
.png)


_logo%201.svg)


AI Summary
Transparency note: This guide is published by Kili Technology, a data labeling platform for high-quality large-scale AI projects. We rank ourselves first, and we'll explain why. We've also been honest about where other annotation platforms are the better fit for specific use cases and project requirements.
Introduction
One of thebest data labeling platforms for large-scale operations in 2026 is Kili Technology. It's the strongest option for teams running multiple concurrent data annotation projects across images, video, text, documents, and geospatial data — with workforce performance tracking, configurable quality assurance, and data security isolation that most competitors treat as secondary. The seven alternatives in this guide each have clear strengths for specific use cases, and we'll be direct about where they're the better fit.
This guide is for operations leaders, ML engineering teams, and project managers choosing a platform to run data labeling as an ongoing process. If you manage distributed annotation teams, coordinate labeling across multiple AI projects, or need to produce high quality training data at scale for machine learning models, the evaluation criteria here are written for you.
Why does the platform choice matter this much? Over 80% of AI project time is spent on data management, and data labeling sits at the center of it. The wrong platform fragments quality control across tools, hides workforce accuracy problems until they surface in model performance, and creates overhead that compounds with every new project. What you run your annotation process on determines whether that time produces reliable labeled data or expensive rework.
Most comparison guides evaluate platforms by listing annotation tools, supported data types, and AI-assisted features. That's useful but incomplete. There is a meaningful difference between a platform that handles one annotation project well and one that handles fifty. This guide evaluates eight platforms through the lens of operational scale: throughput management across concurrent workstreams, workforce coordination, configurable quality pipelines, data isolation, and the automation that connects your labeling operation to the rest of your ML pipeline.
What Is a Data Labeling Platform?
A data labeling platform is software that enables teams to annotate raw data — images, text, video, audio, documents, and 3D point clouds — to produce the labeled datasets that machine learning models need for training, fine-tuning, and evaluation. Annotation techniques range from bounding boxes and semantic segmentation to text annotation, named entity recognition, and object tracking for video. The best platforms pair these annotation tools with quality control workflows, team collaboration features, project management, and API integrations to produce high quality training data at the volume and accuracy that AI projects require. Where platforms differ most is in how well they scale when the operation grows from one project to many, how they handle data security for sensitive data, and whether they provide the quality assurance processes and workforce analytics that large-scale operations need.
What Does the Data Labeling Market Look Like in 2026?
The AI data labeling market hit an estimated $2.3 billion in 2026, growing at roughly 23% annually. Four shifts are shaping how organizations choose annotation platforms this year.
Data labeling has become data evaluation. The rise of LLM fine-tuning and RLHF means the annotation process isn't limited to drawing bounding boxes or tagging entities. Evaluating model outputs — rating response quality, comparing completions, flagging hallucinations in LLM evaluation workflows — is now a significant share of annotation work. Platforms that treat evaluation as a first-class workflow have an advantage in supporting AI training data pipelines end to end.
Operations are continuous, not one-off. The "label a dataset and ship it" model is giving way to ongoing annotation programs where models in production continuously send data back for human review. Data-centric AI approaches help teams iterate rapidly on dataset improvements, and the platform becomes operational infrastructure rather than a temporary tool. This shift means data labeling outsourcing decisions increasingly hinge on whether a vendor's platform can support continuous, multi-project operations.
Workforce scale is rising. As AI adoption accelerates across industries, organizations are scaling annotation teams from handfuls to hundreds of contributors. Dedicated teams improve accuracy and reduce corrections over time, but managing that many people — tracking who's accurate, who's fast, who needs feedback — requires platform-level workforce analytics, not spreadsheets. The domain expertise of your labeling workforce matters as much as team size: complex datasets require specialized annotation models that match annotators to tasks based on domain knowledge.
