promise an accurate output with this technique; hence, it is often used as a preprocessing step in the current advanced computer vision applications.
Optical Flow
Optical flow is another traditional computer vision technique used to estimate the motion of objects in a video. This approach is based on the principle that the intensity of pixels remains constant across the frames. Therefore, analyzing the brightness patterns in consecutive frames allows tracking an object's motion in a scene. Technically, it calculates the displacement of pixels and generates a vector field for the motion of each pixel. Different techniques to compute the optical flow using mathematical models involve differential methods such as Lucas-Kanade and feature-based methods such as the Kanade-Lucas-Tomasi (KLT) tracker.
Optical flow is a widespread technique with applications across tasks such as object tracking and motion analysis. Its key advantage lies in its ability to track the trajectory of pixel intensity across successive video frames, making it especially useful for understanding the motion dynamics of objects without needing to identify them. However, the technique does have limitations. In scenarios with frequent occlusions—where objects are partially or fully obstructed from view—or when the objects move rapidly, the optical flow can struggle to provide accurate estimations. This is also the case when the visual scene is highly complex or patterns change abruptly, which can confuse the algorithm as it relies on the consistency of patterns over time. Therefore, this method is often used as a foundation in advanced tracking algorithms.
Deep learning models for video object detection
Convolutional Neural Networks (CNNs)
Convolutional Neural Networks are the foundational networks in deep learning for performing video object detection. They are proficient in extracting spatial features from individual frames and capturing temporal dependencies across subsequent frames. CNNs extract information through the convolution of kernels with the individual frames to identify objects. Temporal information is incorporated using techniques such as optical flow or RNNs, which analyze the motion of objects and track object trajectories across the video sequence. Therefore, using these two approaches, the algorithm detects and tracks objects. Usually, the detections are post-processed using techniques such as non-maximum suppression to refine the detections and improve tracking precision. Thus, CNNs play a pivotal role in applications of video object detection for understanding dynamic visual scenes.
Recurrent Neural Networks (RNNs)
Recurrent Neural Networks (RNNs) are instrumental in video object detection due to their ability to effectively capture temporal information in the video data. Since video comprises multiple frames, it is essential to model the sequential information and make sense of the object's movements over time. This is done with the help of memory cells (recurrent units) in the hidden layers, which remember the information from previous frames and use it to process the current frame. RNNs can also be combined with techniques such as attention mechanisms or long short-term memory cells to effectively capture the video's long-range dependencies and complex patterns. RNNs can be particularly useful for applications such as action recognition and combining them with models providing other capabilities they can be used for various applications such as surveillance and human-computer interaction.
You only look once (YOLO)

Timeline of YOLO. (Source)
YOLO and its variants up to YOLO-v8 are some of the most popular and state-of-the-art real-time object detection algorithms. They divide the input image into a grid and predict the bounding boxes and class probabilities for each grid cell. For video object detection, grid formations and predictions are performed on individual video frames; the neural network is applied to the entire image. Forming a grid enables the algorithm to detect multiple objects of varying scales and sizes easily.
YOLO uses deep convolutional layers for feature extraction and employs techniques such as non-maximum suppression and anchor boxes to refine the detections and remove duplicate detections. YOLO comprises a unified architecture to capture spatial and temporal information; hence, it is suitable for video object detection. It is popular because of its fast processing time and real-time predictions, so it is widely used across domains such as autonomous driving and robotics.
