
.png)

_logo%201.svg)


AI Summary
The demand for video annotation in computer vision is increasing, driven by the need to develop AI models that can understand complex dynamics, interactions, and temporal shifts within video data. This capability is essential for enhancing AI model accuracy and leveraging new opportunities in the technology sector.
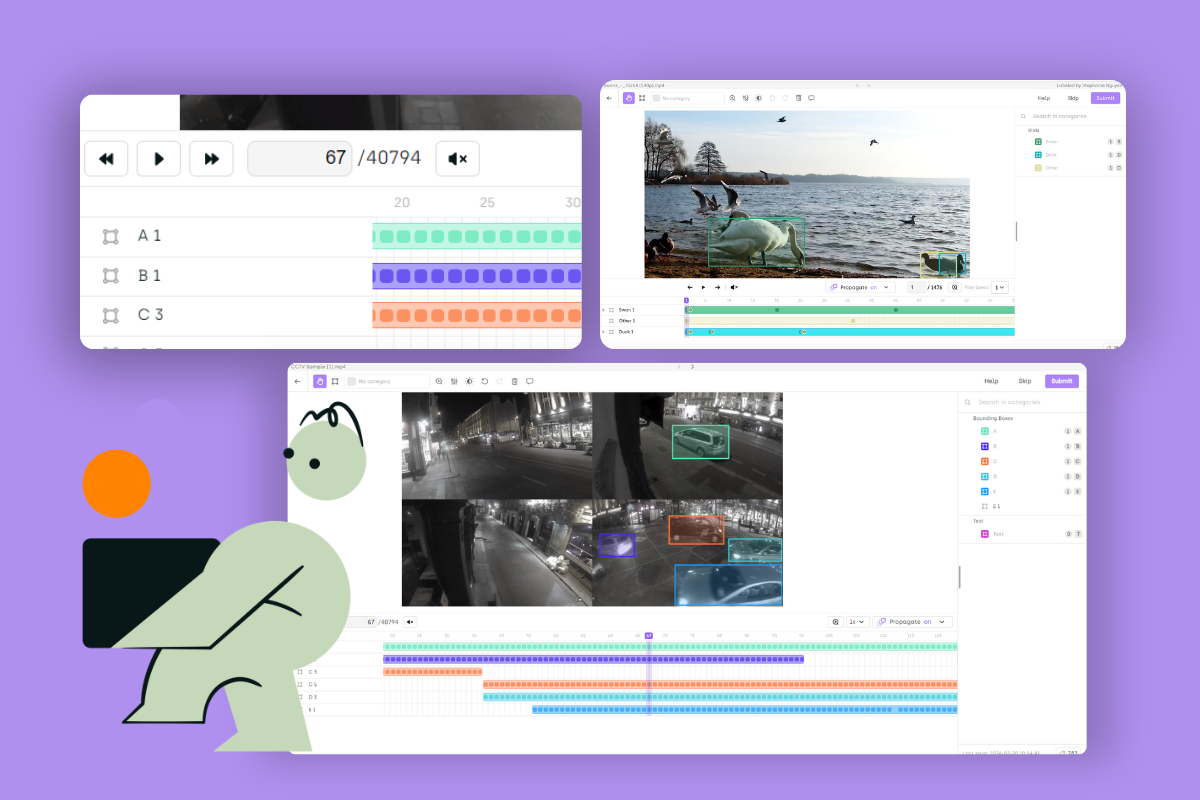
Addressing this need, there is a critical demand for video annotation tools that are precise, efficient, and capable of managing the extensive amounts of video data produced daily. Machine learning engineers and data scientists need advanced tools that can support their goals of rapidly deploying more sophisticated computer vision models. Today, we are pleased to unveil an advanced feature in our video annotation tool that supports long videos with thousands of objects in each frame.
This expanded capability brings a host of benefits to our users. With the ability to annotate very long videos and handle numerous objects in each frame, businesses can now create more comprehensive and realistic training datasets. This, in turn, translates to the development of AI models that are better equipped to handle complex real-world scenarios.
