
.png)

Introduction
“Good data at the heart of good AI”. This principle is what stays at the foundation of Kili Technology and is called Data-centric AI (cf. Kili’s CTO Edouard d’Archimbaud article). Instead of answering the question of how to modify the model to improve performance, it focuses on how to have a better and cleaner data-set that will result in better accuracy in the end. In fact, we have reached the point where a better training database can increase the performance of AI algorithms a few times more than using a new neural network architecture. [1]
In reality, even with such a great tool like Kili's platform, it is very difficult to have a perfect data-set. In fact, even the public data-sets considered to be error-free, like MNIST, actually contain some annotation errors, for example :
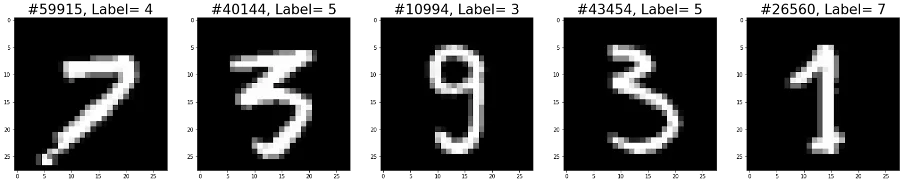
That’s why we wanted to create a solution that would allow anyone to automatically find the images that possibly have erroneous labels.
The solution with the help of Cleanlab
There has been quite a lot of research on the subject in recent years, but the most promising results were obtained by Northcutt Curtis et al. in 2019 with the paper “Confident learning: Estimating uncertainty in dataset labels”. They have also created an open-source library called Cleanlab that has a method to predict which images are likely to be miss-classified. This method needs two inputs :
A matrix of probabilities, where for each image we have the probability of it belonging to each class present in the data-set. These probabilities have to be calculated by a neural network model trained using cross validation, so that the probabilities for an image are calculated when that image was part of the test set and has not been seen by the model nor during training, nor during validation.
- A vector containing the original labels from the data set obtained from the Kili platform. These labels can be noisy, meaning that they can possibly be misclassified.
ImgClassImg 1XImg 2ZImg 3Y...
Example of the vector of original labels
Img/ClassXZYimg 10.80.050.15img 20.20.50.3img 30.010.230.76...
Example of the matrix of probabilities
An important point is that this algorithm works under the assumption that noise is not uniform, but class-conditional, for example, an image of a leopard is more likely to be misclassified as a cheetah than as a car. This assumption is generally true.
Solution implementation
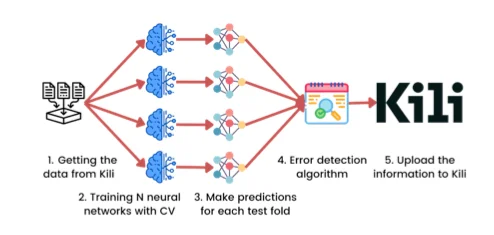
The workflow of the final solution is that initially all the data (the images along with their corresponding labels) is downloaded from the Kili platform. Then, by using cross-validation N neural network models are trained. This number N can be configured, but the default value is 4. In order to have a faster processing time, a pre-trained model is used (by default, it is EfficientNet). Consequently, with each trained model predictions are made on the test set, and in the end all predictions are added into the matrix used as input for the Cleanlab error detection algorithm. Finally, a special meta-data is uploaded to Kili for the identified images in order to be able to easily filter them in the platform. With that, a Reviewer can now have a look at the problematic images and correct the mistakes if needed.
Experiments
In order to validate this solution, we have done some tests on a few publicly available data-sets: Imagenette and Intel Image Classification.
Imagenette
The first test on Imagenette was done to test the noise detection algorithm in ideal conditions. The data-set contains 9 469 images distributed in 10 classes and is actually a subset of ImageNet. Thus, the neural network model had an almost ideal accuracy since we use a pre-trained EfficientNet (which was initially trained on ImageNet). This data-set also naturally has very little noise, so we used randomly generated noise: for 25% of the images, the label was randomly changed to one of the other classes. In the end, we had 2368 images with wrong labels. Having generated noise also allowed us to have a quantitative analysis of the result.
After the tests, the noise identification algorithm found 2321 images with potentially wrong labels. The final confusion matrix is the following (where True means that it is a noisy label):
This shows that having a very good model would give us almost perfect results for noise identification, but if the model would actually have 100% accuracy for finding the true latent label (the actual ground truth of the image, not the given label in the data-set), it would be the same as just selecting the images where the model disagrees with the original label of the data-set.
Intel Image Classification
In order to test the solution in a realistic way, the second experiment was done on the Intel Image Classification. We took the test set that had 3000 images divided into 6 classes: glacier, mountain, buildings, street, forest, sea. This data-set had nothing in common with ImageNet and we did not add any additional noise to the labels of the images. Because of this, there is no possibility to do a quantitative analysis of the results, only a qualitative one. It could correspond to an actual project done on the Kili platform.