Single shot multi-box detector (SSD)
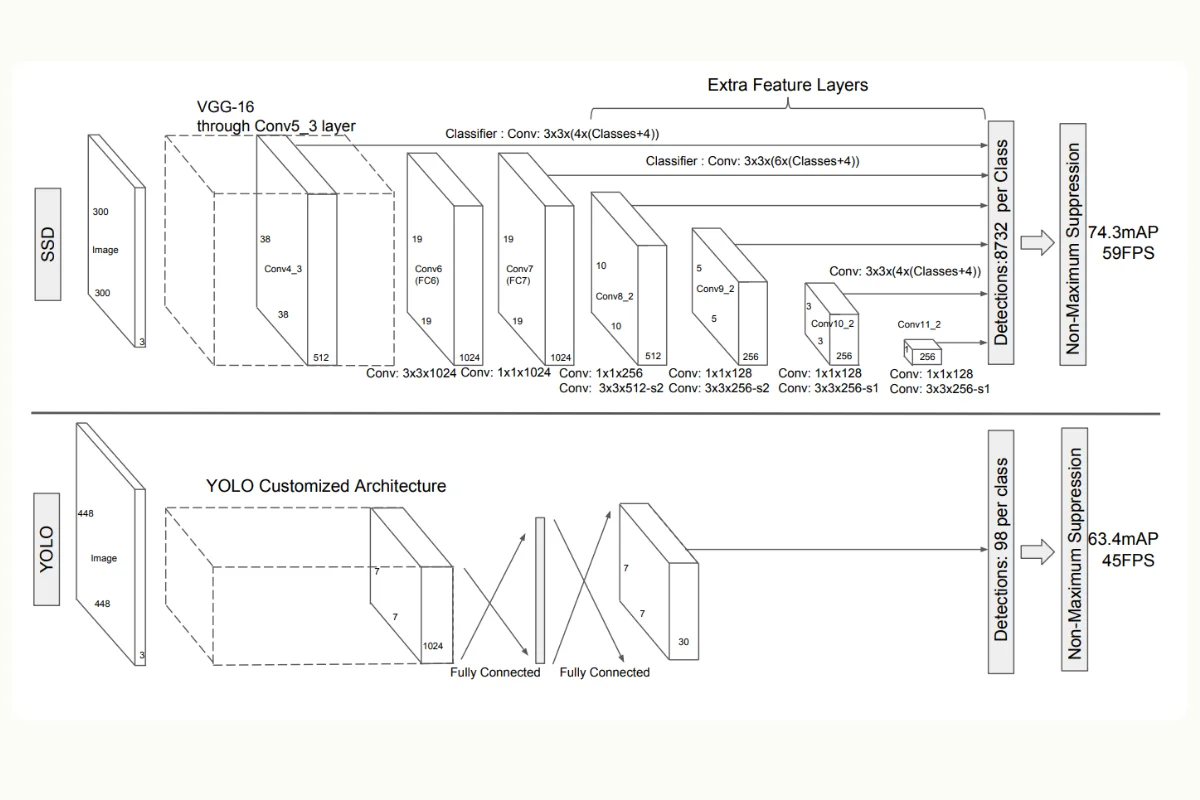
SSD compared to YOLO. (Source)
SSD is another popular deep-learning framework used for real-time object detection. It applies the neural network to individual video frames like previous algorithms. However, it already has predefined bounding boxes of varying ratios and scales that apply to the single frame to detect objects.
So, each bounding box of predefined aspect ratio and scale will have its class probabilities. This approach allows SSD to capture objects of varying sizes in a single pass, making it suitable for real-time detection. In addition to detection, SSD can also track objects across different frames, making it suitable for video object detection. Like other algorithms, SSD also integrates non-maximum suppression techniques for refining the detections to enhance accuracy.
To summarize, the ability of SSD to detect objects of varying shapes and sizes in a single pass makes it suitable for real-time use and a valuable tool in applications for video surveillance, action recognition, traffic management, and retail.
The progression from traditional methods to advanced deep learning approaches in video object detection reflects the continuous pursuit of more efficient, accurate, and versatile computer vision solutions. These technologies enhance our understanding of video content and open new possibilities for innovation across various industries.
Challenges in Video Object Detection
.webp)
Video Object Detection is a challenging task as it requires considering numerous factors and challenges that can arise from the complexity of the video data. Some of the critical challenges are mentioned below:
- Real-time processing: Obtaining real-time performance for video object detection is challenging as the computational speed depends on the complexity and resolution of the video, which is uncertain to determine beforehand.
- Occlusions: All the objects in the video may not be fully visible. They may often be occluded partially or fully by other objects or the environment, making it difficult to detect them accurately.