The extended support for large video files ensures that intricate details and specific objects within the video data are captured, creating more robust models for improved decision-making processes.
The process of annotating videos
The process of annotating short video clips is already daunting enough. Machine learning engineers and video annotators need robust video annotation software that can handle the multiple challenges of labeling videos, such as tedious frame-by-frame annotations, time and labor intensity, demanding accuracy and consistency requirements, and the complexity of dynamic scenes. As a review, here's a very simplified process of annotating videos.
- Define annotation guidelines: Decide what labels or video annotations are needed. For example, if your model is to recognize animals in videos, you need to define what animals to look for and how detailed the labels should be.
- Select an annotation tool: There are annotation tools specifically designed for video annotation. These tools allow you to label videos frame by frame or with bounding boxes, polygons, or other shapes that identify and follow the objects through the video.
- Frame-by-frame annotation: Videos consist of many individual frames (images). You might need to label important objects, actions, or events in each frame. This can be labor-intensive but is crucial for training accurate models.
- Temporal annotation: In addition to labeling individual frames, you may also annotate sequences or durations within the video where certain actions or activities happen. This helps the model understand not just what appears but also what happens over time.
- Review and refine: After annotating, it's important to review the annotations to ensure consistency and accuracy. You might need to adjust or redo some annotations to meet the quality required for training effective models.
Machine learning teams have overcome some of these challenges through object detection models that predict pre-annotations before labelers can come in and complete the process. Popular object detection models today are YOLO (You-Only-Look-Once), SSD (Single-shot multi-box detector), and Faster R-CNN (Region-based Convolutional Neural Network). Check out our article on video object detection here.
Challenges in Annotating Videos: Navigating the Technical Landscape
Volume of Objects
While the opportunities are vast, annotating videos, especially those with many objects in each frame, presents a significant challenge. Traditional annotation tools struggle to handle the complexity of annotating thousands of objects in a single frame, leading to inefficiencies and compromising the quality of training data.
Extended video annotation is applicable in several areas, including:
- Surveillance and Security: Annotating lengthy surveillance footage to train models for identifying potential risks and threats in real time.
- Autonomous Vehicles: Training AI systems to recognize objects and scenarios in diverse driving conditions by annotating extensive video data captured from vehicles.
- Sports Analysis: Analyzing long sports events for performance tracking, strategy development, and automated highlights generation.
- Healthcare and Medical Imaging: Annotating long video sequences for surgical training, patient monitoring, and diagnostic tool development.
Computational Intensity
The technical complexity of processing and annotating very long videos is another hurdle. As the length of videos increases, the computational requirements—both in terms of processing power and memory—also increase significantly. This complexity arises due to several factors inherent to video data and its processing needs. Let's break down why this is the case:
1. Increased Data Volume
- Frame Count: A longer video means more frames to process. Considering that a standard video may run at 24 to 30 frames per second (fps), a video several hours long could contain millions of frames.
- Resolution: High-resolution videos exacerbate the problem, as each frame contains more pixel data that needs to be processed and annotated.
2. Temporal Dynamics
- Videos are not just collections of independent images; they include temporal relationships between frames. Tracking objects or actions across frames requires algorithms to maintain context over time, adding to the computational load.
3. Annotation Complexity
- Multiple Objects: Longer videos are likely to contain more unique objects that need to be identified, tracked, and annotated across potentially thousands of frames.
- Object Interactions: Object interactions can change over time, requiring sophisticated models to accurately understand and annotate these dynamics.
4. Storage and Bandwidth
- Storing long videos and the associated annotated data requires substantial storage capacity. Moreover, transferring these large datasets for processing or training can consume significant bandwidth, posing additional challenges.
Tedious manual labeling
Labeling and tracking objects in video frames is technically demanding, exceptionally time-consuming, and tedious, especially for videos with a high object count or complex interactions. This tedium is amplified in the context of the following factors:
- Manual Effort: Despite advances in automation and machine learning, a significant portion of the video annotation process still relies on manual effort. Video annotators must meticulously identify and label each object in a frame, which becomes increasingly burdensome as the number of objects and the complexity of their interactions grow.
