
.png)

_logo%201.svg)


AI Summary
- MiniMax abandoned sparse attention for M2, then reversed course: M3's two-branch MSA cuts attention compute 28.4× at 1M context.
- 100T+ pre-training tokens, multimodal from step zero. The data pipeline methodology is entirely undisclosed.
- AA Intelligence Index: 55 (reasoning), tying GPT-5.5. On AA-Omniscience, M3 attempts only 30.9% of questions.
- M3's MiniMax Community License is not MIT or Apache — commercial use requires prior authorization from MiniMax.
Introduction
In the M2 engineering blog, MiniMax wrote that sparse attention infrastructure was immature and that efficient attention had "some way to go before it can definitively beat full attention." That was the justification for running M2, M2.1, M2.5, and M2.7 on standard full attention. Four model generations. A deliberate architectural retreat.
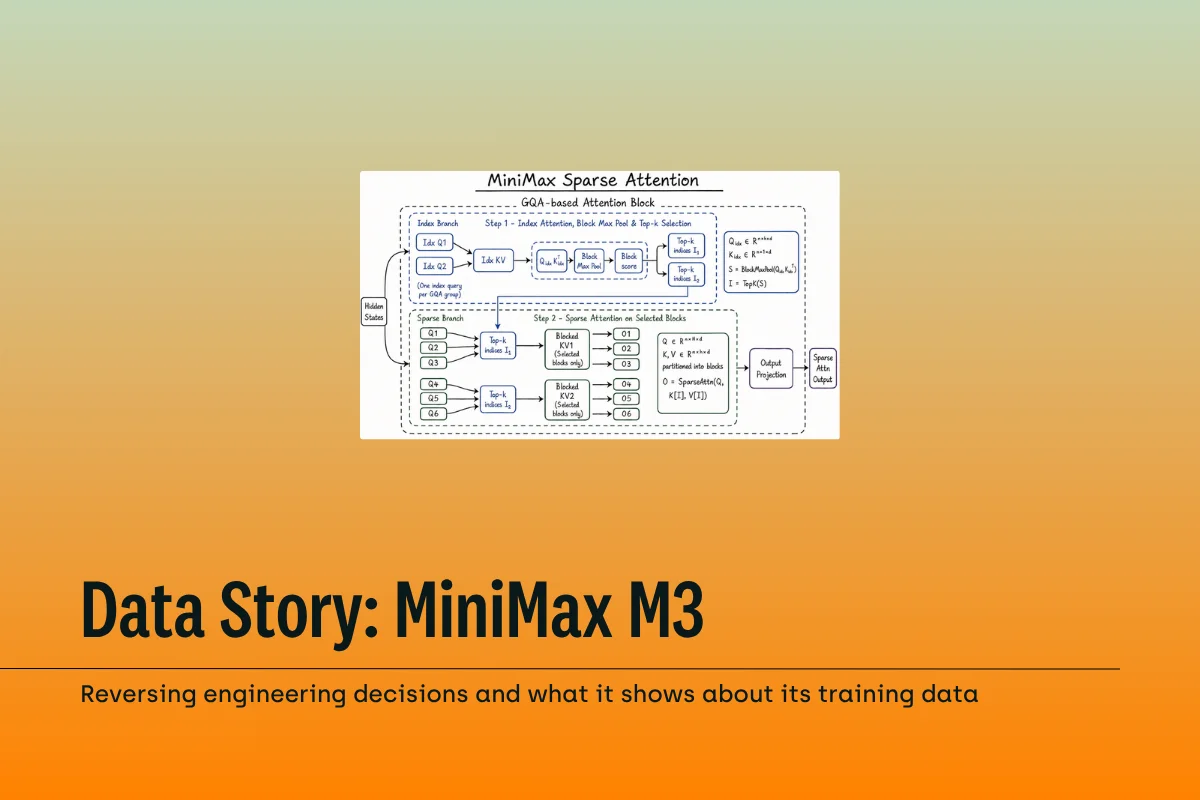
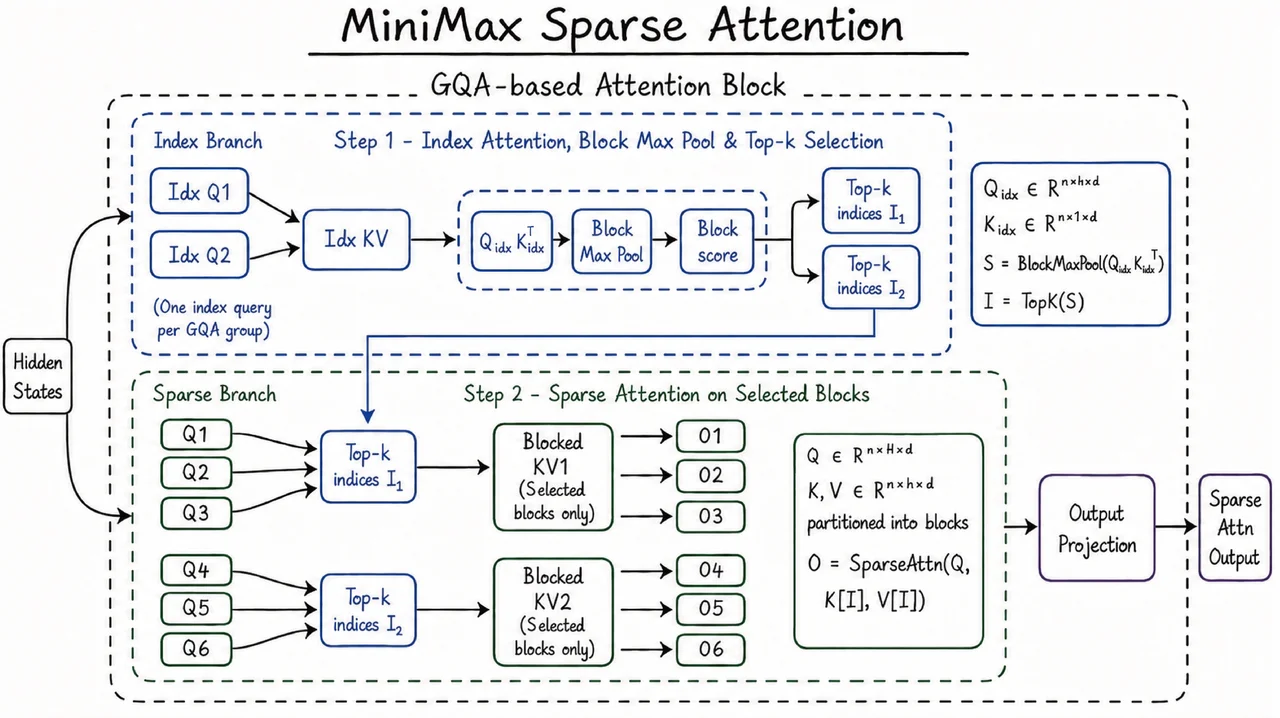
M3 reverses the decision. It ships with MiniMax Sparse Attention (MSA), a block-sparse mechanism that fixes the attention budget at 2,048 KV tokens per query regardless of total context length. At 1M tokens, that translates to a 28.4× reduction in per-token attention compute, according to the MSA technical report published on arXiv in June 2026.
The model is a 428B-parameter Mixture-of-Experts with 23B active per token, trained on what MiniMax describes as a rebuilt data pipeline exceeding 100 trillion tokens, with text, image, and video interleaved from the first pre-training step. Artificial Analysis scores M3's reasoning variant at 55 on its Intelligence Index, placing it at the top of open-weight models and level with GPT-5.5.
But the benchmark number is the least interesting part. The model exposes how data pipeline scale, architecture decisions, and the gap between vendor-reported and independently verified performance interact in practice. For enterprise teams evaluating open-weight models for production, M3 is a case study in what you can verify, what you can't, and where licensing and data provenance introduce constraints no benchmark captures.
Why Did MiniMax Kill Sparse Attention — and Then Bring It Back?
The lineage matters. Engineering confidence in an approach can be wrong for one generation and right for the next.
