.png)
AI Summary
As algorithms grow more complex, they also grow hungry for more data, to be able to learn precisely the meaning of the sentence. In Text Classification task for example, the variety of words encountered allows for a much more resilient algorithm, especially when in production with a taste of real word data.
Just as in Computer Vision where biases such as detecting a seagull is more correlated with the presence of the beach rather than the bird itself, words in NLU can be badly associated with an incorrect class and can thus be a threat in the case of real world use, as examples get harder to discriminate.
If automatic generation of new data can be of help in simply increasing the number of training example, how good is it performing against the use of more training data from the same dataset, and are their way to efficiently generate more data ?
This article is inspired by the paper Learning the Difference that Makes a Difference with Counterfactually-Augmented Data, that can be found here on arXiv
In this study, the authors point out the difficulty for Machine Learning models to generalize the classification rules learned, because their decision rules, described as 'spurious patternes', often miss the key elements that affects most the sentiment of a text. They thus decided to confusion factor, by changing the label of an asset at the same time as changing the minimum amount of words so those key-words would be much easier for the model to spot.
We'll go through details of the paper for a text-classification task, and study
1. The impact of counterfactually-augmented data
2. Compare the efficiency and cost of such data generation technique
We'll use the data of the study, the IMDB sentiment analysis dataset, publicly available here.
The dataset consists in 50k reviews of movies, and the task is to classify those reviews as positive or negative opinions about a movie.
Counterfactual data augmentation
In the article Learning the Difference that Makes a Difference with Counterfactually-Augmented Data, the authors created a new labelling task based on the IMDB dataset. On a subset of reviews, it was asked the annotators to change the class of the review by changing the minimum of words in the review.
For example, the sentence :
Long, boring, blasphemous. Never have I been so glad to see ending credits roll.
became : Long, fascinating, soulful. Never have I been so sad to see ending credits roll.
We will use in this study different machine learning models, and analyze their performance on the original data to understand how well counterfactual data can improve performance on this text classification task.
Experimental setup
1. Task
Data is collected from the original IMDB dataset and the study presented above. It is a subset of review written on the IMDB website, along with a sentiment (Positive or Negative). The task for the algorithm is to classify properly each of the reviews.
Here, we will use both the counterfactually generated reviews and the original reviews, and also a combination of both.
More precisely, we will use those 4 datasets :
- the original dataset, a subset from the imdb dataset
- the revised dataset created in the study from variations of the original dataset
- the combined dataset, combining the two previous datasets
- the originalDouble dataset, enlarging the original dataset with more reviews from the imdb dataset.
2. Pipeline
- Each dataset, including the original IMDB dataset is split in a balanced way between a training, validation & test dataset.
- For the text processing, no pre-processing is applied to the original reviews.
- The reviews are encoded, for the machine learning models, with a TF-IDF bag-of-words approach. We first compute the term frequency (t is the evaluated term and d the review)
$$ tf(t,d) = \frac{ f_{t,d}}{\sum_{t'\in d}{f_{t',d}}}$$
And then the inverse document frequency (D is the ensemble of all the reviews) :
$$\mathrm{idf}(t, D) = \log \frac{N}{|{d \in D: t \in d}|}$$
And use those values to determine which words or bigrams are kept. We keep in this study conservative parameters, with unigrams and bigrams, the 75% less represented words of the corpus, except those present in less than 5 documents, limiting to 20000 words in total.
- We then conduct a grid search on a dedicated validation dataset, specific to each model.
- Final results are computed for all datasets, on the test set.
3. Models
We chose different enough models, to grab a better sense of the type of circumstances in which counterfactual data can be of help. The models tested are the sklearn implementation of :
- SVM : A Support Vector Machine classifier.
- RF : A Random Forest classifier
- DecisionTree : A DecisionTree classifier
- XGB : A XGBoost Classifier
- LogisticRegression : A Logistic Regression classifier
- KNN : A K - Nearest Neighbors Classifier
- SGD : A Stochastic Gradient Descent implementation of SVM
- NB : A Naive Bayes Classifier
We also use Keras to implement a Neural Network for sequence models :
- LSTM : A bi-LSTM Neural Network, with a 300 words * 20000 words Word Embedding, a Max Pooling Layer, a Bidirectionnal LSTM, and 2 fully connected layers. The loss is used is the Adam Optimizer.
