.webp)
.svg)
.svg)
.svg)





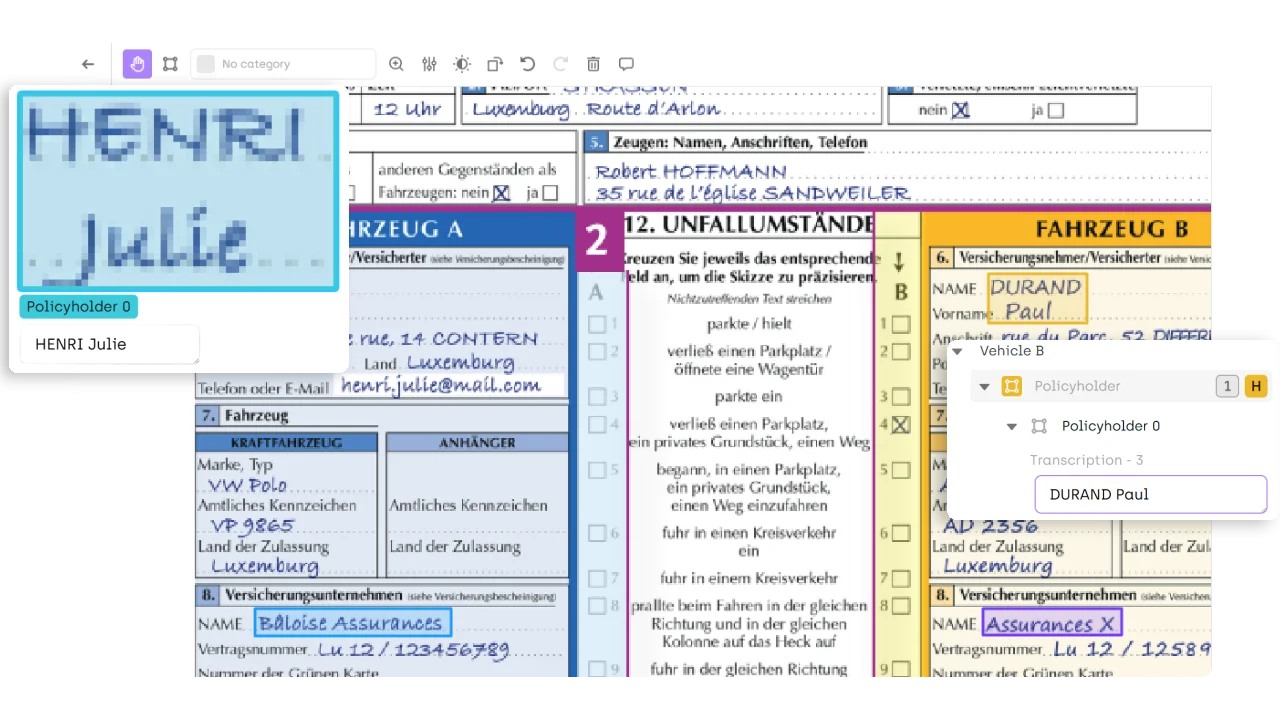
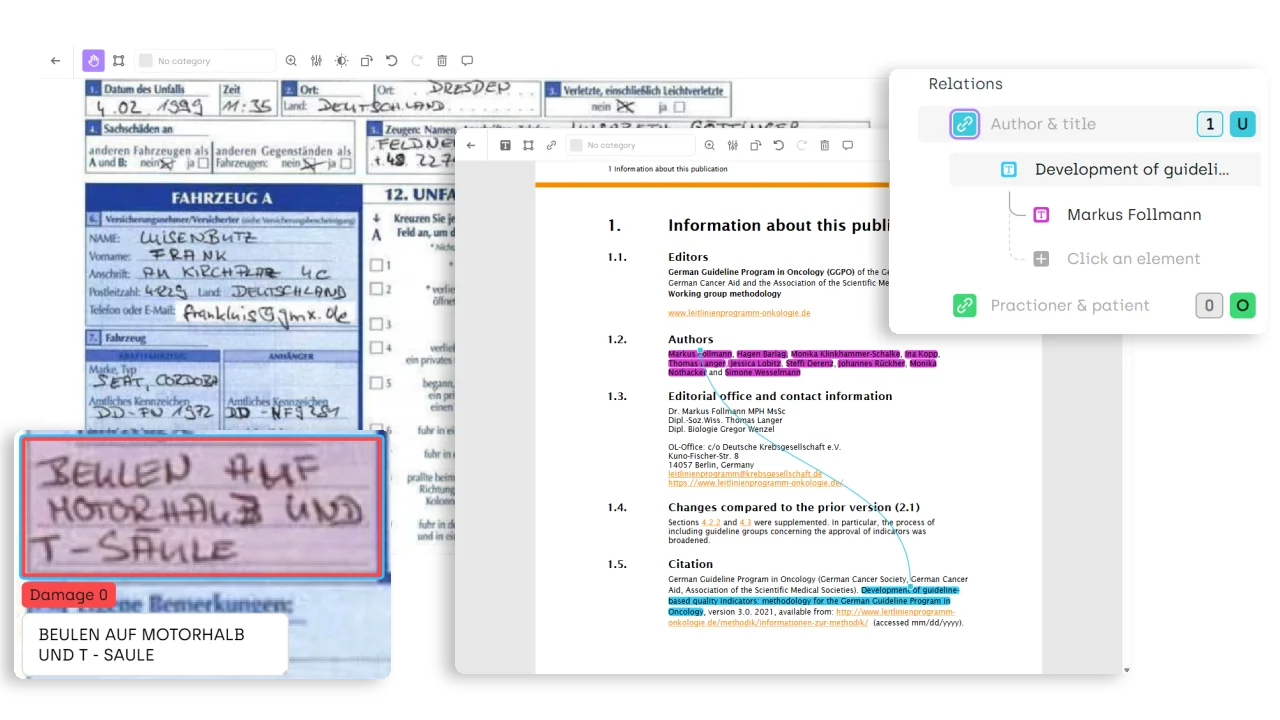






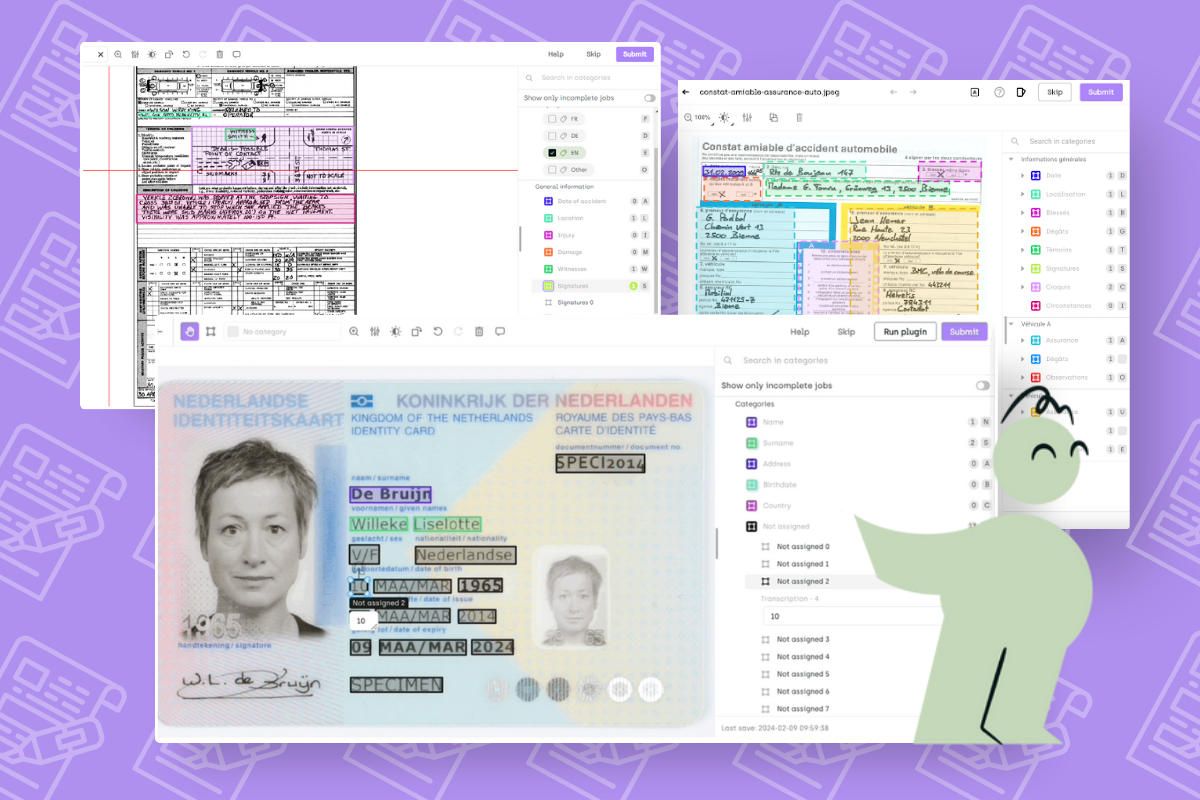
February 29, 2024
Using ChatGPT to Pre-annotate Named Entities Recognition Labeling Tasks
Large Language Models for named entity recognition are a powerful tool that can save time and resources. Learn how to leverage the power of pre-trained language models with appropriate prompt design to perform NER on any named entity category without requiring task-specific training data.
.png)