- Motion blur: Motion blur can be caused if the objects move too fast or the camera is unstable. This can create a loss of details, making it difficult for the algorithm to detect and track them.
- Scale variation: Objects may not maintain the same scale and size throughout the video. It may change based on the object's proximity to the camera across all the frames. Hence, handling these variations is a challenging aspect of the algorithms.
- Background clutter: The clutter or noise in the object's background can interfere with the detection process, specifically when the background exhibits similar features to the object. This can lead to false positives or missed detections.
- Illumination changes: The lighting conditions in terms of brightness, shadow, or glare can change across the video frames, affecting the appearance of the objects and making it challenging to maintain the detection accuracy.
- Data association and tracking: The association and tracking of detected objects across multiple frames is challenging, significantly when the environmental conditions are changing and causing frequent occlusions or appearance changes.
Addressing these challenges requires experimenting with different preprocessing, modeling, and post-processing techniques tailored to specific tasks.
Data collection and pre-processing for video object detection
Part of addressing these challenges in video object detection starts with collecting and pre-processing data. When collecting and preprocessing data for video object detection, several key points should be considered to ensure the effectiveness and efficiency of the process:
- Data Diversity: The data should be diverse; it should contain different scenarios and environments that pertain to the target application. Also, the greater the diversity, the better the generalizing capability of the model.
- Annotation Consistency: Ensure consistent and accurate annotation across all frames and videos to provide reliable ground truth data for model training and evaluation.
- Data Augmentation: Apply data augmentation techniques, such as flipping, rotation, or scaling, to increase the diversity and quantity of the training data, enhancing not only the model's robustness but also the generalization capability.
- Video Quality: Collect high-quality videos with sufficient resolution to ensure that the objects of interest are visible and distinguishable, facilitating accurate annotation and model training.
- Temporal Sampling: Consider the appropriate frame rate and temporal sampling frequency for video data collection, ensuring that the captured frames provide sufficient temporal information for effective object detection and tracking.
- Noise Reduction: Implement preprocessing techniques, such as denoising and smoothing, to reduce noise and artifacts in the video data, enhancing the overall quality of the input data for the model.
- Data Privacy and Ethics: Adhere to data privacy regulations and ethical guidelines when collecting and preprocessing video data, ensuring the data collection process is conducted responsibly and lawfully.
Best data labeling practices for video object detection
Fast annotation of similar class objects in video
While the data has been collected and preprocessed, the next step is to ensure that best annotation practices are followed. The more precise and accurate the annotations, the better the model output. Some of the must-follow best practices are:
- Temporal Consistency: Ensure that objects are consistently annotated across consecutive frames, accurately capturing their movements and trajectories throughout the video sequence.
- Frame-Level Labeling: Label each frame individually to ensure precise object localization and classification, facilitating accurate model training and evaluation.
- Multiple Object Instances: Annotate all instances of the same object class within a frame, especially in cases where multiple instances of an object class appear simultaneously.
- Handling Occlusions: Annotate partially occluded objects, indicating their visible portions within the bounding box to provide comprehensive information for the model.
- Dynamic Object Changes: Adjust bounding boxes for objects that change shape or size dynamically within a video sequence, ensuring an accurate representation of their spatial dimensions over time.
- Motion Trajectory Annotation: Annotate moving objects' trajectories, marking their positions across frames to enable accurate tracking and analysis of object movements.
- Object Identification: Use unique identifiers or tags for individual objects within a video sequence to differentiate and track them accurately, ensuring distinct annotations for each object instance.