4. Metric
The metric used is the accuracy, as the dataset is balanced so it is not biased for this task and metric.
$$\texttt{accuracy}(y, \hat{y}) = \frac{1}{n_\text{samples}} \sum_{i=0}^{n_\text{samples}-1} 1_{(\hat{y}_i = y_i)}$$
Building a more resilient dataset
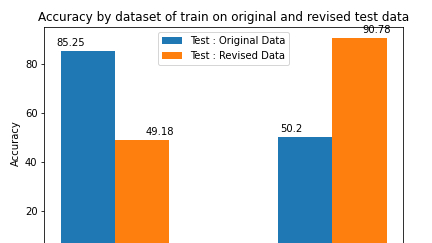
The interest of such a technic is primarily to help the model grab a better sense of the useful words that really encapture the meaning of the sentence. As a matter of fact, a model trained on the original data fails to score better than random guess on counterfactual out-of-sample data.
The opposite is also true, a model trained on counterfactual data scores very poorly on original data, not better than random guess on out-of-sample data.
This effect of resilience is well illustrated for the SVM or LogisticRegression classifiers, as it is possible to compute the feature importance of each word for the task. The comparison between the key words for the model trained on the combined dataset and for the original dataset is striking.
The words that most contribute to the classification of the review are often not those that are most useful (words like classic, one of, romantic, or something for example)
On the contrary, a model trained on the combined dataset (with both the original and the revised dataset), has much more coherent words as important features, increasing the ability of the model to classify correctly out-of-sample examples.
To analyse better how the counterfactual data helps, let's analyze how those feature importance changes from one dataset to the other, by substracting to the original list the combined one. We obtain for the main factors for original data how counterfactual reweights the features to be less biased.
Below are the figures for the most important features for the Positive and the Negative Class.
For the word great for example, it is reweighted 3 points above its value, whereas the importance of the word romantic decreases from 1 point.
For the features important to classify negatively a review, the word horror was important but it's importance is now reduced from 2 point (bar in the opposite direction as features are negative), just like the word something, why, plot,...
Furthermore, the performance is much better for this last model, on both the revised and the original dataset
Counterfactual augmentation
For a more accurate comparison, we choose to compare the performance of models trained with the same number of data. Below are gathered the results across multiple models on the original test data.
It is interesting to differentiate 3 different situations in the results above :
- For most models, the increase in data points increases performance. Those models are for example SVM, RF, DecisionTree, LogisticRegression, for which both models trained with more data (counterfactual 3,4k and original 3,4k) score better on the original test set.
- For some models, like Naive Bayes and K-Nearest Neighbors, which are simple models, performance is better for the model with counterfactually generated data. The increase from almost 1% for KNN and almost 3 % for Naive Bayes can be explained by the much more explicit data provided.
- More elaborated models like SVM, Random Forest, DecisionTrees or XGBoost still perform better with original data than with counterfactual data, as they manage to find new patterns that increase the wealth of their dataset. Yet, this can be task specific as the reviews collected here where original review. This can be really different in the case of synthetic data.
Furthermore, another difficult thing to determine is the real convergence of the models, for the small number of training data provided. This can explain other discrepancies, such as with LSTM algorithm where the best performance is obtained with the original 1,7k dataset.
The main interest for counterfactual data is thus this ability to train a State of the Art model with a simple algorithm. With quality data, and across models, the difference is not so significative, but counterfactual data also has other advantages.
Robustify a model with counterfactual data
Another great interest for counterfactual data is that, when used with a fully parametrized model with a large training set, the performance increase is steady around 1% for almost all models tested here.
Furthermore, as previously shown, the model obtained is now resilient towards counterfactual data, even with just the use of a small subset of counterfactual data.
Cost / efficiency analysis
To evaluate further the interest of the counterfactual annotation process, we decided to evaluate the difference in costs between collecting more data and creating counterfactual data.