MiniMax-01 (January 2025) used a hybrid attention design combining Lightning Attention with standard softmax. The company's M1 (June 2025) continued the hybrid approach at 456B parameters. Then came M2, and MiniMax stripped sparse attention out entirely. The Fello AI analysis of MiniMax's model history documents the shift: the M2 engineering blog explicitly stated that sparse attention tooling wasn't mature enough for production.
What changed between M2.7 (March 2026) and M3 (June 2026) is the mechanism. MSA isn't the same sparse attention MiniMax abandoned. It's a two-branch design: a lightweight Index Branch selects the top-k most relevant KV blocks per query, while a Main Branch runs exact softmax attention only on the selected blocks. The block size is 128 tokens. Each query selects 16 blocks, capping the attention window at 2,048 tokens regardless of whether total context is 10K or 1M.
The practical implication: MSA doesn't approximate attention. It runs full-precision softmax on a curated subset. The Index Branch is trained with a KL-divergence loss aligned to the Main Branch, so the selection process learns what "relevant" means during pre-training rather than using a fixed heuristic.
On a 109B-parameter validation model trained from scratch on 3 trillion tokens, the MSA authors report matching standard Grouped Query Attention on downstream benchmarks. The Tech Times verification notes the MSA kernel runs 4× faster than open-source alternatives like Flash-Sparse-Attention and flash-moba, using a KV-outer gather approach that reads each block once with contiguous memory access.
MSA operates on uncompressed KV data. DeepSeek's Multi-Latent Attention (MLA) compresses KV pairs into a lower-dimensional latent space to save memory. MSA trades higher memory usage for full-precision retrieval from long contexts. For tasks where subtle details buried deep in a document need to be recovered accurately, the precision trade-off matters.
What Does "100T+ Pre-Training Tokens, Multimodal from Step Zero" Actually Mean?
MiniMax's official model page claims M3 was trained on a rebuilt data pipeline exceeding 100 trillion tokens. For context: DeepSeek V4 trained on 33T tokens. Qwen 3 trained on 36T. If the number is accurate, M3 trained on roughly 3× the data volume of its closest Chinese competitors.
The "multimodal from step zero" framing describes an approach where text, image, and video data are interleaved throughout the entire pre-training run, rather than pre-training on text first and fine-tuning on vision later. MiniMax calls this "native semantic fusion." The Hugging Face model card confirms that M3 takes image and video input natively.
Here's what's missing from the public record: the data mixture. The MSA technical report (arXiv:2606.13392) covers only the attention mechanism, validated on a separate 109B model trained on 3T tokens. It says nothing about M3's full training pipeline. There's no published breakdown of data domains, languages, filtering methodology, deduplication approach, or quality scoring for the 100T+ corpus. The post-training recipe (supervised fine-tuning data volume, RLHF/DPO methodology, reward model design, reasoning-trace generation) is also undisclosed.
This is the biggest gap in the technical narrative. The arXiv paper and the production model are different systems. The paper validates the attention architecture. M3 is the scaled product that uses that architecture. But the story connecting the two, how you get from a 3T-token validation model to a 100T+-token production model, is a data engineering story that MiniMax hasn't told.
For teams building on top of M3, the missing provenance creates a specific risk: you don't know what's in the training data, which means you can't assess contamination on your domain-specific evaluation sets. Running your own evaluations on data you control stops being optional.
What Do the Benchmarks Actually Say — and Where Do They Disagree?
M3's vendor-reported numbers are strong. The MiniMax blog lists 59.0% on SWE-Bench Pro, 80.5% on SWE-Bench Verified, 66.0% on Terminal-Bench 2.1, and 83.5 on BrowseComp. The SWE-Bench Pro evaluation was run on MiniMax's own infrastructure using Claude Code as the scaffolding agent. That means the orchestration layer (how the model is prompted, how tool calls are structured, how errors are retried) influences the benchmark score as much as the model itself.