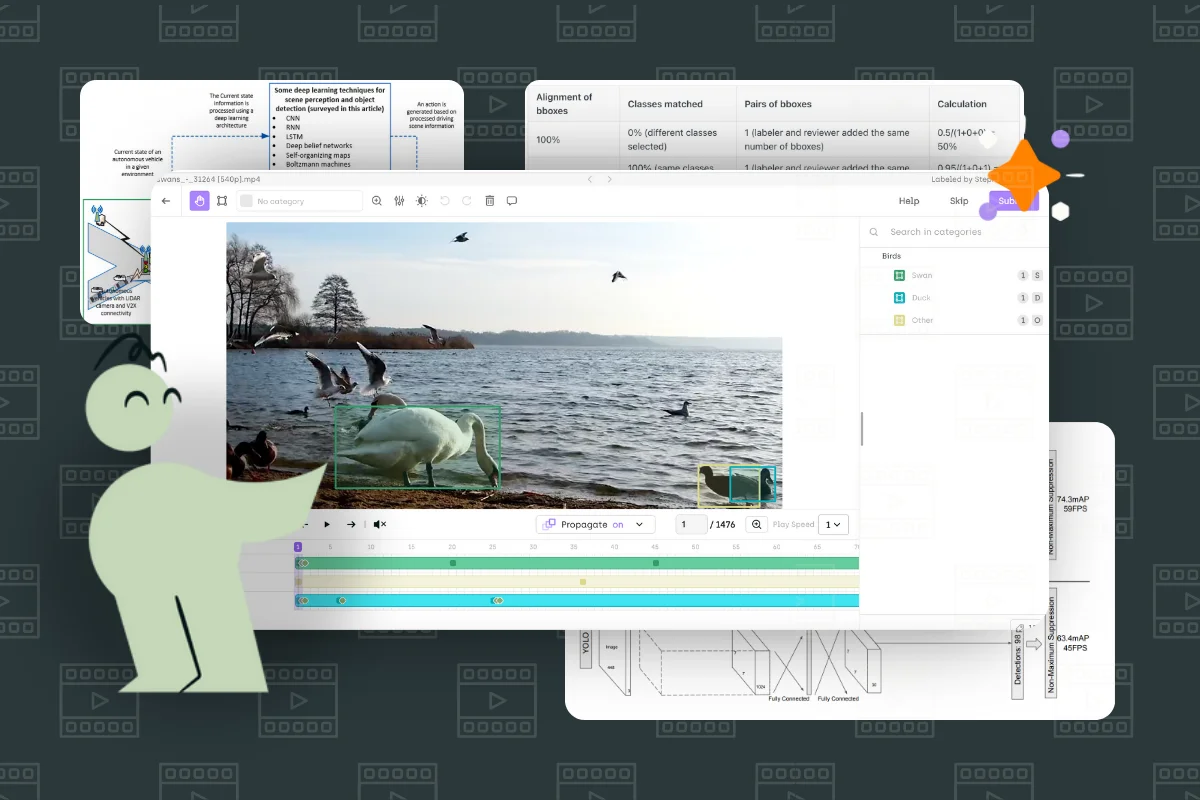
For efficient object detection, precise annotation is crucial. An advanced tool like Kili Technology's video annotation platform can facilitate this process. It has been redesigned with a more precise, more navigable timeline and adjustable propagation settings for annotations, essential for accurately tracking objects across frames.
Smart tracking feature on Kili
Interpolation and smart tracking features are also included to automatically annotate moving objects, saving time on manual annotation. While annotating, it's possible to adjust the span of annotated frames easily, providing flexibility and enhancing the quality of temporal annotations. These features support best practices by allowing detailed frame-by-frame analysis and adjustment, which is crucial for training accurate video object detection models.
Dive in to our new video annotation tool
Kili's data labeling platform just got a huge upgrade. Check it out and learn how we've just made video annotation much easier!
Learn More
Quality Assurance in Video Annotation
Conducting a quality assurance check in video annotation is extremely important to ensure the implemented pipeline is error-free, generates good accuracy, and has a reasonable annotation speed vs accuracy tradeoff. Additionally, quality assurance is needed to ensure that all the ethical points are considered and that the tool/algorithm is safe to be sent to production. Here are some of the significant points to consider for the quality assurance test:
- Quality Evaluation Metrics: Define and employ appropriate evaluation metrics, such as inter-annotator agreement, precision, recall, F1 score, and Intersection over Union, to assess the accuracy and consistency of annotations.
- Annotation Time Benchmarking: Establish benchmarking standards for annotation time per frame or per video segment to gauge the efficiency and productivity of annotators.