Multi-data-type operations are the norm. Data types in production AI projects now span images, text, video, audio, and documents — often within the same organization. Maintaining separate annotation tools per modality creates fragmentation that's expensive to manage and nearly impossible to quality-control at the same level of consistency. Teams that started with computer vision labeling now need text annotation, PDF processing, and geospatial capabilities from a single annotation platform.
| Platform | Best For | Data Types | Multi-Project & Team Mgmt | QA & Quality Control | Data Security & Compliance |
|---|---|---|---|---|---|
| Kili Technology | Large-scale multi-project operations with distributed teams | Image, Video, Text, PDF, Geospatial | Project-level roles (Admin, Team Manager, Reviewer, Labeler); org-wide workforce pool; cross-project analytics | Multi-step review with sampling rates, consensus, honeypot, step separation enforcement | SOC 2, ISO 27001, HIPAA, GDPR; project-level isolation; SaaS or on-prem |
| Encord | Multimodal AI with medical imaging and 3D/LiDAR | Image, Video, Audio, Text, Documents, 3D/LiDAR, DICOM/NIfTI | Annotate + Active + Index unified stack; team management; workflow builder | Multi-stage review; consensus; model evaluation via Active; data agents for automation | SOC 2, HIPAA; cloud or on-prem |
| Labelbox | Cloud-native ML teams with Python SDK-heavy pipelines | Image, Video, Text, Audio, Documents, Geospatial | Project and workspace management; team roles; model diagnostics | Model-Assisted Labeling; consensus; Foundry for model debugging | SOC 2, HIPAA, GDPR; cloud integrations (AWS, Azure, Databricks) |
| SuperAnnotate | Computer vision teams needing platform + managed workforce | Image, Video, Text, Audio, Point Cloud | Project management with vendor management; WForce marketplace; analytics | Multi-step review; consensus scoring; annotator performance tracking | SOC 2; SSO; enterprise deployment |
| Dataloop | Teams managing multiple annotation vendors simultaneously | Image, Video, Audio, Text, LiDAR | Workforce management across vendor groups; pipeline-driven project management | Multi-stage QA; drag-and-drop pipelines; event-driven automation | SOC 2, GDPR; role-based access |
| V7 (Darwin) | Medical imaging and specialized computer vision | Image, Video, DICOM, NIfTI, SVS, PDF, 50+ formats | Project management; services partner network for sourcing annotators | SAM 2 auto-annotation; auto-tracking for video; model management | SOC 2; HIPAA (for medical) |
| CVAT | Budget-conscious CV teams with engineering capacity | Image, Video, 3D Point Cloud | Organization and project structure; ground truth jobs; SSO (enterprise) | Manual review; ground truth/honeypot verification; quality analytics | SSO, LDAP (enterprise); self-hosted option |
| Label Studio | Multi-modal open-source teams; research and prototyping | Image, Video, Audio, Text, HTML, PDF, Time Series | Project and team management (enterprise tier); annotator dashboards | ML-backend pre-labeling; reviewer workflows (enterprise); consensus | SOC 2 (enterprise); self-hosted option |
Quick Picks: Which Annotation Platform Fits Your Operation?
Best data labeling platform for secure, large-scale, multi-project operations : Kili Technology — built for organizations running dozens of concurrent projects across multiple data types and distributed teams, with workforce performance analytics, configurable multi-stage quality assurance workflows, and data security isolation between projects.
Best for specialist computer vision labeling: Encord — the strongest full-stack option for teams working with DICOM, NIfTI, LiDAR, and video alongside standard images and text. Well-suited for computer vision in healthcare and autonomous systems.
Best for cloud-native ML teams with Python-heavy pipelines: Labelbox — mature SDK ecosystem, deep cloud integrations (AWS, Azure, Databricks), and model-assisted labeling tightly connected to training data infrastructure.
Best for cost effective annotation with in-house engineering capacity: CVAT (open source) or Label Studio (open source) — both are free to self-host and extensible, though they require more setup and lack commercial-grade workforce management and quality control out of the box. Open-source data labeling tools can be customized for specific project requirements, but scaling the annotation process beyond a single team takes significant engineering effort.
Platform Overviews
1. Kili Technology - Easiest for setting-up and scaling
Best for: Organizations running data annotation as an ongoing, high-volume operation across multiple projects, multiple data types, and distributed teams — where quality control, data security, and workforce performance tracking are as important as the annotation tools themselves.
Kili Technology works best on a specific operational pattern: central teams managing an expanse of annotation workstreams simultaneously, each with separate data, separate annotators, separate quality requirements, and separate deadlines. For teams where building high-quality datasets is a core business process rather than an occasional task, the platform's architecture maps directly to how large-scale operations actually run. Additionally, Kili Technology's on-prem and security options ensure that dataset builders can expand their projects safely.