- Frame-by-Frame Annotation: Annotators often have to work on a frame-by-frame basis for video, especially those requiring precise object tracking or interaction analysis. This approach ensures accuracy but dramatically increases the workload, as annotating a single minute of video footage can take hours.
- Revisiting and Revising Annotations: Ensuring high-quality annotations often requires revisiting previously annotated frames to adjust labels as new contextual information becomes available later in the video. This iterative process is critical for maintaining consistency and accuracy but further adds to the labor-intensive nature of the task.
- Complex Object Dynamics: Videos capturing complex scenes or dynamics, such as a bustling cityscape or a fast-paced sports game, present unique challenges. Objects may enter, exit, occlude, or interact unpredictably, requiring annotators to apply nuanced judgment and constantly adjust.
- Annotation Quality and Consistency: Maintaining a high level of quality and consistency across thousands of frames is a daunting task. Variability in annotator interpretation, fatigue, and oversight can lead to labeling inconsistencies, affecting the training data's reliability.
- Domain Knowledge Requirements: Certain domains, such as healthcare, automotive, or sports, require annotators to have domain-specific knowledge to label and interpret scenes accurately. This requirement limits the pool of potential computer vision annotators and adds a layer of complexity to the training and quality control processes.
The ideal video annotation tool: combining streamlined annotation with powerful processing capabilities