- Monitoring of Annotation Speed: Continuously monitor and track the annotation speed of individual annotators and the overall annotation team, identifying variations and promptly addressing potential bottlenecks or inefficiencies.
- Feedback Integration: Integrate feedback mechanisms for annotators to report annotation speed and quality issues, fostering a culture of continuous improvement and learning within the annotation team.
Kili Technology provides an excellent feature for calculating consensus rules for object detection tasks for bounding boxes, polygons, and semantic segmentation. It considers each image as a set of pixels to be classified. The individual pixel can be classified into several non-exclusive categories or classes to represent different objects. The metric requires calculating all annotations' Intersection over the Union (IOU).
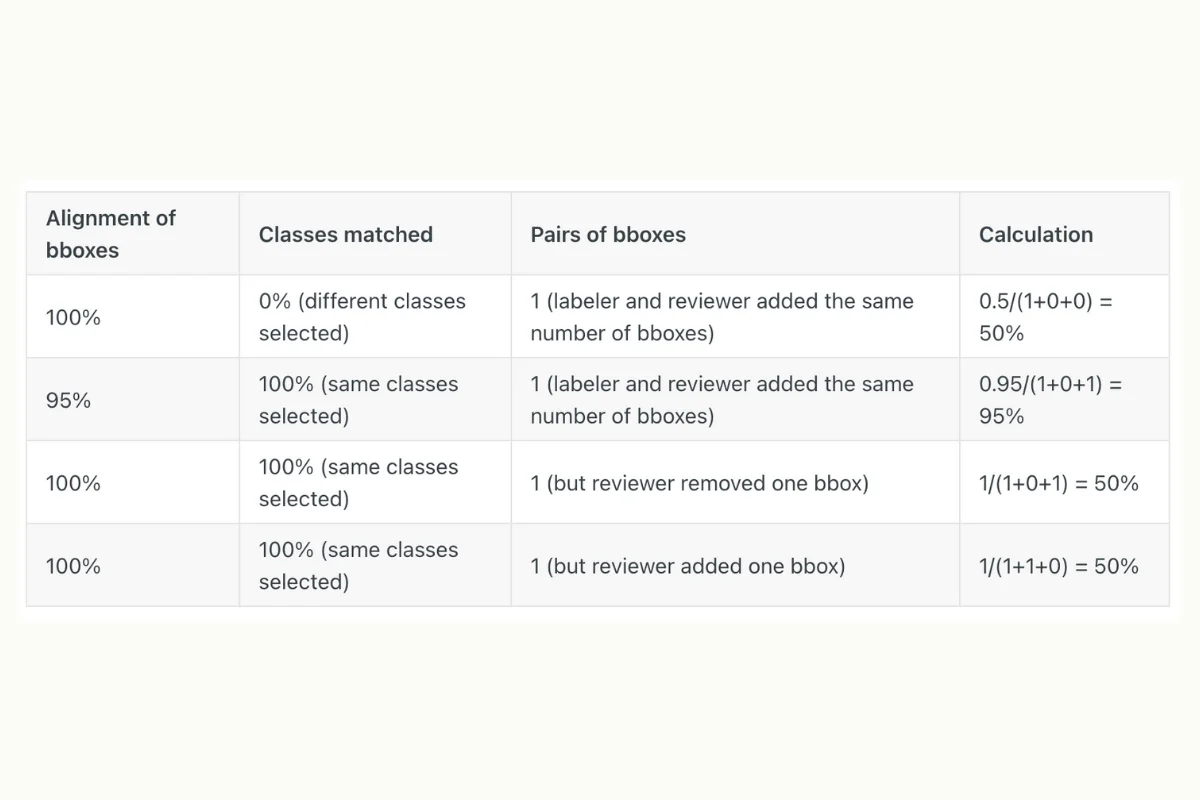
Calculation metrics for bounding box object detection tasks on Kili
If two bounding boxes overlap perfectly, their metric is 100%, whereas two distinct non-overlapping shapes will correspond to a metric of 0%. This method is particularly beneficial because it ensures accuracy for shapes of all sizes.