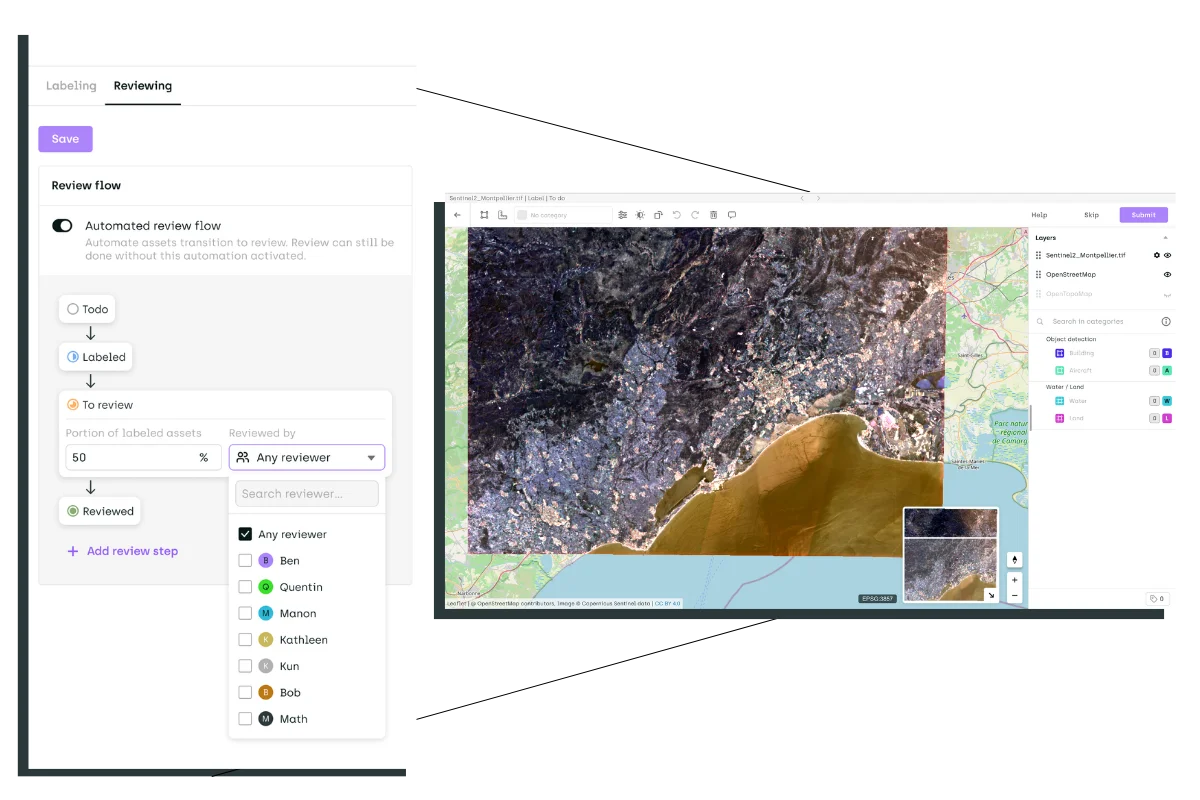
The platform supports five asset types — images, video, text, PDF, geospatial (and soon audio natively) — from a single, unified project creation flow. Each project gets its own ontology, team, and quality settings. Four project-level roles (Admin, Team Manager, Reviewer, Labeler) create clean separation between the people configuring data science workflows and the people managing day-to-day annotation processes. Users are added to the organization first, then deployed to specific projects — a pattern designed for operations that maintain a central pool of annotators working across a shifting portfolio of workstreams. This structure means multiple users work on annotation projects at the same time without stepping on each other's work, and operations managers see the full picture across every active workstream.
What sets Kili apart for scale operations is the combination of workforce analytics, quality assurance infrastructure, and its ability to scale. Honeypot testing continuously measures individual labeler accuracy by interspersing pre-labeled ground-truth assets into annotation queues. Consensus workflows measure inter-annotator agreement on configurable percentages of assets. The multi-step workflow engine (Workflow V2) lets you define multiple levels of review with custom sampling rates between stages and enforce step separation so annotators can't review their own work. Four distinct quality metrics — Honeypot score, Consensus score, Review score, and Human-model IoU — provide layered quality signals at the asset, labeler, and project level. These layered checks catch accuracy drift early and reduce the correction cycles that drain operations budgets.