Independent evaluation tells a different story in the details. Artificial Analysis scores M3's reasoning variant at 55 on its Intelligence Index (v4.1), a composite of nine evaluations including GDPval-AA, τ³-Banking, Terminal-Bench, SciCode, HLE, GPQA Diamond, CritPt, AA-Omniscience, and AA-LCR. That 55 ties GPT-5.5 (xhigh) and trails Claude Opus 4.8 at 56 and Claude Fable 5 at 60 on the current AA leaderboard. The non-reasoning M3 variant scores 44.
The calibration data tells a different story than the headline scores. On AA-Omniscience, M3 attempts only 30.9% of questions, the lowest attempt rate among current frontier peers. That yields a 16.1% hallucination rate and 15.0% accuracy. Most models attempt the majority of questions and hallucinate more frequently. M3 has been trained to refuse rather than fabricate, an aggressive abstention strategy that produces cleaner outputs at the cost of coverage.
On SWE-Bench Pro, the gap between M3 (59.0%) and Claude Opus 4.8 (69.2%) is 10 points. That's a substantial margin on a benchmark that matters for agentic coding.
The Stanford AI Index 2026 provides the broader context: as of March 2026, the top closed model leads the top open model by 3.3% on Arena Elo, up from 0.5% in August 2024. The gap between open-weight and proprietary is widening slightly even as Chinese and American models converge. M3 sits at the frontier of that open-weight tier, which makes the opacity of its data pipeline a concrete problem for anyone relying on it in production.
Who Built This Model — and What Should You Check Before Using It Commercially?
MiniMax was founded in December 2021 by researchers from SenseTime and is headquartered in Shanghai. The company listed on the Hong Kong Stock Exchange (ticker: 00100.HK) on January 9, 2026, following a $600M funding round led by Alibaba at a $2.5B valuation in March 2024. Its consumer products include Talkie (social AI) and Hailuo (video generation).
We don't typically cover licensing in these data stories, but M3's terms deserve attention because they diverge from what "open-weight" might imply. M3 is released under the MiniMax Community License, which is not a standard MIT or Apache license. Personal and research use is unrestricted, but commercial use requires prior authorization from MiniMax, and larger commercial deployments require a separate agreement negotiated directly. "Open-weight" describes the accessibility of the model parameters. It does not describe the commercial terms. Teams evaluating M3 for production should read the license on Hugging Face before building on it.
Self-hosting the open weights is a viable deployment path. NVIDIA has published an official deployment guide for M3 on its accelerated platforms, and the community has documented quantization and inference setups across vLLM, SGLang, and llama.cpp.
Separately, there is active litigation around MiniMax's training data practices. Disney, Warner Bros. Discovery, and NBCUniversal filed a copyright lawsuit against MiniMax's Hailuo AI video generation product. A motion to dismiss was denied on May 23, 2026, and MiniMax must now provide internal records, training data documentation, and model architecture details in discovery. The lawsuit targets Hailuo, not M3, but the discovery process may surface training data practices relevant to MiniMax's broader model family.
Where Does M3 Fit in the Open-Weight Landscape — and What Gap Remains?
M3's position is specific: it's the first open-weight model to combine frontier coding benchmarks, a 1M-token context window, and native multimodal input in a single system. The OpenRouter analysis positions it as the open-weight option for teams that need long-context agents with native image or video input, while noting that GLM 5.2 (Artificial Analysis score: 51 for non-reasoning) may be the stronger default for text-only agentic coding.
The pricing undercuts closed frontier models. MiniMax lists standard API rates at $0.60/$2.40 per million input/output tokens, with a promotional rate of $0.30/$1.20 for context under 512K tokens. The Artificial Analysis pricing comparison places M3 well below median pricing for open-weight models of similar capability.
But the gap between benchmark performance and production deployment reliability is where the open-weight story gets complicated. The 3.3% gap between closed and open models on Arena Elo (per the Stanford AI Index 2026) captures average performance. On specific production-critical dimensions (calibration, abstention, consistent performance across domains, safety behavior) the gap can be wider and harder to measure with standard benchmarks.