Additionally, Kili technology provides a super easy and convenient way to view quality insights through its analytics functionality. The Quality Insights tab on the dashboard of Kili will provide insights regarding consensus and honeypot metrics. It provides per-class and per-labeler information and a total agreement score for consensus and honeypot. Furthermore, one can also start one’s review and use graphs and scores to target the relevant assets.
If neither consensus nor honeypot is set in the project, then the Quality Insights tab shows the review score per labeler. These review scores are calculated by comparing the original label with its reviewed version. This is an important metric to assess how well a team is performing.
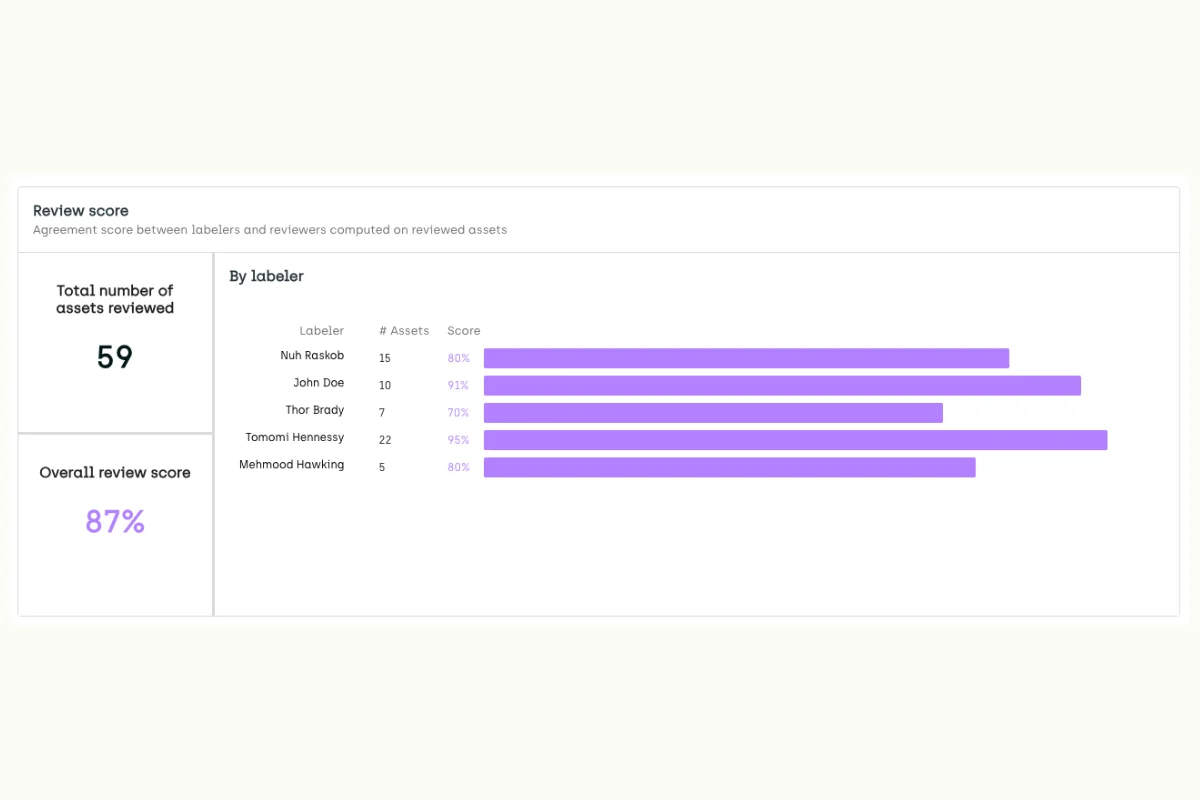
Productivity and quality review score for labelers
Wrap-Up
To sum up, video object detection is complex and requires appropriate tools to handle its intricacies. The process can be significantly streamlined by adopting best practices in data annotation and leveraging platforms such as Kili Technology's video annotation tool. This approach ensures that the resulting algorithms are practical, efficient, and ready to be deployed in real-world scenarios where accuracy is paramount.
Don't hesitate to try out Kili's video annotation tool now and experience the convenience of easily annotating videos!

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