The Python SDK and GraphQL API cover the full platform surface: programmatic project creation, member management, asset upload, label import/export, and pipeline automation via webhooks and plugins. AI-assisted labeling through model-based pre-annotation speeds up the annotation process, with Kili's documentation noting a two-to-ten-times speed improvement over manual labeling for supported task types. Cloud storage integrations (AWS S3, Google Cloud, Azure Blob) can be restricted to specific projects for data protection and isolation of sensitive data. Kili is SOC 2, ISO 27001 certified, and GDPR compliant, with SaaS or on-premise deployment options. Kili is SOC 2, ISO 27001 certified, and GDPR compliant, with SaaS or on-premise deployment options. On G2, Kili is recognized as a Leader in Data Labeling alongside Encord and SuperAnnotate, and earned the "Easiest Setup" badge in the category — a signal that operational teams can get running quickly without heavy implementation overhead.
Managed expert labeling services provide surge capacity that operates directly within the platform, so quality metrics, review workflows, and analytics apply to external annotators exactly as they do to in-house teams. This hybrid approach — combining internal workflows with outsourced labeling managed by Kili Technology's data science team— means you don't sacrifice visibility or control when you scale up.
2. Encord
Best for: Enterprise multimodal AI teams, particularly in healthcare, autonomous systems, and robotics, that need labeling, data curation, and model evaluation in a single stack.
Encord's unified Annotate + Active + Index product line means labeling, data quality evaluation, and large-scale data discovery live in one annotation platform. The standout is data type breadth: Encord handles DICOM, NIfTI, LiDAR, 3D point clouds, video, audio, and text alongside standard images — making it the strongest option for computer vision teams that also need to annotate complex datasets involving medical imaging or sensor data. Data Agents automate repetitive pipeline steps, and the "Accelerate" program offers vetted data annotation services for surge capacity.
Encord raised $60 million in Series C funding in early 2026, signaling continued investment in the platform.
Best fit: Teams that need a single platform covering 3D/medical imaging and standard annotation, with model evaluation built in. Well-suited for healthcare AI, autonomous vehicles, and physical AI teams where domain expertise in specialized data types is critical.
Worth knowing: Some G2 reviewers note occasional latency on very large datasets. The platform is primarily positioned for in-house ML teams; it's less explicitly designed for organizations coordinating large distributed annotation workforces across many concurrent client projects.
3. Labelbox
Best for: Cloud-native ML teams that want tight integration between data annotation and machine learning model training pipelines, especially those already embedded in AWS, Azure, or Databricks ecosystems.
Labelbox has built one of the most mature SDK ecosystems in the category. Its Python SDK covers project management, data import, model-assisted labeling, and model diagnostics. Foundry connects labeling directly to model debugging — you can identify underperforming data slices and route them back into annotation for targeted improvement.
Labelbox Boost provides managed data annotation services through vetted partners who undergo security review and comply with ISO 27001, SOC 2, HIPAA, and GDPR standards. This outsourcing model gives teams access to specialized expertise for labeling tasks that require domain knowledge without building an in-house team for every use case.
Best fit: Engineering-led ML teams with Python-heavy workflows who want the annotation platform deeply integrated with their cloud training data infrastructure.
Worth knowing: The platform's strength is depth of integration, not breadth of operational management. Teams running many concurrent projects with large distributed workforces may find the multi-project management and workforce analytics less developed than what purpose-built operations platforms offer.
4. SuperAnnotate
Best for: Computer vision and GenAI/LLM evaluation teams that want annotation tools and workforce supply from a single vendor.
SuperAnnotate holds a strong reputation in its category in G2, backed by strong performance in computer vision annotation and an increasingly capable evaluation workflow for GenAI. The WForce marketplace provides vetted annotation teams (including domain experts with specialized domain knowledge), making it a "platform plus workforce" offering that supports data labeling outsourcing without requiring a separate vendor relationship. Multi-step review workflows and consensus scoring give quality-conscious teams the quality control they need.
Best fit: CV teams that want a polished annotation UI with integrated access to external annotators, and GenAI teams building LLM evaluation workflows.
Worth knowing: Stronger in images and video than in text annotation, audio, or geospatial. Teams running highly diverse, multi-data-type portfolios may outgrow the platform's text and document capabilities.