The ideal video annotation tool for tackling these challenges head-on combines cutting-edge technology with user-centric design, offering solutions that significantly reduce manual effort, enhance accuracy, and streamline the entire annotation process.
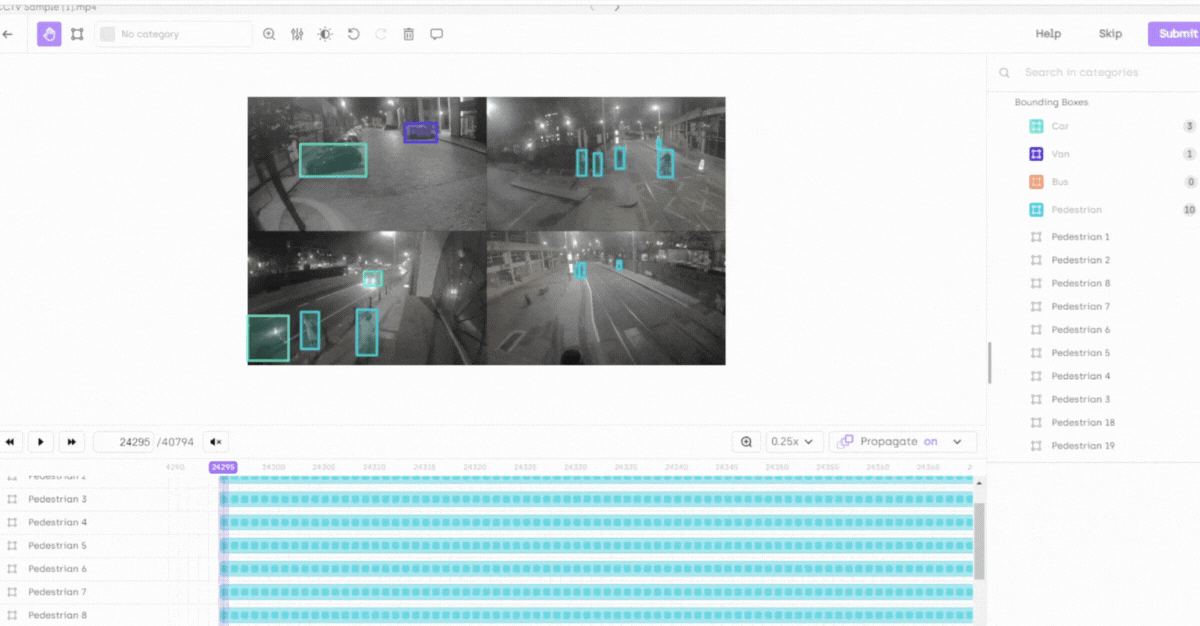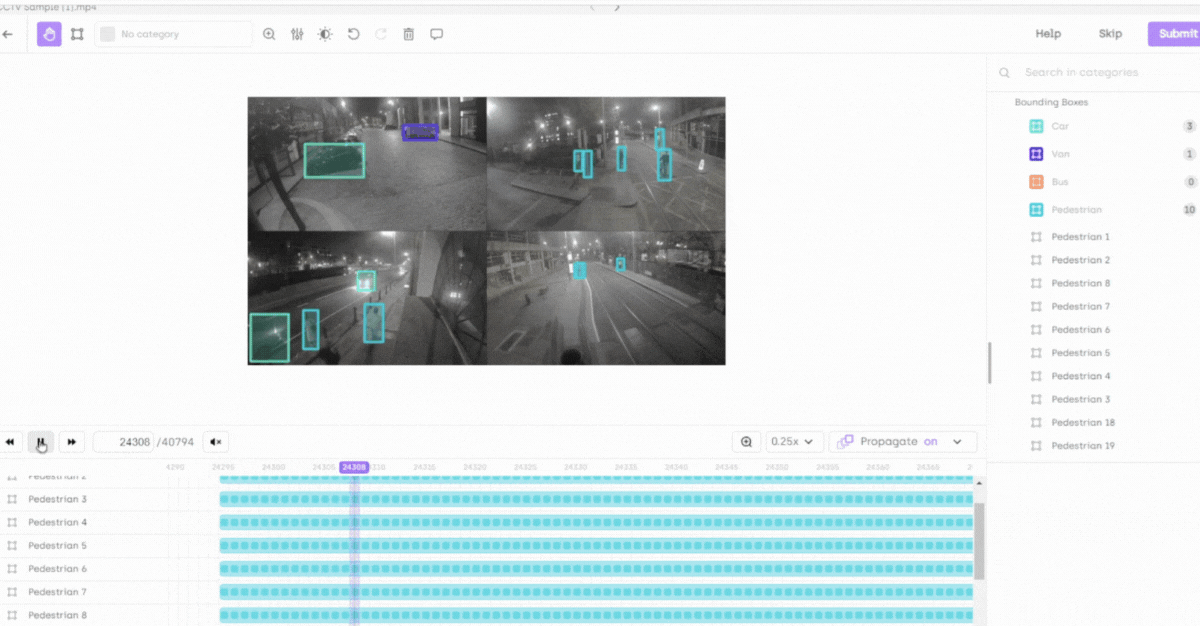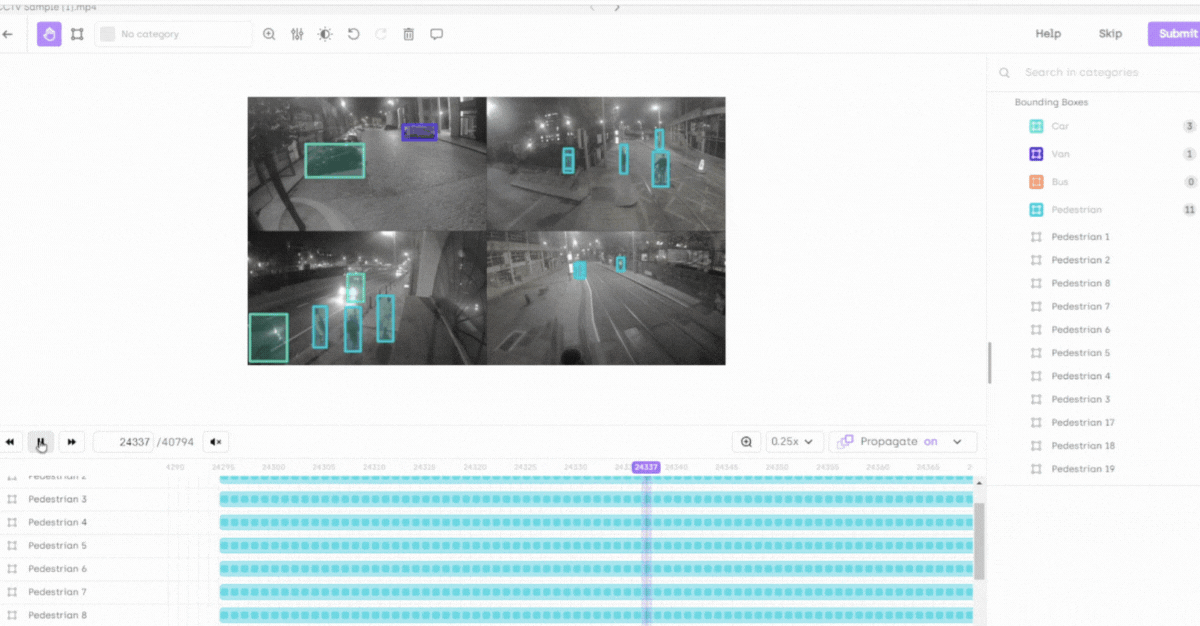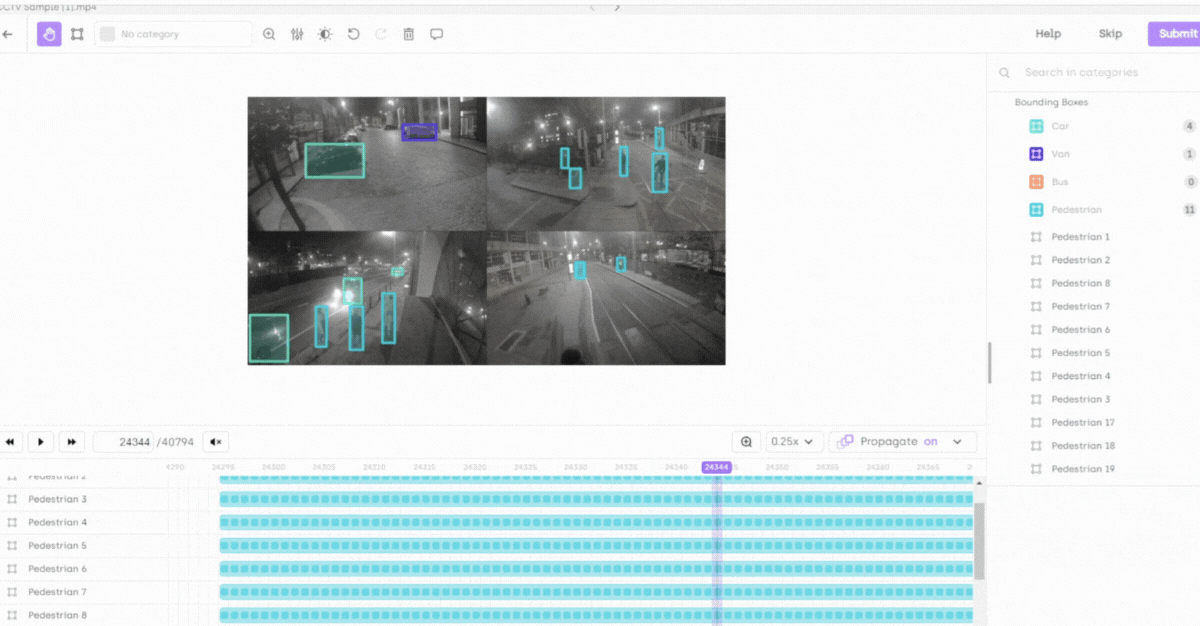
Optimized for 100,000+ frames: Our platform is fine-tuned to handle videos with over 100,000 frames, ensuring seamless performance even in the most demanding scenarios.
High-performance processing and storage solutions: These are optimized for processing long videos and scalable storage, including cloud-based options for improved accessibility and collaboration.