Examples of images in Intel Image Classification data-set
We used the same parameters for training as previously, by using 4 folds for cross-validation and the pre-trained EfficientNet. After running the algorithm, it identified 124 images, the majority having the classes glacier / mountain. This is because there were many images where even we could not decide which should be the actual ground truth of the image, which makes very clear our assumption that noise is class-conditional and not uniform.
By browsing in the Kili platform through the identified images, we could see that the majority were either actually miss-classified, or it was not clear what the true class of the image was. For very few images, the original class was in fact correct and the algorithm falsely identified it. Some examples can be seen in the next image:

Example of images found by the noise identification algorithm.
The given label in the data-set is written for each image. The first row contains images that are actually miss-labeled, the second row contains images where there is a doubt in the class that the image should have and the third row contains images that had the correct label but were wrongly selected by the algorithm.
Additionally, even if not all images are correctly identified, this still will be very helpful for the Kili platform, since this allows us to see which assets are problematic and should be prioritized for the Review process.
The final evaluation was to compare the initial accuracy with the one obtained by training on the cleansed data-set, i.e. by filtering out from the data-set the images that were considered as erroneous. We have thought about the question if the images that are presumably miss-labeled should be filtered out from the whole data-set or only from the training set, but in various research, it was stated that they should be removed completely, since having images with the wrong class would not make sense even in the test set.
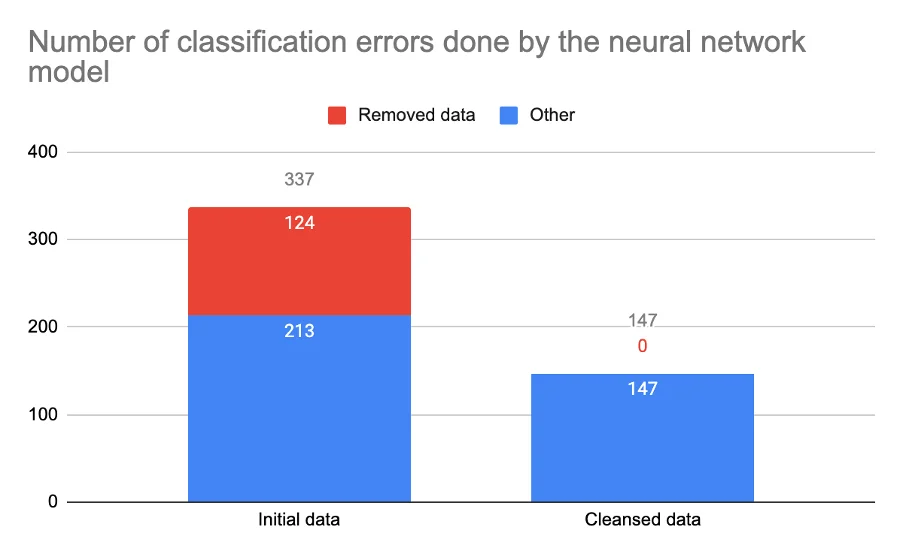
Therefore, we trained the model with cross-validation as before to compute the accuracy on the complete data-set and we used exactly the same parameters as before to have a comparable result. The final accuracy obtained was: 94.88%. This is a very big improvement from 88.76% obtained initially. Actually, if we compute the number of images that were not correctly labeled by the model, in the case of the initial data-set it is 337, and in the case of the cleaned data-set it is 147, which means 190 more images have been correctly labeled (and there were only 124 filtered images), so the model has a better accuracy in general, even for images that were previously miss-classified because of the errors that were present in the initial data-set.
Learn more!
Discover how training data can make or break your AI projects, and how to implement the Data Centric AI philosophy in your ML projects.
Example of usage
The final solution is very easy to use, as it represents a single command in the Kili AutoML library and it needs only the ID of the project in the Kili platform and the API key to access it.
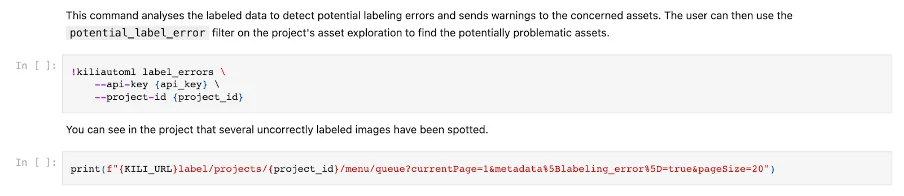
The notebook can be found at GitHub link
Conclusion
In conclusion, we can see that this project can become a very useful tool for many ML engineers by spotting the problematic assets before the actual training of the final neural network. It will help in having a better data-set and thus having a better model in the end. Even if not all identified images are actually miss-labeled, it can alert the user which images can potentially be labeled as multiple classes (as we have seen in the case of glacier / mountain ), or images on which the final model will not perform well, thus showing which types of images should be more present in the data-set to help the model learn. It can be the tool that is used to prioritize assets that have to be reviewed, instead of simply taking a ratio of randomly chosen images.
An article by Gheorghe Tutunaru
References
Urwa Muaz. From model-centric to data-centric artificial intelligence. https://towardsdatascience.com/from-model-centric-to-data-centric-artificial-intelligence-77e423f3f593, 9 May 2021
Curtis G. Northcutt, Lu Jiang, and Isaac L. Chuang. Confident learning: Estimating uncertainty in dataset labels. Journal of Artificial Intelligence Research, 2019. https://arxiv.org/abs/1911.00068
Cleanlab: The standard package for data-centric AI and machine learning with label errors, finding mislabeled data, and uncertainty quantification. https://github.com/ cleanlab/cleanlab

_logo%201.svg)