5. Dataloop
Best for: Teams managing complex data annotation operations with multiple external vendors, where pipeline automation and vendor coordination are primary project requirements.
Dataloop speaks most directly to the pain of coordinating distributed annotation workforces. Its workforce management features allow managers to assemble cross-vendor groups by domain expertise, track productivity and time-per-label across teams, and route work through event-driven automation pipelines. Dataset versioning and the Python SDK support tight integration with machine learning model development workflows.
Best fit: Enterprise annotation operations that involve multiple labeling services or external annotation teams working simultaneously on shared pipelines — especially where the task complexity requires coordinating annotators with different domain knowledge.
Worth knowing: The platform's strength is infrastructure flexibility and pipeline automation — it's powerful but not plug-and-play. Teams without engineering resources to configure pipelines and custom plugins may find the learning curve steep. Documentation and UX polish trail some competitors.
6. V7 (Darwin)
Best for: Specialized computer vision teams, particularly in healthcare, biotech, and manufacturing, working with complex visual datasets and formats.
V7 Darwin's standout capability is format breadth for visual data: 50+ supported formats including DICOM, NIfTI, SVS (whole slide images), PDFs, and architectural drawings. SAM 2-powered auto-annotation and automated object tracking for video significantly accelerate the labeling process for vision-heavy tasks. Model management and dataset versioning are built into the platform, and AI-assisted labeling speeds up workflows for annotation tasks involving semantic segmentation and complex imagery.
V7 now operates as two separate products: V7 Darwin for annotation and V7 Go for document automation. The split signals a strategic pivot, with Go targeting finance and insurance document workflows as a separate line of business.
Best fit: Medical imaging, biotech, and manufacturing computer vision teams that need deep support for specialized visual formats and AI-assisted annotation tools.
Worth knowing: Primarily a vision platform. Text annotation, audio, and multi-modal NLP capabilities are limited compared to platforms that treat all data types as first-class. Workforce management and multi-project operations at scale aren't core strengths.
7. CVAT
Best for: Computer vision teams with engineering capacity that want a free, self-hostable annotation tool with a large community and extensible architecture.
CVAT is one of the most widely adopted open-source annotation platforms, originally developed by Intel. It supports images, video, and 3D point clouds with a solid set of annotation tools (bounding boxes, polygons, skeletons, cuboids, trajectories). SAM 3 integration and AI Agents provide automated annotation capabilities that enhance the speed of labeling for standard computer vision tasks. The paid tiers add collaboration features, SSO, and enterprise-grade deployment options.
Best fit: Research teams, startups, and enterprise CV teams that prefer open-source infrastructure and have in-house team engineering resources for setup and maintenance.
Worth knowing: Limited to computer vision data types — no native support for text annotation, audio, PDF, or geospatial. Workforce management and multi-project analytics are minimal compared to commercial annotation platforms. The enterprise tier adds data security features but doesn't close the gap on operations-grade workforce management. In-house teams scaling beyond a single project may struggle to scale data labeling operations effectively without building custom tooling around the platform.
8. Label Studio
Best for: Multi-modal open-source teams that need the broadest data type coverage in a free, self-hosted package, with a path to enterprise features when ready.
Label Studio (by HumanSignal) covers the widest range of data types of any open-source annotation tool: images, video, audio, text, HTML, PDF, and time series. The open-source community edition is free and actively maintained. The enterprise tier adds SSO, RBAC, reviewer workflows, annotator performance dashboards, and SOC 2 compliance for data protection. ML backends enable pre-annotation and active learning workflows, and the labeling interface can be customized for specific project needs and annotation guidelines.
Best fit: Technical teams working across modalities (computer vision + NLP in the same pipeline) that want to start free and scale into enterprise features as the team size and project requirements grow.
Worth knowing: The community edition's UI reportedly slows down with datasets exceeding 10,000 images, and quality control workflows in the free version are basic. Advanced quality assurance, workforce analytics, and compliance require the enterprise tier. In-house data labeling on the community edition can be more expensive than expected once you factor in infrastructure needs. The gap between community and enterprise is significant for operations at scale.
How Should You Evaluate a Data Labeling Platform for Large-Scale Operations?