Smart object tracking: Reduces manual effort through automatic detection and tracking of objects across frames, suggesting annotations for quicker verification and adjustments.
Smart interpolation and timeline section: Enhances precision in dynamic sequences and provides an efficient interface for reviewing and managing annotations and their attributes.
Comprehensive quality control tools: Includes automated error detection and consensus mechanisms for verifying annotations, ensuring high quality and consistency.
Collaborative Annotation Features: Supports teamwork with capabilities for multiple annotators to work simultaneously or divide tasks, complemented by robust version control.
Customizable Annotation Labels: This feature enables users to define their own labels and categories, catering to the specific needs of various projects across industries.
What's next?
We're excited to announce the beta launch of our advanced video annotation tool, designed to tackle the complexities of annotating extensive videos and complex datasets. As we further improve this feature, we're calling on users to help us shape the future of video annotation. Your feedback is crucial, and we welcome any insights or experiences you'd like to share. We aim to make video annotation more accessible, efficient, and user-friendly. Get in touch with us to discover more and join this exciting journey.
Contact Sales
Frequently Asked Questions
What is video annotation, and how does it differ from image annotation?
Video annotation involves tagging or labeling video content frame by frame to identify and track objects or actions throughout the video sequence. Unlike image annotation, which deals with still images, video annotation takes into account the temporal dimension, making it crucial for training computer vision models that need to understand and predict actions over time. Video annotation allows models to recognize patterns not just in a single frame but across a series of frames for activities such as object tracking or behavior prediction.
Why is annotating video data essential for training computer vision models?
Annotating video data is fundamental for training computer vision models because it provides the labeled data these models need to learn and understand dynamic scenes and activities. By accurately identifying and tracking objects or actions across frames, the models can be trained to recognize, predict, and interpret real-world scenarios accurately. This is critical for applications like autonomous driving, surveillance, sports analytics, and more, where understanding the context and changes over time is essential.
How can I track objects effectively in long videos?
Tracking objects in long videos efficiently requires using advanced video annotation tools that support object tracking features. These tools automatically track an object across frames once it is labeled, saving time and ensuring consistency in object identification throughout the video. Look for tools that offer robust tracking algorithms capable of handling changes in object appearance, occlusions, and movement to ensure accurate tracking even in complex video scenes.
What are some of the challenges associated with annotating long video data?
Annotating long video data presents several challenges, including the sheer volume of data to process, the need to maintain consistency in object labeling across frames, and the difficulty of tracking objects that change appearance, move rapidly, or become occluded. Additionally, annotator fatigue can lead to decreased accuracy over time, making it important to use tools and processes that streamline the annotation workflow and enhance efficiency.
What features should I look for in a video annotation tool to handle long videos effectively?
For handling long videos effectively, look for a video annotation tool that offers:
- Smart object tracking: Automatically track labeled objects across frames.
- Customizable labeling interfaces: Adapt the tool to specific project needs.
- Integration capabilities: Easily integrate with your existing data management and model training workflows.
- Quality control features: Ensure annotation accuracy and consistency with built-in quality checks and review processes.
Which video annotation tool is considered the best for model training?
The best video annotation tool for model training depends on your specific needs, including the complexity of the video data, the types of objects or actions being annotated, and your project's scale. Tools that offer advanced tracking capabilities, high efficiency in handling long videos, and flexibility in integrating with machine learning workflows are generally considered top choices. Evaluate several video annotation tools based on these criteria and consider conducting a pilot project to determine which tool best fits your requirements.
How does video annotation contribute to the accuracy of computer vision models?
Video annotation contributes to the accuracy of computer vision models by providing high-quality, labeled datasets that these models use to learn and understand the visual world. By accurately identifying and tracking objects or actions across video frames, the models can be trained to recognize patterns, predict outcomes, and make decisions based on real-world scenarios. This leads to more robust and reliable computer vision applications that can perform accurately even in complex and dynamic environments.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