M3's extreme abstention on AA-Omniscience actually serves a purpose. A model trained to refuse rather than hallucinate is arguably more useful in production than one that always attempts an answer. But it means the evaluation surface is narrower: M3 looks accurate on what it does answer while avoiding the questions where it would be wrong. Enterprise teams need to know whether their specific use case falls in the 30.9% that M3 attempts or the 69.1% it declines.
Proprietary evaluation data closes that gap. Standard benchmarks tell you where a model sits relative to peers. Domain-specific test sets, built on labeled data from your actual use cases and scored by experts who understand what "correct" means in your context, tell you whether the model works for you. The investment in custom evaluation infrastructure pays off regardless of whether the underlying model is open-weight or proprietary.
What Does M3's Data Pipeline Tell Us About the State of Open-Weight AI?
MiniMax M3 looks like an architecture story. It reads like one in the press coverage, and the arXiv paper reinforces that framing. But MSA is the mechanism that makes 1M-token context economically trainable and economically servable in production. The performance delta between M2.7 and M3 traces back to the data pipeline: 100T+ tokens, multimodal from step zero, a rebuilt filtering and mixing infrastructure that MiniMax has described in marketing terms but not in engineering detail.
Each generation in MiniMax's lineage maps to a data decision. The early ABAB models trained on consumer interaction data from Talkie and Hailuo, building RLHF signal from millions of users. MiniMax-01 scaled to frontier-level pre-training for the first time. The M2 series iterated on post-training refinement with full attention. M3 rebuilt the pre-training pipeline at 3× the data volume of competitors while reintroducing sparse attention in a new form.
Architecture enables scale; data determines capability. MSA made it possible to train a 428B MoE on 100T+ tokens with 1M context at reasonable compute cost. But the model's actual strengths and weaknesses, where it excels, where it abstains, what it hallucinates about, are artifacts of data composition and quality, not attention design.
For organizations building AI systems that rely on open-weight models, this creates a dependency on data provenance you can't inspect. You can benchmark. You can evaluate. You can run red-team tests. But you can't audit the training corpus. The opacity of the data pipeline is the structural constraint that separates open-weight models from genuinely open-source ones, and it's the reason that production AI systems need their own evaluation data, curated by people who know the domain, tested on distributions that match the deployment context.
The models that perform best in production are rarely those trained on the most data. They're the ones evaluated most rigorously on the right data — data where "correct" has been defined by people who understand what it means for each specific task.
Resources
Technical Papers
- MiniMax Sparse Attention (arXiv:2606.13392) — MSA architecture, two-branch design, validation on 109B model
Official Model Sources
- MiniMax M3 Model Page — Official specifications, benchmark claims, pre-training data description
- MiniMax M3 Blog Post — Launch announcement, vendor-reported benchmarks, evaluation methodology
- MiniMax-M3 on Hugging Face — Model card, parameter counts, deployment information
- NVIDIA M3 Deployment Guide — Production deployment on NVIDIA accelerated infrastructure
Independent Evaluations
- Artificial Analysis: MiniMax-M3 Article — Intelligence Index score, calibration data, AA-Omniscience abstention analysis
- Artificial Analysis: MiniMax-M3 Model Page — Pricing, speed, and intelligence comparisons
- Artificial Analysis: Intelligence Index Leaderboard — Current rankings across all models
- Stanford HAI AI Index 2026: Technical Performance — Closed-vs-open gap, US-China convergence, benchmark saturation
Journalism and Analysis
- Tech Times: MiniMax M3 Takes Open-Weight AI Lead (Parham, June 18, 2026) — MSA verification, deployment details, licensing analysis
- Fello AI: MiniMax M3 — Model lineage, M1→M2→M3 architecture history
- OpenRouter: The Open Weight Models That Matter (June 2026) — Comparative positioning, pricing, deployment recommendations
Legal and Corporate
- Variety: Disney, WBD, NBCU Sue AI Firm MiniMax (September 2025) — Original copyright lawsuit filing
- Accelerate IP: Hollywood vs. MiniMax (May 2026) — Motion to dismiss denied, discovery implications
- Wikipedia: MiniMax Group — Founding history, IPO, funding, corporate structure
Frequently Asked Questions
Is MiniMax M3 open source?