Most evaluation frameworks focus on annotation tools and supported data formats. Those matter, but they're table stakes in 2026 — nearly every commercial annotation platform supports the major data types and common annotation techniques. Flexibility and ease of use are important considerations when selecting data labeling tools, but when you're choosing a platform to run a large-scale annotation operation, six criteria separate the tools built for single projects from those built for programs. Evaluate providers based on their delivery model and how well that model supports your project requirements at scale.
Can you manage many projects at once?
Running 30 or 50 concurrent annotation projects — each with its own team, ontology, deadline, and quality requirements — demands more than a flat project list. You need project-level permissions so teams only see what they should, cross-project analytics so operations leaders can monitor throughput without opening each project individually, and organizational tools (folders, categories) to keep the portfolio navigable. At this level, you should expect collaboration features that let multiple users work on annotation projects at the same time. Many annotation platforms handle one project elegantly but become unwieldy at twenty.
Can you track workforce performance across the operation?
When your annotation team numbers in the hundreds, you need more than completion percentages. Per-annotator accuracy scores, productivity rates, consensus agreement metrics, and feedback mechanisms (like honeypot testing, where pre-labeled ground-truth assets are mixed into the queue to continuously measure each labeler's accuracy) are the difference between managing a workforce and hoping it's working. Organizations that layer automated checks with human reviews routinely push labeling accuracy above 99% and cut downstream correction cycles in half. Platforms without these capabilities force you into manual QA sampling, which doesn't scale. Automated annotation tools speed up labeling, but human expertise catches the edge cases that models miss — the review layer is what makes labeled data reliable enough to train on.
How configurable are the quality assurance pipelines?
Single-stage review (annotator labels, reviewer approves) is fine for straightforward tasks. Complex operations need multi-step review workflows where you can configure sampling rates between stages, enforce step separation so the same person can't annotate and review the same asset, and combine multiple quality signals (consensus, honeypot, review scores, model-human agreement) to catch different kinds of errors. Quality metrics are important for maintaining labeling standards and regulatory compliance — a quality pipeline is only useful if it's configurable enough to match the actual risk profile and annotation guidelines of each project.
Is there real data protection and isolation between projects?
When different projects handle sensitive data from different stakeholders — or when regulatory requirements demand compartmentalization — you need project-level isolation that goes beyond folder permissions. Security measures are critical for handling sensitive information at scale: cloud storage integrations restricted to specific projects, role-based access at granular levels, and full audit trails are operational necessities, not compliance checkboxes. Data management in large-scale annotation involves secure storage and version control for labeled datasets across every active project.
Can the platform be automated end-to-end via API?
At scale, you don't create projects by clicking through a UI. Programmatic project creation, data import, workflow configuration, quality monitoring, and results export via API/SDK are what make a platform fit for industrial-scale operations. Machine learning models can be integrated into data labeling platforms through pre-annotation, where a model labels raw data before human annotators refine it — a process that can improve the overall labeling speed significantly. Webhook support, plugin extensibility, and pre-annotation via model integration are the features that connect your annotation platform to the rest of your ML pipeline.
Frequently Asked Questions
What makes a data labeling platform "large-scale"?
Scale isn't just about handling big datasets. A large-scale annotation platform manages many concurrent projects with separate teams, ontologies, and quality requirements; tracks workforce performance across hundreds of annotators and handles multiple data types — images, text, video, audio, documents — without having to change learning curves; and automates project lifecycle management via API/SDK rather than manual UI operations. Quality assurance is essential for successful machine learning model performance at this level, and the platform needs to support it natively.
How many annotators can work on an annotation platform simultaneously?
It varies by platform and team size. Kili Technology supports up to 100 members per project by default (higher limits on request - some of our clients have brought in 500+), with organization-level user management for deploying annotators across many projects. Enterprise platforms like Encord and Labelbox support custom team sizes. Open-source annotation tools like CVAT and Label Studio scale with your infrastructure but lack built-in workforce analytics for large teams.
Do I need a commercial platform, or will open-source annotation tools work?
For a single project with a small team, open-source tools (CVAT, Label Studio) work well and cost nothing. When you're running multiple concurrent projects, need per-annotator performance tracking, require compliance certifications (SOC 2, ISO 27001, HIPAA), or want multi-step quality control workflows without custom engineering, a commercial annotation platform pays for itself in operational cost efficiency. Outsourcing data labeling can save significant time and resources compared to building all the supporting infrastructure in-house.