We thus reproduced the task of writing movie reviews, and present below the results of such a labelling task, for 100 words of reviews produced.
Writing movie reviews
The first project reproduced is the original IMDB task, onto the Kili plateform.
Labelers are asked presented with a movie poster, and are asked to write a simple review positive or negative about the movie. Movie can be skipped if it is unknown. The dataset used came from two public IMDB best movies lists, and is interesting to not that the proportion of skipped movies was very high (Between one out of 8 movies and 1/3 of movies were known, even on a list of famous movies.)
Below is a screenshot of Kili's overview interface in a project.
Along the task, labelers can also quickly access extra synopsis information on the interface, to accelerate the task.
Thus, we leveraged the strength of the annotation platform to make the task as fast as possible, and we record for each review the length of the review produced, and the time to produce the review.
Producing counterfactual data
In a second project, the same labelers are provided with original IMDB reviews, and are asked to produce counterfactual variation, by changing the smallest number of words possible.
Again, we compute the time needed to produce the review, and the length of the review produced.
Analyzing the results
The figures are then exported through Kili Playground, and the distributions are represented below : in blue for counterfactual project, and in orange for original project.
It is important to notice the mean productivity :
- for counterfactual data generation, the mean of productivity is 68 ± 56 words/min
- for original data generation, the mean of productivity is 21 ± 22 words/min
To conclude, we can argue that
- The counterfactually produced reviews are far cheaper to produce, by a factor 3. Thus, increase data by using counterfactually generated data is a great way to reach a better performance, with a reduced cost.
- Furthermore, the reviews produced are far simpler to produce, as the task does not suffer from an exhaustion. For the movie review writing process, the labelers were presented with films but could not write for every movie as they need to have seen it. In the case of counterfactual data generation, it is just necessary to understand the review.
This can be of help in other tasks as well, when generating original data relies on the imagination of labelers, and thus can quickly be exhausted.
Conclusion
It seems that there are three mains interest to use counterfactual data augmentation.
- Its impact on the performance for text classification can be as good, and even better to using more original data. In particular, we notice that simple model leverage greatly the counterfactual data strengths to be more stable and offer a State of the Art performance that is easy to iterate on.
- Furthermore, counterfactual data provides a resilience to the model towards data that can be considered as adversarial. In the case of a fully trained model, a great stabilisation is provided by counterfactual data. It allows the model to be in mean 1% more accurate across all models.
- Yet, the model of generation being so precise and systematic, it is far easier to generate than collecting original data. The original data gathering can as a matter of fact be really tedious and suffers from exhaustion, because it often relies on synthetic data, for examples in the chatbot use cases. In the beginning especially, we generate data synthetically to onboard the first users, but imagination has its limits. The counterfactual alternative guarantees, for real-world use case, a gain in factor 3 in terms of cost for the same final performance, and in quality of data as it does not suffer from the exhaustion issues. Ultimately, it allows in being at the same time weal
We studied here the case of text classification, but this could be done for many others fields of NLU, for examples Named entities recognition or intention classification. One of the primary use of this technic could thus be the development of chatbots, in which all those tasks are of primary concern.
For future work, we want to focus on those other tasks, but also be able to generate more counterfactual data than original, and analyze the performance in those case. For this, we are going to explore leads to generate massively revised data, with technique such as machine translation or massive data augmentation techniques.
Bibliography
- TF-IDF : Luhn, Hans Peter (1957). "A Statistical Approach to Mechanized Encoding and Searching of Literary Information" & Spärck Jones, K. (1972). "A Statistical Interpretation of Term Specificity and Its Application in Retrieval"
- Sklearn : Fabian Pedregosa, Gael Varoquaux et al, "Scikit-learn: Machine Learning in Python"
- Diederik P. Kingma and Jimmy Ba, Adam: A Method for Stochastic Optimization
- Yaakov HaCohen-Kerner and Daniel Miller et al., "The influence of preprocessing on text classification using a bag-of-words representation"
- Kili Technology & Kili Playground

_logo%201.svg)