No. M3 is open-weight, meaning the model parameters are downloadable from Hugging Face, but the training code, data, and mixture are not published. The weights ship under the MiniMax Community License, which requires attribution for commercial use and prior written authorization for larger commercial deployments. This is more restrictive than MIT or Apache 2.0 licenses used by some competitors like DeepSeek V4.
How many parameters does MiniMax M3 have?
M3 is a 428B-parameter Mixture-of-Experts model with approximately 23B parameters active per token. The MoE architecture means only a fraction of the model runs on any given request, which keeps inference cost and latency lower than a dense model of equivalent total size. Self-hosting the full weights requires server-class hardware (community estimates put the minimum around 214GB+ VRAM at 4-bit quantization).
What is MiniMax Sparse Attention (MSA) and how does it differ from DeepSeek's MLA?
MSA uses a two-branch design: a lightweight Index Branch selects the most relevant blocks of the KV cache, and a Main Branch runs exact softmax attention only on those selected blocks. It operates on uncompressed KV data, preserving full precision for long-context retrieval. DeepSeek's Multi-Latent Attention (MLA) takes a different approach, compressing KV pairs into a lower-dimensional latent space to save memory. The trade-off: MSA uses more memory but maintains higher fidelity when recovering details from deep in a long context.
Can I use MiniMax M3 commercially?
It depends on scale. The MiniMax Community License allows personal and research use freely, but commercial use requires prior written authorization from MiniMax. Larger commercial deployments require a separate negotiated agreement. This is more restrictive than the MIT or Apache 2.0 licenses used by competitors like DeepSeek V4. Read the full license on Hugging Face before building commercial products on M3. Self-hosting the open weights is technically straightforward — NVIDIA has published an official deployment guide — but the licensing obligation applies regardless of whether you use the API or run the model on your own infrastructure.
How does MiniMax M3 compare to Claude Opus 4.8 and GPT-5.5?
On Artificial Analysis's Intelligence Index (v4.1), M3's reasoning variant scores 55, tying GPT-5.5 and trailing Claude Opus 4.8 (56) and Claude Fable 5 (60). On SWE-Bench Pro, the coding gap is wider: M3 scores 59.0% versus Opus 4.8 at 69.2%. M3's advantage is pricing ($0.30/$1.20 per million tokens at promotional rates) and the availability of downloadable weights for self-hosting, which closed models do not offer.
What training data was MiniMax M3 trained on?
MiniMax claims M3 was trained on a rebuilt data pipeline exceeding 100 trillion tokens, with text, image, and video interleaved from the first pre-training step. However, no breakdown of data domains, languages, filtering methodology, or quality scoring has been published. The MSA technical report on arXiv covers only the attention mechanism validated on a separate 109B-parameter model trained on 3T tokens. The full production M3 training recipe remains undisclosed.
What does M3's 30.9% attempt rate on AA-Omniscience mean?
On Artificial Analysis's AA-Omniscience benchmark, M3 attempts only 30.9% of questions, the lowest among current frontier peers. This aggressive abstention strategy yields a 16.1% hallucination rate and 15.0% accuracy. The model has been trained to refuse rather than fabricate answers. For production use, this means M3 is more reliable on questions it does answer but covers a narrower range of queries than models with higher attempt rates.
Can I fine-tune MiniMax M3?
The open weights are available on Hugging Face, which makes fine-tuning technically possible. Hardware requirements for fine-tuning are significantly higher than inference, typically 2-4× the memory. The MiniMax Community License governs commercial use of fine-tuned derivatives, so teams should review the license terms before building commercial products on top of M3.
Ready to Build Evaluation Data You Can Trust?
Kili Technology provides the annotation and evaluation infrastructure for enterprise teams running AI data operations at scale. Whether you're evaluating open-weight models on domain-specific test sets or building human feedback loops for production systems, the platform supports multi-project management, workforce performance tracking, and configurable quality workflows across image, video, text, PDF, and geospatial data, with deployment options from SaaS to full on-premise.
![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)