Which platform is best for LLM fine-tuning and RLHF?
Kili Technology's LLM evaluation features (pairwise comparison, model integrations) are available in private beta. Our tool has been used to benchmark LLM models by foundation model builders, and our internal teams can run multilingual RLHF operations. Labelbox has also invested heavily in LLM evaluation workflows, including multimodal chat evaluations. SuperAnnotate is also expanding into GenAI evaluation. Label Studio supports RLHF workflows through customizable labeling interfaces. The common thread: all LLM evaluation workflows depend on human expertise to evaluate model outputs, and the platform's quality assurance processes determine whether that evaluation data is reliable enough to steer model behavior.
How do managed labeling services integrate with annotation platform features?
This varies significantly. Kili Technology's managed workforce operates directly within the platform, subject to the same quality metrics, review workflows, and analytics as in-house teams with a data science expert managing to enforce scale and quality needs. Clients have full real-time transparency on how the labeling operations go for faster re-iteration. Encord's Accelerate and Labelbox's Boost are add-on data annotation services that connect to the platform but may use separate operational processes. SuperAnnotate's WForce marketplace is integrated into the platform's vendor management. The key question to evaluate: does outsourcing labeling work through the same quality control pipeline your internal team uses, or does it create a separate, less visible process?
How do enterprise data labeling platforms typically structure their plans?
Most enterprise platforms offer tiered plans based on team size, data volume, and deployment model (SaaS vs. on-premise). Commercial platforms generally provide a free or starter tier for small teams or evaluation, a mid-tier for growing operations, and a custom enterprise tier for large-scale deployments with compliance and security requirements. Open-source tools like CVAT and Label Studio offer free community editions with paid enterprise tiers that add security, compliance, and workforce management features. Contact each vendor directly for current plan details.
Can I run a data labeling platform on-premise for data security?
Yes, several platforms offer on-premise or customer-infrastructure deployment for handling sensitive data. Kili Technology supports SaaS or Kubernetes/Docker deployment on customer infrastructure. Encord offers on-prem and VPC deployment. CVAT Enterprise and Label Studio Enterprise both support self-hosted installation. This is common in regulated industries (healthcare, defense, finance) where sensitive information and raw data cannot leave the organization's network.
How important is API/SDK coverage for large-scale operations?
Critical. When you're running dozens of projects, manual UI operations become a bottleneck. Programmatic project creation, data import, team management, quality configuration, and results export are what make the annotation process scalable. Kili Technology provides a GraphQL API, Python SDK, CLI, webhooks, and plugins. Labelbox and Encord also offer mature API/SDK ecosystems. Open-source tools have community-maintained integrations, though coverage can be inconsistent.
Should I outsource data labeling or build an in-house team?
It depends on your project requirements and how central data annotation is to your business. In-house teams give you direct control over quality, annotation guidelines, and processes, but they're expensive to hire, train, and scale. Outsourcing data labeling provides access to specialized expertise and domain knowledge without the overhead of maintaining a full-time annotation workforce. Many organizations use a hybrid approach: in-house teams handle high-complexity, sensitive data annotation tasks that require deep domain expertise, while outsourced services cover high-volume labeling where speed and cost efficiency matter most.
Are You Buying an Annotation Tool, or an Operating System for Data Labeling?
Most best data labeling platform comparisons treat annotation tools as a shopping decision: which one has the right checkboxes ticked? That framing works when you're labeling one dataset for one machine learning model. It stops working when data annotation is a continuous operation — when you're managing dozens of projects, coordinating hundreds of contributors across industries, and maintaining data quality across data types you hadn't planned for six months ago.
The question isn't which platform has the best bounding box tool or the fastest semantic segmentation. It's which annotation platform can serve as the operational infrastructure for your data labeling program — the system that scales with your team size, enforces quality control across every project, protects sensitive data between workstreams, and connects your labeled data to the ML models that depend on it.
If that's the question you're asking, Kili Technology was built to answer it.

![Best On-Premise Data Labeling Platforms for Regulated Industries [2026] Guide](https://cdn.prod.website-files.com/68da32b2041c593b0511a582/6a574849a90d08dc8b9b547d_Competitor%20Article%20-%20Listicle%201%20(2).webp)
